






企业存储系统
硬盘
硬盘
硬盘是计算机的主要存储硬件,可以用来存储大量数据。目前(2020年),市面上比较流行的硬盘多数是TB级的。
SATA硬盘
SATA即Serial ATA(串行ATA),是由Intel、IBM、Maxtor和Seagate等公司提出的硬盘接口规范。采用的是串行连接方式,很多时候会把SATA接口的硬盘称之为串口硬盘。
SATASSD固态硬盘
采用固态电子存储芯片阵列制作的硬盘,是以闪存作为永久性存储器的存储设备。固态硬盘的读取速度可以在500Mb/s左右。
RAID磁盘列阵
单个硬盘的存储能力是有限的,如果要存储更多的数据,可以通过某种技术,将若干个硬盘连接在一起,提供能耗的存储能力。我们在服务器上插更多的磁盘来提高存储容量,而服务器上的插槽是有限的,我们无法无限地增加硬盘。所以,我们可以买RAID磁盘阵列来解决数据存储速度、容错问题。
RAID可以将多块独立的硬盘组织在一起,可以将多块硬盘连接在一起,并在性能上、容错上会有一定地提升。
文件系统
介绍
计算机的文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易
文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘和光盘等物理设备使用数据块的概念,用户使用文件系统来保存数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,只需要记住这个文件的所属目录和文件名。
在写入新数据之前,用户不必关心硬盘上的那个块地址没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。
文件系统通常使用硬盘和光盘这样的存储设备,并维护文件在设备中的物理位置。但是,实际上文件系统也可能仅仅是一种访问资料的界面而已,实际的数据是通过网络协议(如NFS、SMB、9P等)提供的或者内存上,甚至可能根本没有对应的文件(如proc文件系统)。
严格地说,文件系统是一套实现了数据的存储、分级组织、访问和获取等操作的抽象数据类型(Abstract data type)。
重要概念
文件系统是一种用于向用户提供底层数据访问的机制。它将设备中的空间划分为特定大小的块(或者称为簇),一般每块512字节。数据存储在这些块中,大小被修正为占用整数个块。由文件系统软件来负责将这些块组织为文件和目录,并记录哪些块被分配给了哪个文件,以及哪些块没有被使用。
不过,文件系统并不一定只在特定存储设备上出现。它是数据的组织者和提供者,至于它的底层,可以是磁盘,也可以是其它动态生成数据的设备(比如网络设备)。
文件名
在文件系统中,文件名是用于定位存储位置。
大多数的文件系统对文件名的长度有限制。在一些文件系统中,文件名是大小写不敏感(如“AAA”和“aaa”指的是同一个文件);在另一些文件系统中则大小写敏感。
大多现今的文件系统允许文件名包含非常多的Unicode字符集的字符。然而在大多数文件系统的界面中,会限制某些特殊字符出现在文件名中。(文件系统可能会用这些特殊字符来表示一个设备、设备类型、目录前缀、或文件类型),为方便起见,一般不建议在文件名中包含特殊字符。
元数据
其它文件保存信息常常伴随着文件自身保存在文件系统中。
