









Faster R-CNN论文翻译——中英文对照
https://www.jianshu.com/p/26ca6f6bd1a1?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
Faster R-CNN 中 RPN 的总结和疑惑解答
链接:https://www.jianshu.com/p/cbfaa305b887
RPN 整体流程
在faster RCNN 原文中,RPN网络示意图如下(其中的K为特征图中每个点上的anchor数目,一般取k=9):

首先我们用真实数据代入,把RPN整个流程走一遍:
- 前提:通过一系列卷积得到公共特征图,假设他的大小是N x 16 x 16,然后我们进入RPN阶段
- RPN阶段:首先经过一个3 x 3的卷积,得到一个256 x 16 x 16的特征图,也可以看作16 x 16个256维特征向量,然后经过两次1 x 1的卷积,分别得到一个18 x 16 x 16的特征图(其中18=9 x 2),和一个36 x 16 x 16的特征图(其中36=4 x 9),也就是16 x 16 x 9(9是anchor的数目)个结果,其中每个结果包含2个分数和4个坐标,再结合预先定义的Anchors,经过后处理,就得到候选框;
整个流程如图:

RPN 的主要步骤
步骤如下:
1、利用 VGG16 等卷积神经网络的卷积层的到一些特征图,例如图中的 256 个 H * W 的特征图
2、在特征图上用 3 * 3 的滑动窗口进行卷积,得到进一步的 256 * H * W 的特征图,从特征的维度看可以看成 H * W 的特征图上每个点都有一个 256 维的特征向量
3、将特征图上每个点的 256 维特征与两个全连接层连接。第一个全连接层输出 2 * 9 个值,即这个锚点对应的 9 个 achor box,每个 box 两个值分别表示包含目标的概率与不包含的概率(使用了 softmax loss 所以需要两个值)。例如前两个值表示 128 * 128 的 box 包含与不包含目标的概率。第二个全连接层输出 4 * 9 个值,每个 anchor box 对应 4 个值,它们分别表征对 groud truth 的长宽与x、y坐标的预测。(训练时只有包含目标(即与 groud truth 的 IoU>0.7)的 anchor box 对 groud truth 位置与大小预测的误差才会对 loss 有贡献)
4、对步骤 3 中预测包含目标的 anchor box,利用 4 个位置回归值对 box 进行平移和缩放,就能产生大量的候选框,此时利用非极大值抑制筛选一些预测分较高的候选框,作为最终的 region proposals
anchor机制
原文
At each sliding-window location, we simultaneously predict multiple region proposals, where the number of maximum possible proposals for each location is denoted as k(每个位置点最大可能的候选框数记为K). So the reg layer has 4k outputs encoding the coordinates of k boxes, and the cls layer outputs 2k scores that estimate probability of object or not object for each proposal4. The k proposals are parameterized relative to k reference boxes, which we call anchors(K个候选框是以k个参考框(锚点)为基准参数化而来的).
An anchor is centered at the sliding window in question, and is associated with a scale and aspect ratio (Figure 3, left). By default we use 3 scales and 3 aspect ratios, yielding k = 9 anchors at each sliding position. For a convolutional feature map of a size W × H (typically ∼2,400), there are WHk anchors in total.
特征图中每个红色框的中心点都可以对应到原图的某个点,原图中的这个点被称为锚点(anchor)。
对于每个锚点,我们都会以它为中心点选择 9 个不同大小和长宽比例的框(论文中为 128 * 128,256 * 256,512 * 512 的三种尺寸,每种尺寸按 1:1,1:2,2:1的长宽比例缩放,共 9 个,它们在预测时的顺序是固定的),作为 RPN 需要评估的候选框。(有的文章中写(8,16,32)三种尺寸,那么就是针对的特征图,(8,16,32)x16=(128,256,512))
RPN 的目标就是对原图中的每个锚点对应的 9 个框,预测他是否是一个存在目标的框(并不一定包含完整的目标,只要这个框与 groud truth 的 IoU>0.7就认为这个框是一个 region proposal)。并且对于预测为 region proposal 的框, RPN 还会预测一种长宽缩放和位置平移的位置修正,使得对这个 anchor box 修正后与 groud truth 的位置尽可能重叠度越高,修正后的框作为真正的 region proposal。
原文中的anchor尺寸表如下:

为什么 RPN能够预测 groud truth 的位置(输入特征只有图像像素的卷积特征,完全没有位置信息)?
实际上步骤 3 中预测的 4 个值不是直接预测 H, W, x, y,很显然由于特征图上每个点都是共享权值的,它们根本没法对不同的长宽和位置做出直接的预测(想象一下输入的特征只是图像的卷积特征,完全没有当前 anchor box 的位置大小信息,显然不可能预测出 groud truth 的绝对位置和大小)。这 4 个值是预测如何经过平移与缩放使得当前这个 anchor box 能与 groud truth 尽可能重合(见 R-CNN 论文附录C):
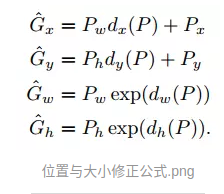
公式中 P 表示预测包含目标的 region proposal,G 表示这个 region proposal 对应的 groud truth,x, y, w, h分别表示横坐标、纵坐标、宽和高。dx§, dy§, dw§, dh§ 即 RPN 预测的 4 个值,它们表征的是对位置平移与大小缩放的系数。
由于 4 个 G 值与 4 个 P 值都是已知的,那么我们训练时就有了 dx§, dy§, dw§, dh§ 的目标值如图所示:

全连接层就是一个回归函数,用于预测 4 个系数 d:
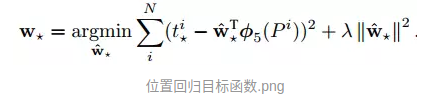
只有图像像素卷积信息确实没法预测 groud truth 的绝对位置和大小,但是利用图像信息完全有可能预测当前 region proposal 在 grouth truth 中的相对位置,我们也就可以预测怎么对当前 anchor box 进行平移与缩放得到包含整个目标的候选框。例如一辆自行车,可能当前的 anchor box 中包含着自行车的前轮与把手部分,当 cnn 检测到这样的特征时,他就能预测将这个 box 向右平移并且水平方向扩大一倍就是整个自行车目标的 groud truth部分
RPN网络详细结构
RPN网络的作用是输入一张图像,输出一批矩形候选区域,类似于以往目标检测中的Selective Search一步。网络结构是基于卷积神经网络,但输出包含二分类softmax和bbox回归的多任务模型。网络结果如下(以ZF网络为参考模型):
其中,虚线以上是ZF网络最后一层卷积层前的结构,虚线以下是RPN网络特有的结构。首先是33的卷积,然后通过11卷积输出分为两路,其中一路输出是目标和非目标的概率,另一路输出box相关的四个参数,包括box的中心坐标x和y,box宽w和长h。
在附录中,也可以清晰地看到RPN网络的结构。

附录:faster RCNN 网络结构图
















 9773
9773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









