







谱聚类(Spectral Clustering)这名字看着就比Canopy、K-means来得高端大气上档次,事实上它确实是一种比较现代化的聚类方法,并且极具工程应用价值。谱聚类算法声称对样本空间的形状无限制,并能收敛于全局最优解。什么意思呢?我们知道,K-means聚类要求样本来自欧氏空间,从而可以计算欧氏距离,进而根据欧氏距离来决定一个样本点归属于哪个类。但现实总是残酷的,我们的研究对象往往并非来源于欧氏空间。举个例子,如果有个样本集,比方说是一群人,每个人具有身高、年龄、学历、籍贯等量纲难以统一的属性,那么亲,请告诉我样本间的欧氏距离怎么算?天知道把两个人的籍贯相减再平方,加上学历相减再平方,是个什么玩意儿。这个时候K-means就有了它的局限性。不仅如此,K-means还可能因为初始中心点选取不当而陷入局部最优解中——虽然这可以通过多次运行算法来解决。
话虽如此,但很明显,谱聚类算法狡猾地绕开了样本点之间“关系”的测度。它要求你只传递给它样本集的相似度矩阵即可。至于两个样本点的相似度怎么算,它可不管。所以我们还是要为K-means正个名:如果愿意,K-means完全可以使用类似相似度的指标来衡量样本点之间的关系,并以此为基础做聚类运算;只不过背负着历史的沉重包袱,我们所认定的正统K-means,应该是在欧式空间上做的聚类。所以在我看来,谱聚类最大的价值并不是对空间形状无要求,而是在于它针对海量样本进行聚类的高性能表现。而这一成就,是通过相似度矩阵稀疏化、拉普拉斯矩阵降维来达到的。这也是谱聚类的精髓所在,暂且按下不表。
那么相似度是个什么概念呢?它与欧氏距离有什么关系?答案是没啥关系,但这两个指标在衡量样本间关系时具有相反的意义——两样本欧氏距离越大,表明关系越远;而相似度则相反。作为一个非正式的例子,或者最简单的一种处理方式,你可以认为当样本空间是欧式空间时,样本点之间欧氏距离的倒数(如果有)就可以看成两个样本点的相似度。
鉴于谱聚类并不考虑相似度的计算逻辑,我事先得告诉你,当你把谱聚类算法执行流程都走通了之后,在实际应用时,你需要回过头来花费更多的时间来对样本间的相似度做精雕细琢的计算。因为它,只有它最大程度地决定了初始数据质量,从而决定了最终的聚类效果。
前面扯得有点多,很多概念我们后面还会详细阐述,但现在我们要马上进入实践环节。类似Canopy、K-means聚类,对于谱聚类,我们同样先关注如下问题:
- 谱聚类是什么?
- 输入数据的格式是什么?
- 如何提交程序执行聚类?
- 输出结果如何查看?
谱聚类是什么?
谱聚类是与时俱进、应运而生的聚类方法,大数据时代是它发挥的舞台(暂时先说这么多)。与其说它是个算法,不如说是算法框架,因为其诸多细节允许使用者根据实际需求来构造相应处理方式。其框架性流程如下:
(1)构建样本集的相似度矩阵W。
(2)对相似度矩阵W进行稀疏化,形成新的相似度矩阵A。
(2)构建相似度矩阵A的拉普拉斯矩阵L。
(3)计算拉普拉斯矩阵L的前k个特征值与特征向量,构建特征向量空间。
(4)将前k个特征向量(列向量)组合成N*k的矩阵,每一行看成k维空间的一个向量,利用K-means或其它经典聚类算法对该矩阵进行聚类。
(3)计算拉普拉斯矩阵L的前k个特征值与特征向量,构建特征向量空间。
(4)将前k个特征向量(列向量)组合成N*k的矩阵,每一行看成k维空间的一个向量,利用K-means或其它经典聚类算法对该矩阵进行聚类。
所以再废话一句,谱聚类并不神秘,它的实质,是降维后做K-means聚类。我们马上在Mahout中实现它。
Mahout Spetral Clustering输入数据格式
以下约定:
- $LOCAL表示本地数据存放目录
- $HADOOP_MAHOUT表示hadoop集群的mahout输出目录
- $MAHOUT_HOME表示本地mahout的安装目录
与Canopy、K-means聚类不同,Spectral要求直接输入相似度矩阵,而且要以(i, j, value)的形式输入,其中i,j是矩阵元素的行标签和列标签,以零开始,value是对应矩阵元素的值。我们为这次实验准备的数据如图1所示,它是已经计算好的相似度矩阵,是个对称矩阵,并且对角线上的值都为零。
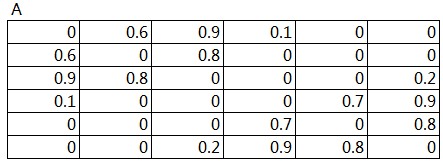
图1
![]()
不过这不能作为原始数据文件上传,需要处理成如下形式:
0,0,0
0,1,0.6
0,2,0.9
......
