







【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
论文1:MaskGIT: Masked Generative Image Transformer 【CVPR 2022】
- 任务:图像生成
- 以往自回归(autoregressive)生成图像方法:
- 阶段一:量化(原图像 → 离散图像tokens),模型如VQ-VAE
- 解释:离散的图像token为codebook的索引值,比如把图像patch划分为2048个特征,codebook的形状为2048*feat_dim,离散的图像token值的范围为 0 — 2047
- 阶段二:自回归生成图像token(此时,图像token是一维序列)
- 阶段一:量化(原图像 → 离散图像tokens),模型如VQ-VAE
- MaskGIT 改进点:用掩码(mask)预测,而不是自回归 【实现并行解码 & 双向生成】
- 实现方法:
- Pipeline(上部分为阶段一,下部分阶段二)
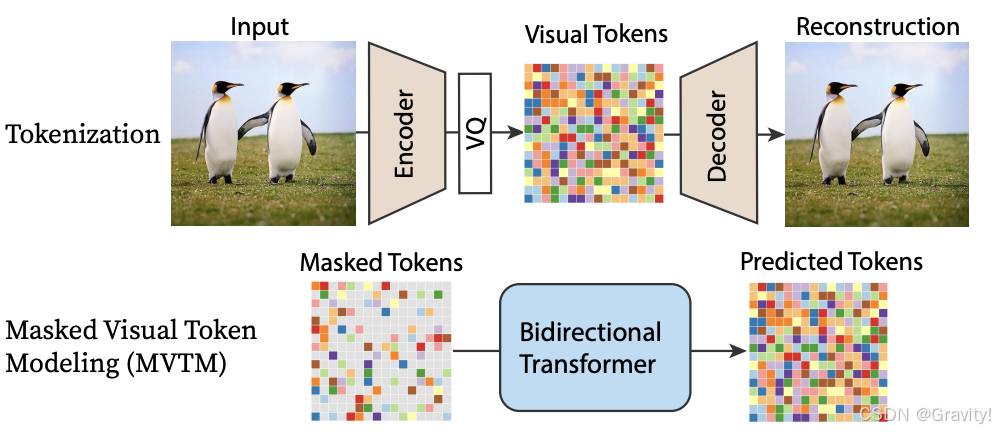
- 训练时 如何加mask: MVTM(Masked Visual Token Modeling)
- 在 img token序列中随机采样一部分,用[MASK] token替换
- 采样过程:先定采样比率,按照比率进行均匀随机采样。其中,掩码调度显著影响图像生成的质量
- 训练时 使用双向Transformer
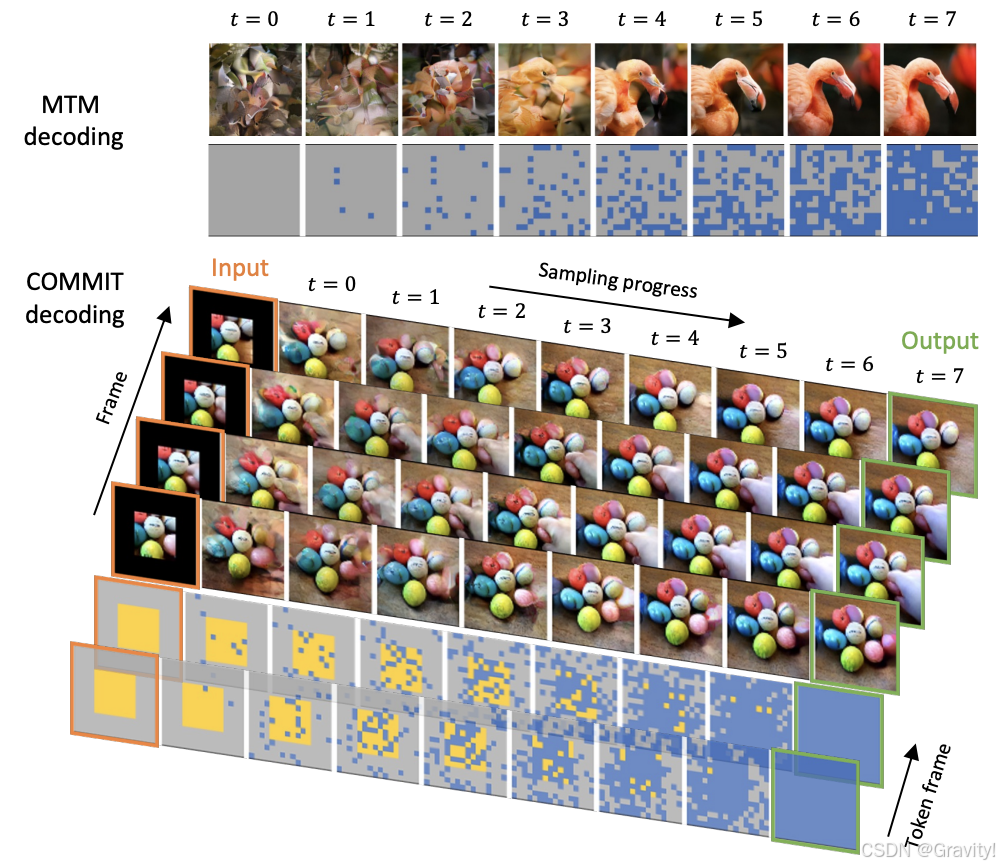
- 推理时 迭代解码(Iterative Decoding)
- 理论上,可以一次就从空白图预测出整个图像,但是这样不能预测好(因为训练的时候是已知部分原图token,不是整个图未知)
- 解码过程:空白图(全[MASK]) → [ 预测【预测所有[MASK] token,得到预测概率】→ 抽样【并不是拿最高概率,而是codebook中随机抽,置信度为对应的预测概率】→ 掩码策略(Mask Schedule)【总共迭代T步,设置每步掩码率】→ 设置本轮掩码 ] × T → 最终预测图像
- Pipeline(上部分为阶段一,下部分阶段二)
- 为什么掩码(mask)预测会比自回归预测的方法好?
- 掩码预测是双向的:自回归方法在预测当前token的时候,只能看到前一个token;掩码预测可以看到当前[MASK] token的前一个和后一个(所以是“双向”)
