







【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
上期:自动驾驶Occupancy梳理笔记(一)-CSDN博客
重要论文梳理
2.5 SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving [ICCV 2023]
- 任务:1. 数据集建立(用多帧点云构建稠密Occ数据集); 2.Occ 预测(语义占用预测)
- Occ 数据集生成:多帧Lidar点云 → 聚合点云【把静态场景和动态物体分开处理后合并】→ 泊松重建和最近邻算法【填补空缺】 → Occ 真值
- 重点:直接将2D图像特征提升到3D体素特征,而不是BEV特征
- Occ 预测 Pipeline:
环视图【输入】 → 2D Encoder & FPN【提取图像特征,多尺度特征融合】→ 2D-3D Spatial Attention【整合多个相机的特征(各个尺度)】 → 3D体素特征 → 反卷积上采样并组合各尺度特征 → Occ 预测值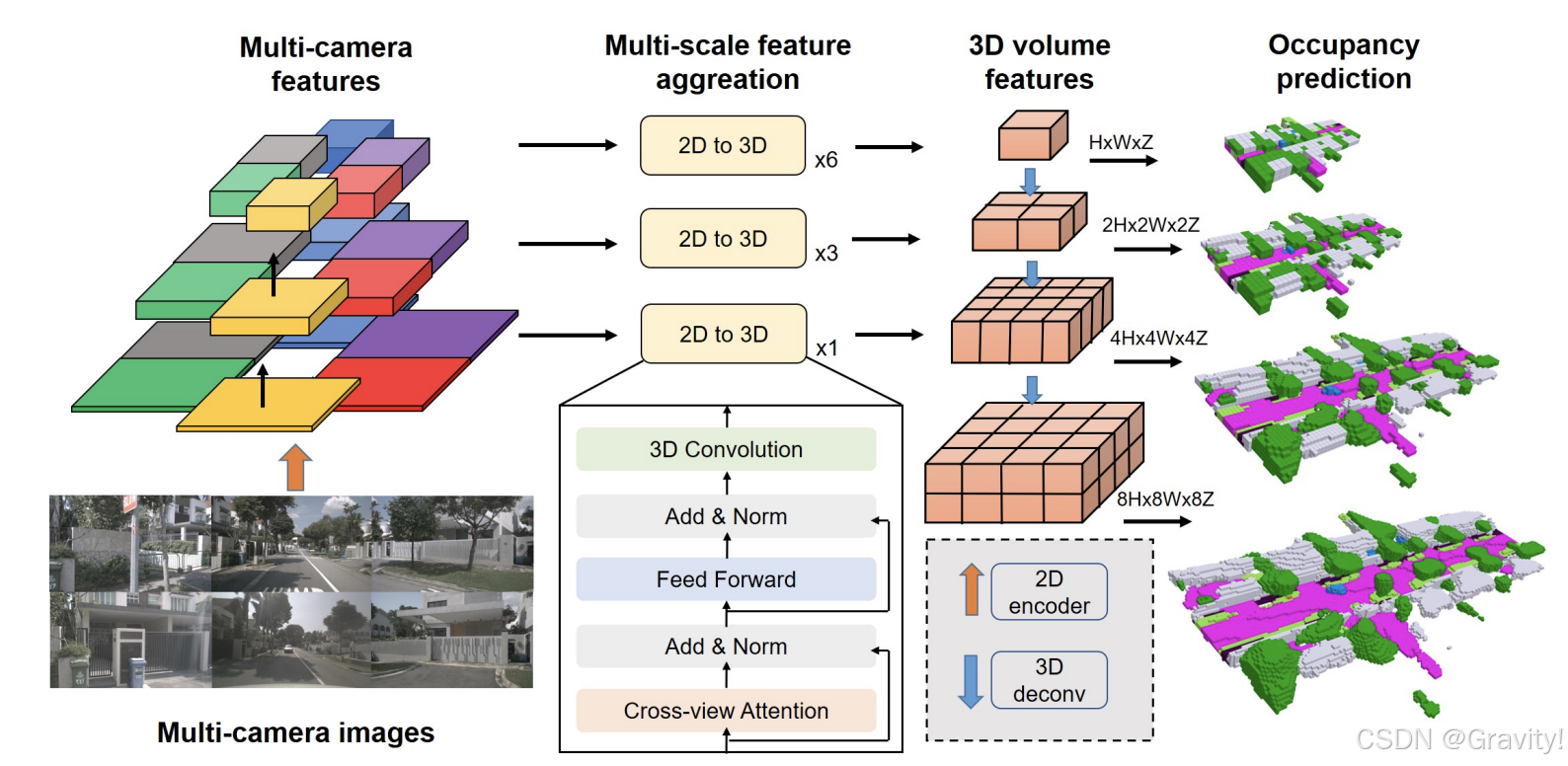