1,0,0.6
1,1,0
1,2,0.8
......
0,1,0.6
0,2,0.9
......
1,0,0.6
1,1,0
1,2,0.8
......
详细数据见[1],文件名为sc-data。
Mahout Spectral Clustering任务提交
准备好数据后,我们把存放数据的文件sc-data从本地上传到HDFS中:
hadoop fs -put $MAHOUT_HOME/sc-data $HADOOP_MAHOUT/
然后,执行以下命令行提交任务进行kmeans聚类:
mahout spectralkmeans \
-i $HADOOP_MAHOUT/sc-data \
-i $HADOOP_MAHOUT/sc-data \
-o $HADOOP_MAHOUT/ \
-k 2 \
-d 6 \
--maxIter 100
-d 6 \
--maxIter 100
在这条命令行中,参数-i的值是输入数据的路径,-o是输出文件存放路径,-k表示欲生成的类数,-d是相似度矩阵的维度,--maxIter限制最大迭代次数。
Mahout Spectral Clustering输出结果查看
Spectral Clustering的输出结果就保存在$HADOOP_MAHOUT文件夹下,包含5个子文件:
../calculations
../clusteredPoints
../clusters-0
../clusters-1
../clusters-2
calculations存放计算过程产生的数据。
clusteredPoints是最后的聚类结果,里面记录了每个向量及其对应所分的类。
clusters-0至clusters-2是程序最后执行K-means聚类,经过两次迭代所产生的数据文件,clusters-2则是最终聚类结果。
同样的,以上数据文件都是sequence file的形式,不能直接查看。我们使用下面的命令,将数据转化为可阅读的文本:
mahout seqdumper \
-s $HADOOP_MAHOUT/clusteredPoints/part-m-00000 \
-s $HADOOP_MAHOUT/clusteredPoints/part-m-00000 \
-o $LOCAL/clusteredPoints
mahout seqdumper \
-s $HADOOP_MAHOUT/clusters-0/part-randomSeed \
-s $HADOOP_MAHOUT/clusters-0/part-randomSeed \
-o $LOCAL/clusters-0
mahout seqdumper \
-s $HADOOP_MAHOUT/clusters-1/part-r-00000 \
-s $HADOOP_MAHOUT/clusters-1/part-r-00000 \
-o $LOCAL/clusters-1
mahout seqdumper \
-s $HADOOP_MAHOUT/clusters-2/part-r-00000 \
-o $LOCAL/clusters-2
clusteredPoints展示了每个样本分别属于哪个类别,其中key后面的值是类别编号,value后面的值是数据点,不过光看value的数据我们已经看不出它跟初始的相似度矩阵的联系了,好在它是按样本的顺序排列的。以下是实例的clusteredPoints数据文件内容:
Key: 1: Value: 1.0: [0.188, -0.982]
Key: 1: Value: 1.0: [0.915, 0.404]
Key: 4: Value: 1.0: [-0.902, 0.432]
Key: 1: Value: 1.0: [0.465, -0.885]
Key: 4: Value: 1.0: [0.748, 0.664]
Key: 4: Value: 1.0: [-0.994, 0.112]
Key: 1: Value: 1.0: [0.915, 0.404]
Key: 4: Value: 1.0: [-0.902, 0.432]
Key: 1: Value: 1.0: [0.465, -0.885]
Key: 4: Value: 1.0: [0.748, 0.664]
Key: 4: Value: 1.0: [-0.994, 0.112]
clusters-0至clusters-2是K-means聚类的生成结果,我们的问题是,K-means操作的数据集是什么?这涉及calculations这个文件夹。它的子文件如下:
../diagonal
../eigenvectors-192
../eigenverifier
../laplacian-0
../seqfile-168
../unitvectors-80
../vector
../eigenvectors-192