- 掩码预测可以并行:自回归方法不可以并行(因为预测过程是有序的,只能从前到后)
- 如何设计迭代时每步的掩码率?
- 三类方法:
- 线性函数:时间t (步) 和mask数是线性关系
- 凹函数(包括包括余弦、平方、立方和指数函数):开始时大多数被mask,后期掩码率急剧下降,预测难度增大【由少到多,性能最好】
- 凸函数:和凹函数相反,由多到少
- 图示:左边是时间和mask数的关系(剩多少mask),右边是不同方法的性能
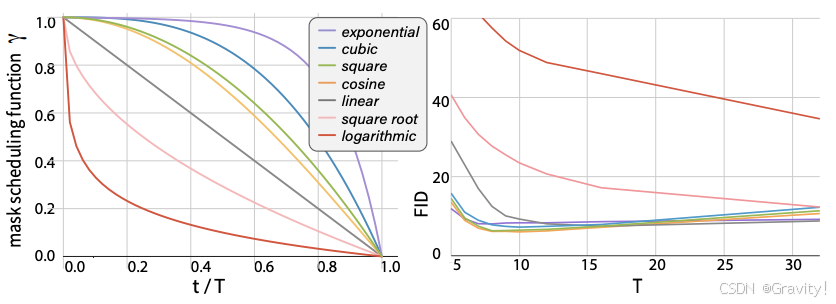
- 三类方法:
论文2:MAGVIT: Masked Generative Video Transformer【CVPR2023 Highlight】
- 任务:视频生成
- Pipeline:
- 输入 → Tokenize【阶段一】 → COMMIT掩码预测【阶段二】→ 预测结果
- 阶段一:Spatial-Temporal Tokenization
- 基于 VQGAN 改进:2D卷积 换 3D卷积(增加时间维度)
- 阶段二:COMMIT(COnditional Masked Modeling by Interior Tokens)
- 与MaskGIT阶段二的区别:
根据任务(如预测、插值、修复),把已知的视频内容作为条件,根据条件生成
- mask的设置:
- 有条件部分:条件token(已知的视频信息)
- 非条件部分:① 设成[MASK] token ② 阶段一根据输入得到的token
- 损失函数:[MASK]预测损失 + 重建损失(阶段一)+ 条件修正损失(使条件token更接近真实token,最大化条件的利用)
- 与MaskGIT阶段二的区别:
- 输入 → Tokenize【阶段一】 → COMMIT掩码预测【阶段二】→ 预测结果
论文3:[MAGVIT-V2] Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation 【ICLR 2024】
- 相比MAGVIT的改进点:
- 量化方法:Lookup quantizer → Lookup-free quantizer (LFQ)
- Tokenize方法:联合图像和视频的Tokenization
- 无查找量化方法 Lookup-free quantizer (LFQ)
- LFQ是什么:将连续的特征映射到离散的codebook中,同时避免Lookup table的使用
- 如何设计Codebook
来实现?