- 核心模块:2D-3D Spatial Attention
改进点:把 BEV query(BEVFormer)换成 3D volume query【BEVFormer将所有相机视图的特征算平均,但是不同视图的贡献是不同的(比如有被遮挡或模糊的情况)】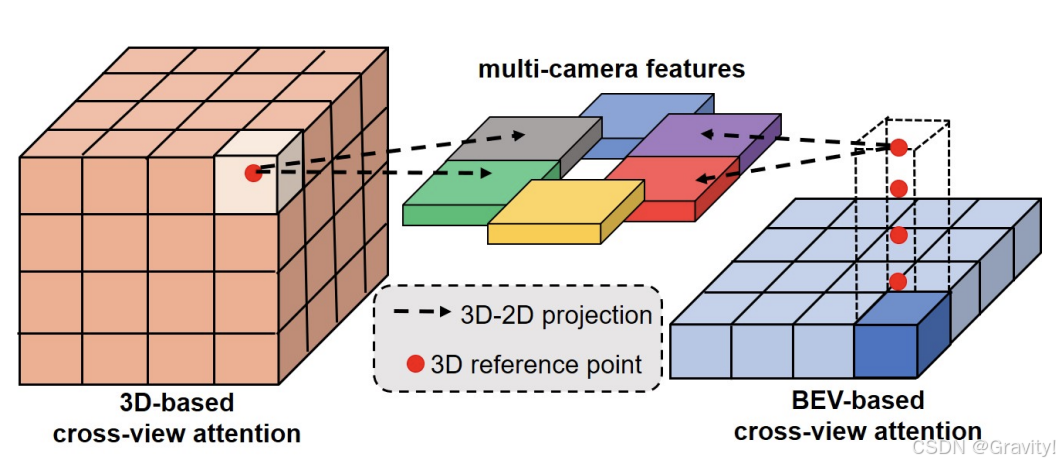
2.6 OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction [ICCV 2023]
- 任务:Occ 预测(语义占用预测)
- 重点:双路径Transformer模块局部和全局特征编码,多尺度特征融合解码
- Pipeline:
前视图/环视图【输入】 → 2D Encoder & fusion neck【提取图像特征,多尺度特征融合】→ 2D-3D视角转换【分别处理深度分布和语义特征】 → 池化【得到3D体素特征】 → 双路径编码器【得到多尺度编码特征】 → 多尺度3D Deformable Attention解码【多尺度信息交互】 → Occ解码器 → Occ预测结果