../eigenverifier
../laplacian-0
../seqfile-168
../unitvectors-80
../vector
注意eigenvectors-、laplacian-、seqfile-、unitvectors-后面的数字是随机生成的。K-means聚类的对象就存放在unitvectors-80的数据文件中,用vectordump可以把数据转换成可阅读的形式查看:
mahout vectordump \
-s $HADOOP_MAHOUT/calculations/unitvectors-80/part-m-00000 \
-s $HADOOP_MAHOUT/calculations/unitvectors-80/part-m-00000 \
-o $LOCAL/calculations-unitvectors
其内容如下:
{1:-0.9821410024116984,0:0.18814635628080645}
{1:0.40378499159750353,0:0.9148539121414981}
{1:0.43206003606297805,0:-0.9018448454347666}
{1:-0.8853509357734358,0:0.46492334908574123}
{1:0.6639814955737503,0:0.747749004369545}
{1:0.11218035585847443,0:-0.9936878623388062}
{1:0.40378499159750353,0:0.9148539121414981}
{1:0.43206003606297805,0:-0.9018448454347666}
{1:-0.8853509357734358,0:0.46492334908574123}
{1:0.6639814955737503,0:0.747749004369545}
{1:0.11218035585847443,0:-0.9936878623388062}
所代表的矩阵是:
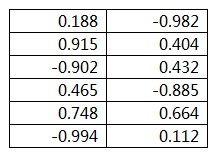
图2
回过头去看clusteredPoints的内容,是不是对上号了?
clusters-0给出了每个类别的初始中心点,如下所示:
Key: 1: Value: CL-1{n=0 c=[0.915, 0.404] r=[]}
Key: 4: Value: CL-4{n=0 c=[0.748, 0.664] r=[]}
Key: 4: Value: CL-4{n=0 c=[0.748, 0.664] r=[]}
我们还可以使用clusterdump将clusteredPoints和clusters-0至clusters-2的结果整合在一起,由于clusters-2代表了最后的聚类结果,我们来查看这个文件代表的类别。命令行如下:
mahout clusterdump \
-s $HADOOP_MAHOUT/clusters-2 \
-s $HADOOP_MAHOUT/clusters-2 \
-p $HADOOP_MAHOUT/clusteredPoints \
-o $LOCAL/clusters-2-dump
样例为:
VL-1{n=3 c=[0.523, -0.488] r=[0.299, 0.632]}
Weight: Point:
1.0: [0.188, -0.982]
1.0: [0.915, 0.404]
1.0: [0.465, -0.885]
VL-4{n=3 c=[-0.383, 0.403] r=[0.800, 0.226]}
Weight: Point:
1.0: [-0.902, 0.432]
1.0: [0.748, 0.664]
1.0: [-0.994, 0.112]
Weight: Point:
1.0: [0.188, -0.982]
1.0: [0.915, 0.404]
1.0: [0.465, -0.885]
VL-4{n=3 c=[-0.383, 0.403] r=[0.800, 0.226]}
Weight: Point:
1.0: [-0.902, 0.432]
1.0: [0.748, 0.664]
1.0: [-0.994, 0.112]
其中,
VL-1代表这是一个cluster
n=3代表该cluster有3个点
c=[...]代表该cluster的中心点
r=[...]代表cluster的半径
n=3代表该cluster有3个点
c=[...]代表该cluster的中心点
r=[...]代表cluster的半径















 5148
5148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