文件长度可能是分配给这个文件的区块数,也可能是这个文件实际的字节数。文件最后修改时间也许记录在文件的时间戳中。有的文件系统还保存文件的创建时间,最后访问时间及属性修改时间。(不过大多数早期的文件系统不记录文件的时间信息)其它信息还包括文件设备类型(如:区块数,字符集,套接口,子目录等等),文件所有者的ID,组ID,还有访问权限(如:只读,可执行等等)。
文件系统分类
磁盘文件系统
磁盘文件系统是一种设计用来利用数据存储设备来保存计算机文件的文件系统,最常用的数据存储设备是磁盘驱动器,可以直接或者间接地连接到计算机上。例如:FAT、exFAT、NTFS、HFS、HFS+、ext2、ext3、ext4、ODS-5、btrfs、XFS、UFS、ZFS。
光盘
ISO 9660和UDF被用于CD、DVD与蓝光光盘。
网络文件系统
网络文件系统(NFS,Network File System)是一种将远程主机上的分区(目录)经网络挂载到本地系统的一种机制。
海量数据存储问题
高成本
传统存储硬件通用性差,设备投资加上后期维护、升级扩容的成本非常高。
性能低
单节点I/O性能无法逾越,容量和内存都不易拓展,难以支撑海量数据的高并发高吞吐场景。
可拓展性低
无法实现快速部署和弹性扩展。
支持大数据分析、AI
传统存储与spark等大数据分析平台对接是否有难度,一套存储能否满足企业数据存储,管理和挖掘的需求。
如何解决海量数据存的下问题
传统存储方式
应对文件存储服务,传统做法是在服务器上部署文件服务比如FTP。但是随着数据变多,会遇到存储瓶颈。此时,本能的操作反应是:内存不够加内存,磁盘不够加磁盘—单机纵向扩展。但是单机能够扩展的内存磁盘是有上限的,不能无限制下去
分布式存储方式
纵向扩展有上限,自然想到横向扩展。所谓横向指的是采用多台机器存储,一台不够就多台一起存储,不够就加机器。
理论上,可以横向无限制下去。因此海量数据如何存储的下的问题解决方式就是采用多台机器存储—即分布式存储。
如何解决便捷查询数据
当文件被分布式存储在多台机器之后,后续获取文件的时候如何能快速找到文件位于哪台机器上呢。一台一台查询过来也不靠谱。因此可以借助于元数据记录来解决这个问题。把文件和其存储的机器的位置信息记录下来,类似于图书馆查阅图书系统,这样就可以快速定位文件存储在哪一台机器上了。
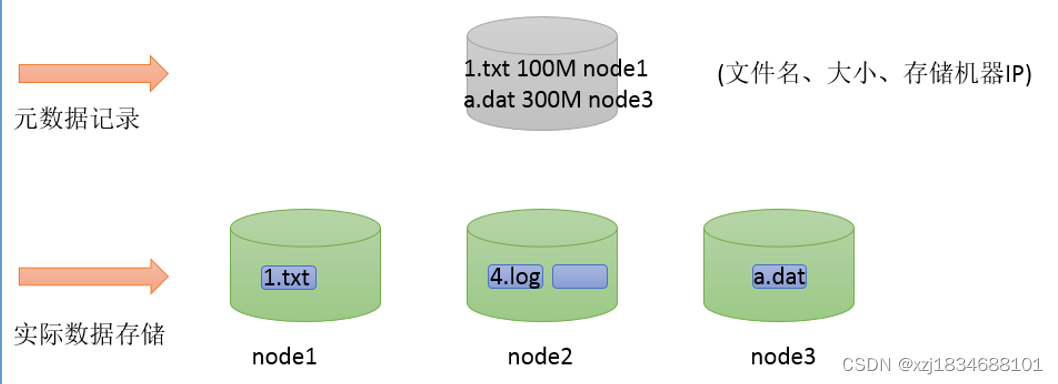
如何解决大文件传输效率慢的问题
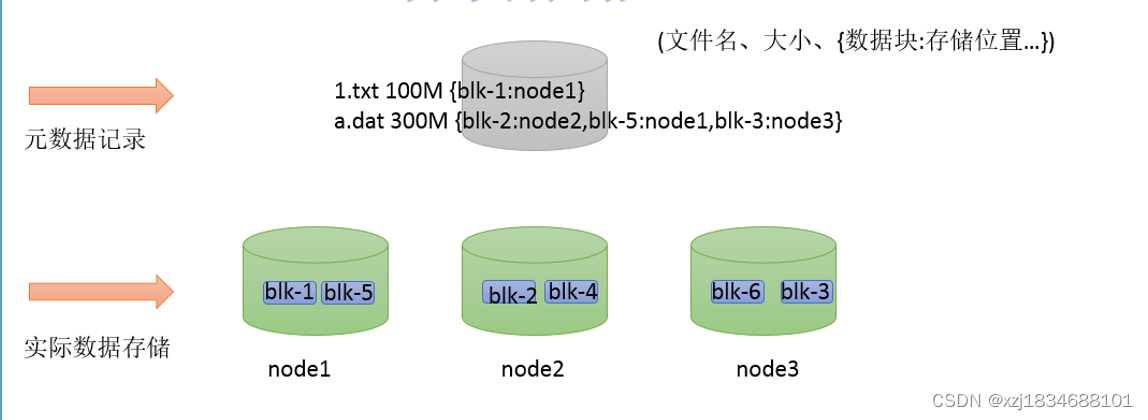
大数据使用场景下,GB、TP级别的大文件是常见的。当单个文件过大的时候,如何提高传输效率?通常的做法是分块存储:把大文件拆分成若干个小块(block 简写blk),分别存储在不同机器上,并行操作提高效率。
此外分块存储还可以解决数据存储负载均衡问题。此时元数据记录信息也应该更加详细:文件分了几块,分别位于哪些机器上。
总结
通过上述场景式分析,可以得出要想实现一个分布式文件系统,是需要多方面综合考虑的。通常来说一个分布式文件系统需要具备:分布式特性、分块存储、副本机制、元数据记录、抽象目录树、统一namespace命名空间。
特点
将所有的廉价的计算机连接起来,来存储数据,强调的是整体的存储能力,而不是单机能力。
HDFS的主机理论上是无限扩展的,理论上可以存储无限多文件。
HDFS适合存储大文件,不适合存储小文件,因为HDFS中不管大文件还是小文件,都会占用一份元数据,每一份元数据是150字节,这些元数据是有namenode内存进行管理,如果小文件过度,就会将NAMENODE的内存耗尽,无法存储新的文件。