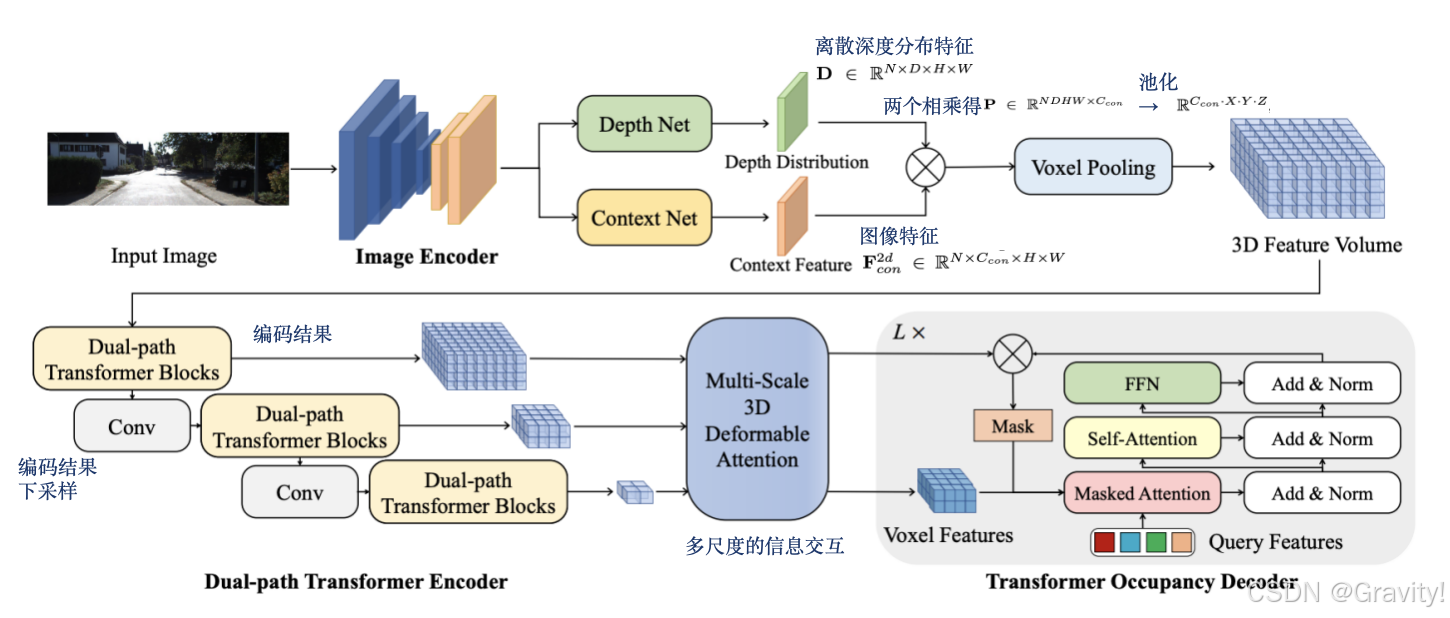
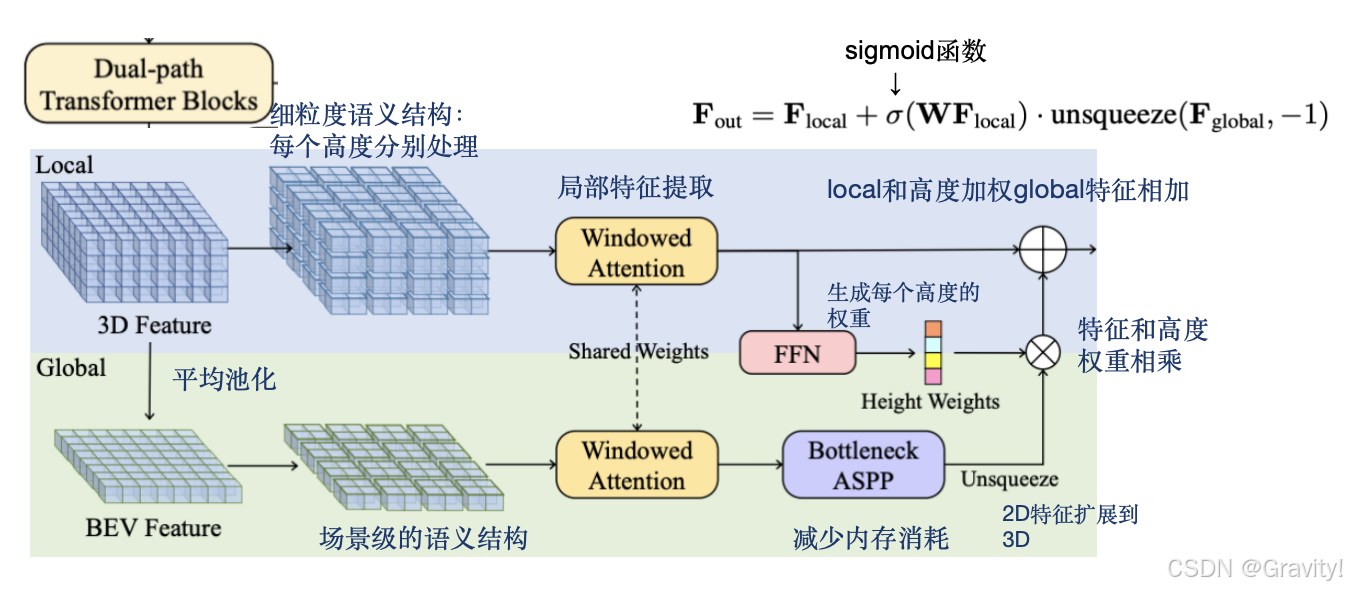
- 核心模块1:Dual-path Transformer Encoder(双路径编码器)
提取局部(每个高度)和全局BEV特征 【跟3D卷积比:数量和计算量更少,因为只处理2D特征】
- 核心模块2:Transformer Occupancy Decoder(解码出Occ)
由两个decoder构成:- Pixel decoder【多尺度语义特征 → voxel embedding】:通过多尺度可形变注意力(multi-scale deformable attention)实现,在同一个尺度内和不同尺度间进行特征采样
- Transformer Decoder:用voxel embedding更新query,多次迭代
2.7 VoxFormer: a Cutting-edge Baseline for 3D Semantic Occupancy Prediction [CVPR 2023 Highlight]