- Codebook的每个embedding用二进制变量 {-1, 1} 表示
- Codebook的嵌入维度(d) 变成零【对比之前的VQ-VAE有高维embedding】,所以 Codebook_size (K) 可以非常大
- 为什么Lookup-free会比Lookup的方法好?
- Codebook size 越大,性能越好;但是之前的VQVAE在增大size之后性能可能下降
- 显著减少计算复杂度和内存占用
- 联合图像和视频令牌化 Joint image-video Tokenization
- 探索两种设计:
- C-ViViT + MagViT:结合 C-ViViT(其中的时序因果Transformer)和 MagViT 的 3D CNN(做空间处理)
- 因果 3D CNN:每个输出帧只依赖于之前的帧 【表现最佳】
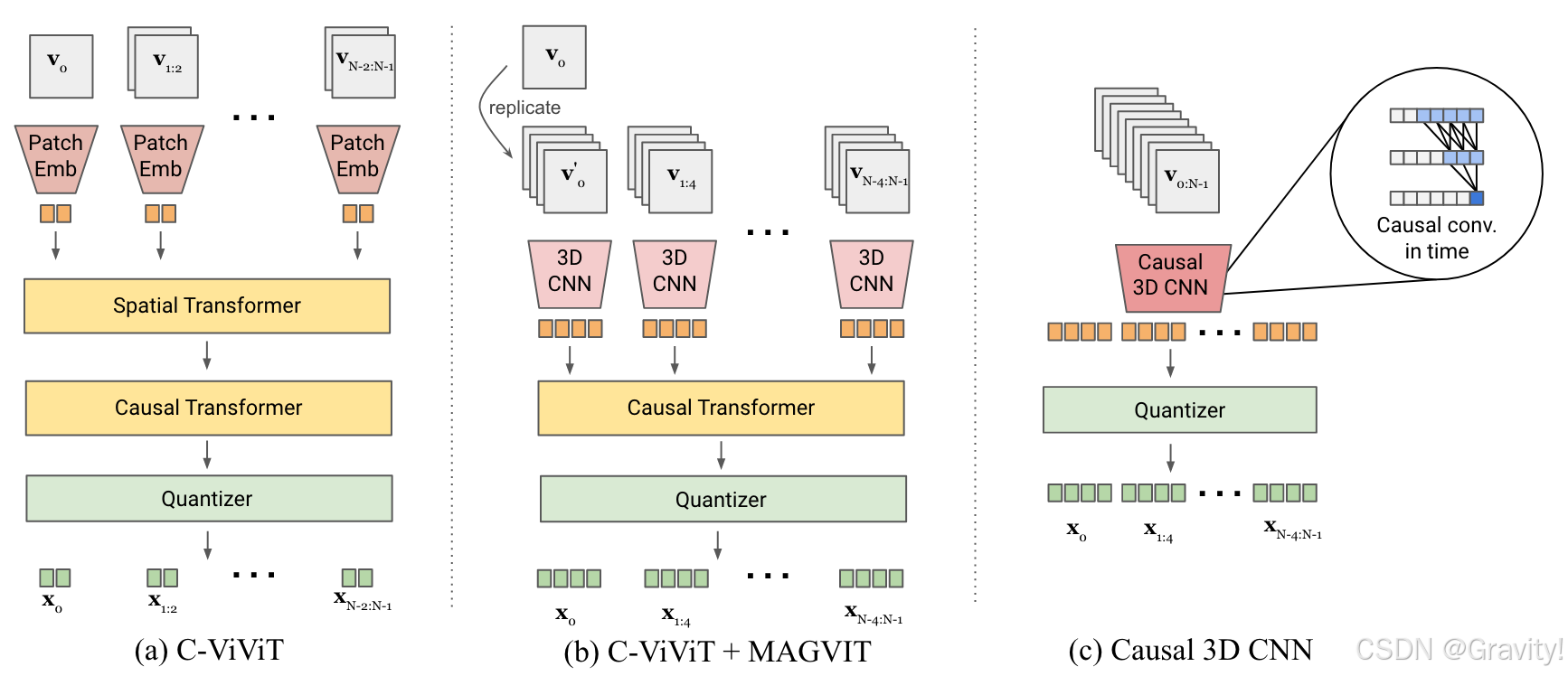
- 探索两种设计:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









