







一、首先先给出图示,什么叫卷积。(http://deeplearning.stanford.edu/wiki/index.PHP/)
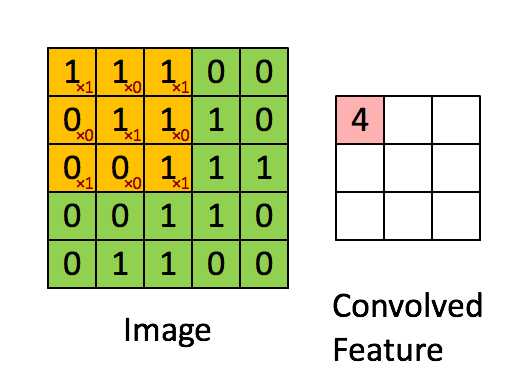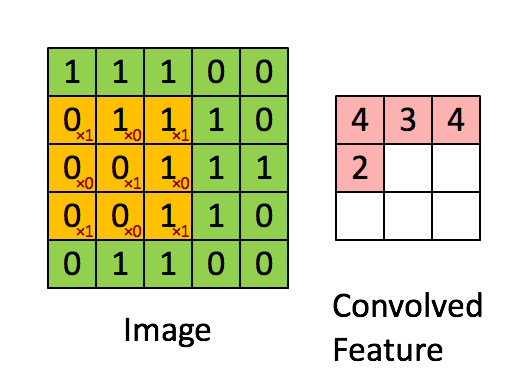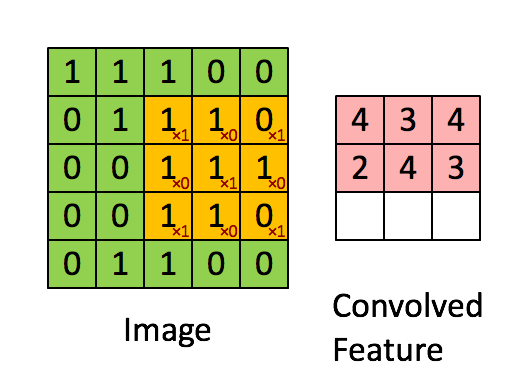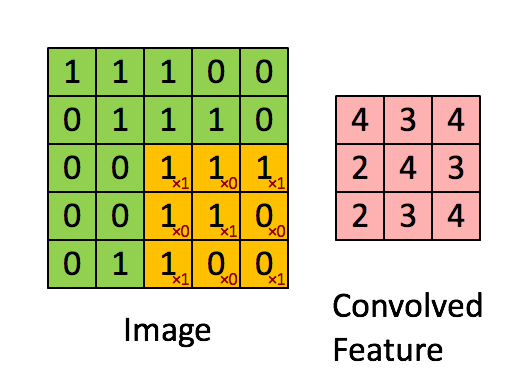
当然很多人会疑问,为什么卷积后的图像会缩小,那是因为在进行图像滤波的时候边缘没有加0进行填充。正常的图像滤波边缘是会填充0,这样滤波出来的图像与原图像的大小保持一致。卷积可以用如下表示式来表示:
训练卷积核的方式(第一种):
当你在监督学习的时候你不用改变它的参数,它的参数时固定的。例如:你想提取人脸的特征,目前你已经有了自己的数据集,想训练9×9的卷积核(滤波器),这时你可以从你的数据集上取任意去9×9的小块,当然你取的小块越多,训练出来的卷积核越鲁棒。下面我按步骤来说明:
(1)取数据集上大量的小块,为训练滤波器做准备,滤波器的大小决定了你取小块的大小。
(2)如果你想得到20张特征图(这里的特征图是指不同的滤波器滤波后的结果图),那么你就需要20种不同的滤波器。那么如何得到这20种滤波器呢,这时你可以采用autoencoder学习,你的输入层为9×9=81个神经元,隐含层为20个神经元(隐含层的神经元个数决定了你滤波器的个数),输出层也为9×9=81个神经元,相当于一个自学习层,也称自监督学习。可以这样表示:输入→编码→解码→输出。这样经过参数学习后,就可以得到输入层到隐含层的参数,隐含层的每个神经元与输入层的81个神经元相连接,每个连接上是有参数的,一共含有81个参数,把81个参数reshape成9×9的参数,这样就得到1个滤波器,20个隐含层神经元分别与输入层81个神经元连接,这样就得到20个滤波器。
二、pooling(第一种pooling不带参数)
先给出图示:

选择图像中的连续范围作为池化区域,并且只是池化相同(重复)的隐藏单元产生的特征,那么,这些池化单元就具有平移不变性(translation invariant)。这就意味着即使图像经历了一个小的平移之后,依然会产生相同的(池化的) 特征。
下面给出实验的结果和代码
实验参用的数据库为英国剑桥的大学的ORL人脸数据库。

图 ORL人脸数据库
下面是取自人脸的子块,一共取了5000个9×9大小的子块,并进行白化(后面会讲到),这个只是为了使每个像素点的特征独立,但不会像PCA那样降维,后面几节会讲到),子块如下图所示。

可以看到有人的鼻、眼睛、下巴等子块,下面提供autoencoder(见前面几节)训练滤波器,这是一个自学习网络。训练出64个滤波器如下图所示。

下面分别是任意一张人脸卷积和池化的结果图

卷积后的结果图

池化后结果图
数据库下载地址:http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html。 图片大小为112×92,一共200张,可以处理200×10304,并保存为FaceContainer.mat















 3072
3072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