- 任务:场景语义补全(和MonoScene一样)
- 重点:两阶段方法,设计了类似masked autoencoder(MAE) 的transformer做场景补全
- Pipeline:
- 第一阶段:单帧/多帧前视图 → 深度估计 → 生成 query proposals(有深度信息的query)
- 第二阶段(类似masked autoencoder的transformer):query proposals & 图像特征 → Deformable cross attention【让query有图像信息】 → Deformable self-attention【特征扩散给整个voxels】→ 上采样输出语义补全结果
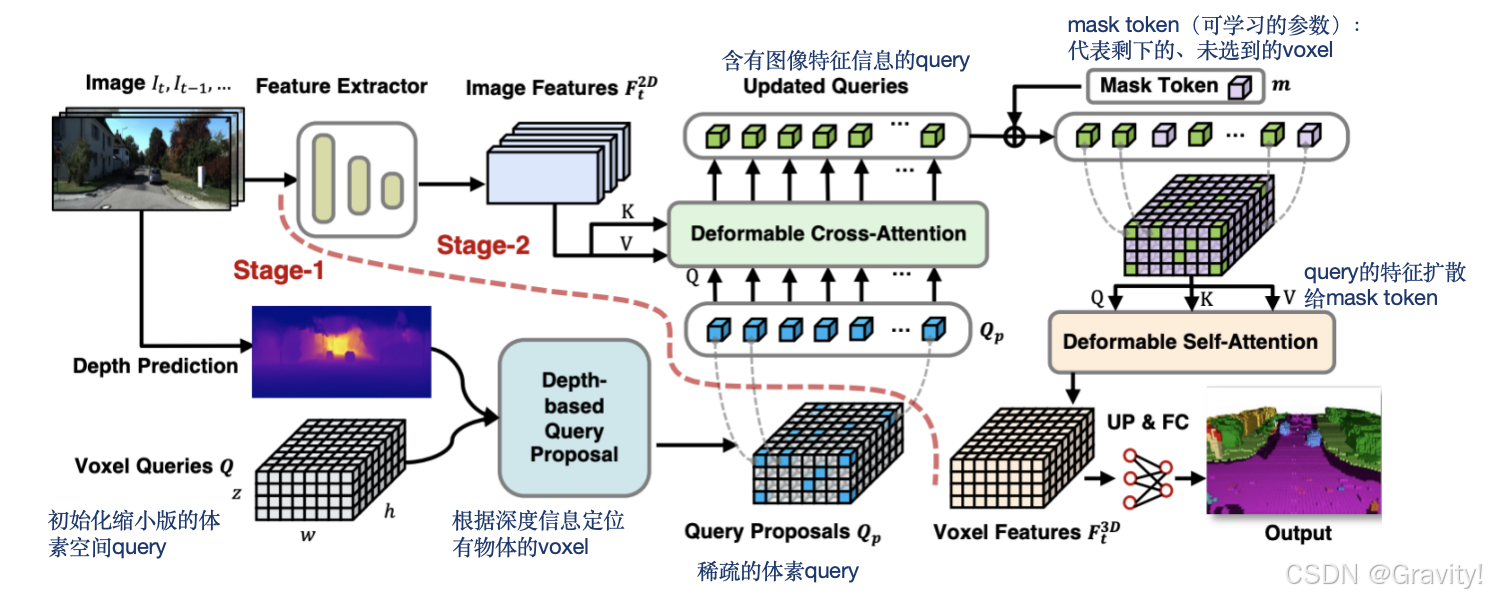
- Stage-2 Loss:加权交叉熵(类别数量越多,权重却低)
2.8 FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation [CVPR2023 3D Occupancy Prediction 挑战赛冠军方案]