HDFS上的文件只支持追加写入,不支持对文件的随机修改,因为HDfS存储的数据都是已经发生过的历史数据,不需要修改。
HDFS的存储过程不是实时的,存储时需要消耗一定的时间,有延迟 ,所以一般都是用于离线存储。
HDFS的架构
NAMENODE
NAMENODE管理着整个HDFS集群
NAMENODE管理着所有的HDFS的元数据 (/a.txt rwx 1K 3 {blk:node1,node2,node3})
Client上传或下载文件必须先找NAMENODE
一旦NAMENODE挂掉,整个HDFS集群都无法工作
各个DATANODE每隔一段时间都会向NAMENODE汇报自己的Block信息和磁盘信息
DATANODE
DATANODE是存储具体数据的,HDFS所有真实数据都在DATANODE存储
各个DATANODE每隔一段时间都会向NAMENODE汇报自己的Block信息和磁盘信息
Client在上传和下载文件时,和NAMENODE交流后,真实的数据上传和下载是在Client和DATANODE之间
SECONDARYNAMENODE
辅助NAMENODE进行元数据管理,将NAMENODE内存中元数据保存到硬盘上
HDFS切片机制
Client在向HDFS上存储时,Client会将文件进行切片,每一个切片最大128M,切片又被称为Block,逻辑单位。
我们可以自定义每一个切片的大小,位于hdfs-site.xml文件中,dfs.blocksize,默认大小是128M(134217728字节)[假设一个文件300M,会被切分为三个文件,Block1-128M,Block2-128M,Block3-44M]
HDFS副本机制
HDFS默认一个Block是三个副本,我们也可以修改该值,在hdfs-site.xml文件中,dfs.replication参数
HDFS每存放一个Block的副本时,有一个策略
HDFS的副本数量必须小于等于集群主机的数量(3台主机,不能有4个副本)
HDFS的名称空间
用来标识每一个文件在HDFS上的路径,有以下两种写法
/dir/a.txt #只能用于在集群内部的访问
hdfs://node1:8020/dir/a.txt
HDFS的元数据
HDFS上的每一个文件信息都是元数据,这个元数据不是文件的内容,而是描述文件特征的信息
-rw-r--r-- root supergroup 39 B Sep 06 21:31 3 128 MB a.txt
HDFS安全模式
启动HDFS时,HDFS会自动进入安全模式,在安全模式完成Block的自我检测和修复 当发现HDFS的副本率达到99.99%,HDFS会自动离开安全模式
进入安全模式后,用户只能查看HDFS文件,不能对HDFS文件进行增删改
安全模式的手动操作命令
hdfs dfsadmin -safemode get #查看安全模式的状态
hdfs dfsadmin -safemode enter #进入安全模式
hdfs dfsadmin -safemode leave #离开安全模式
hdfs dfsadmin -safemode forceExit #离开安全模式















 3991
3991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