- 任务:Occ 预测(语义占用预测)
- 重点:前向投影(LSS)+ 后向投影(类似BEVFormer)实现2D-3D视角转换
- Pipeline:
- 环视图【输入】 → backbone【提取图像特征,多尺度特征融合】→ 深度网络【得到深度估计信息】 → 2D-3D视角转换【前向投影(LSS)+ 后向投影(类似BEVFormer)】 → 组合体素特征 → 输出occ预测结果
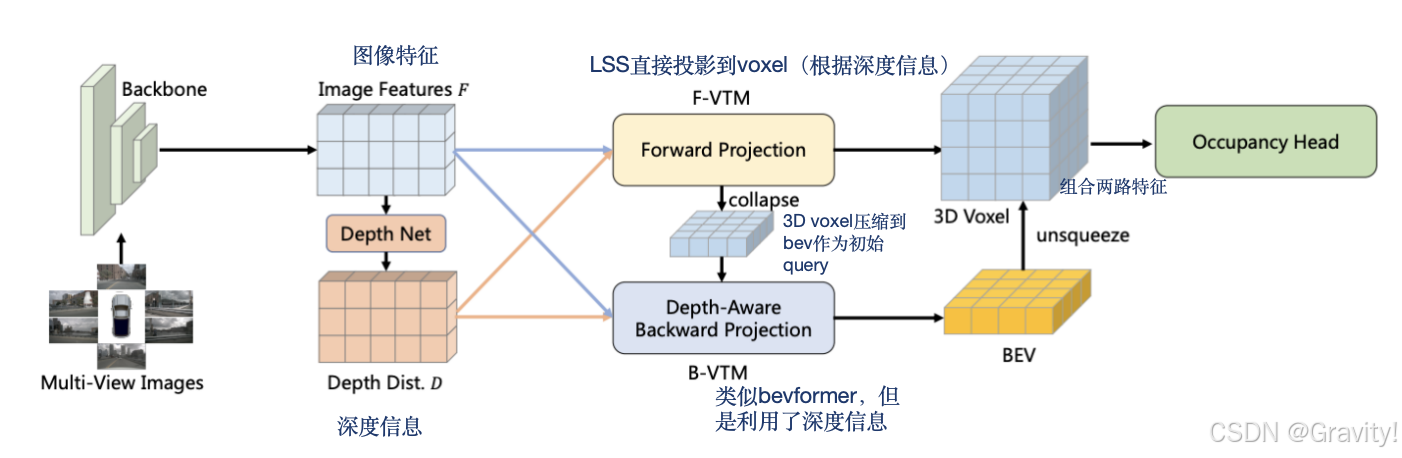
- 环视图【输入】 → backbone【提取图像特征,多尺度特征融合】→ 深度网络【得到深度估计信息】 → 2D-3D视角转换【前向投影(LSS)+ 后向投影(类似BEVFormer)】 → 组合体素特征 → 输出occ预测结果
- 预训练:2d检测任务,深度估计


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









