






数据仓库
数据仓库是企业发展到一定的阶段,现有的发展状况不能满足企业的需求,需要基于企业和行业历史数据来进行智能化的统计分析,通过分析挖掘出有价值的东西,为决策者或领导层提供科学的决策支持,用于改善企业的业务流程,运行成本,企业效益,提高客户的体验度。
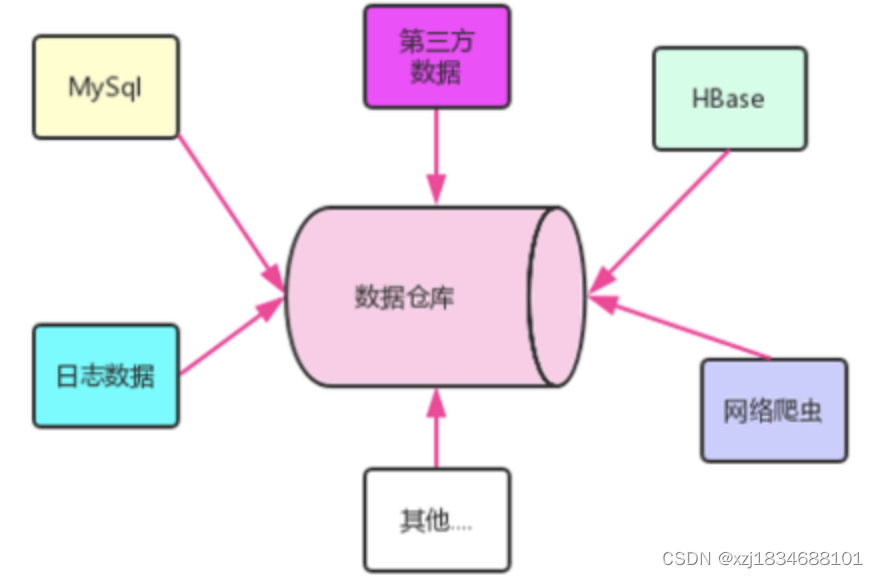
数仓中的数据是来自各种各样的数据源,为了分析,不择手段,只要有利于分析的数据,都可以集成到数仓中。
目前,我们可以认为数据仓库中的数据是来自于hdfs上的。
HDFS:文件 ------> 数仓管理工具 ------>数据库表 ------> HiveSql/SparkSql
主要特征
-
面向主题的(Subject-Oriented )
我们分析一般都是泛泛而谈,一定是由一个或者主题:销售角度、客户角度、商家角度、产品的角度,数仓中的数据一定是要划分主题的
-
集成的(Integrated)
数仓的数据可以来自各种四面八方的数据,都集成在一起,集成之后,数据之间会存在格式上的差异,我们通过ETL机制来消除这种差异
-
稳定的(Non-Volatile)
1、离线数仓中的数据都是历史数据(历史不容更改) 2、在下一个采集周期到来之前,数仓中的数据是不变的(HiveSQL不支持update和delete命令)
-
时变的(Time-Variant )
当下一个采集周期到来之前,数仓中的数据要及时的更新(T+1机制)
数仓和数据库的区别
数据库数据库的数据是面向业务,面向事务(OLTP)的,面向客户的,如果数据丢了,整个企业的业务就无法开展,数据库是为了让企业活下来
数据仓库是面向分析(OLAP)的,面向大数据工程师的,数据仓库是让企业活的更好
数据库一般是存放业务数据,数据状态都是最新的
数仓一般存放是历史数据,数据不是最新的
数据库的表在设计是避免出现冗余:ER图、 三大范式
数仓为了分析允许数据出现冗余,怎么便于分析就怎么来
数据库强调时效性,要求请求和响应之间的时间在毫秒级别
数仓具有延时性,一般处理过程比较长
数据库面向客户,必须保证安全性,一旦有问题就是大问题
数据仓库是面向内部人员,安全级别较低
关系
数仓的数据可以来自数据库 #数据分析为什么需要单独搞一个数仓,不在业务数据库上直接分析
1、业务数据库本身需要消耗服务器资源,数据分析不能去抢占业务的资源
2、数据库只是数仓其中一种数据源,数仓可以是多种数据源的集合
3、业务数据库就是为业务而生的,不具备很多大数据分析所需要的的体系结构
数仓的分层
数仓分层实际上描述的是数据在数仓中不同的处理阶段
数仓的分层没有统一的标准,每一个公司可能都不一样
通用的数仓分层
DA层/APP层 存放分析后的结果数据 数据结果
dw层 存放ods层预处理过的数据 数据干净 可以直接用于分析
DWS层
DWB层
DWD层
ods源数据层 存放最原始的结构化数据 数据原始

ETL概念
抽取(extract)
从数据源根据需求采集需要的指定数据:Sqoop 、Kettle、 Flume
转换(transform)
将抽取后的数据进行前期的分离处理,格式转换,字典表翻译、数据质量的空值
加载(load)
将转换后的数据加载数仓中
Hive的概述
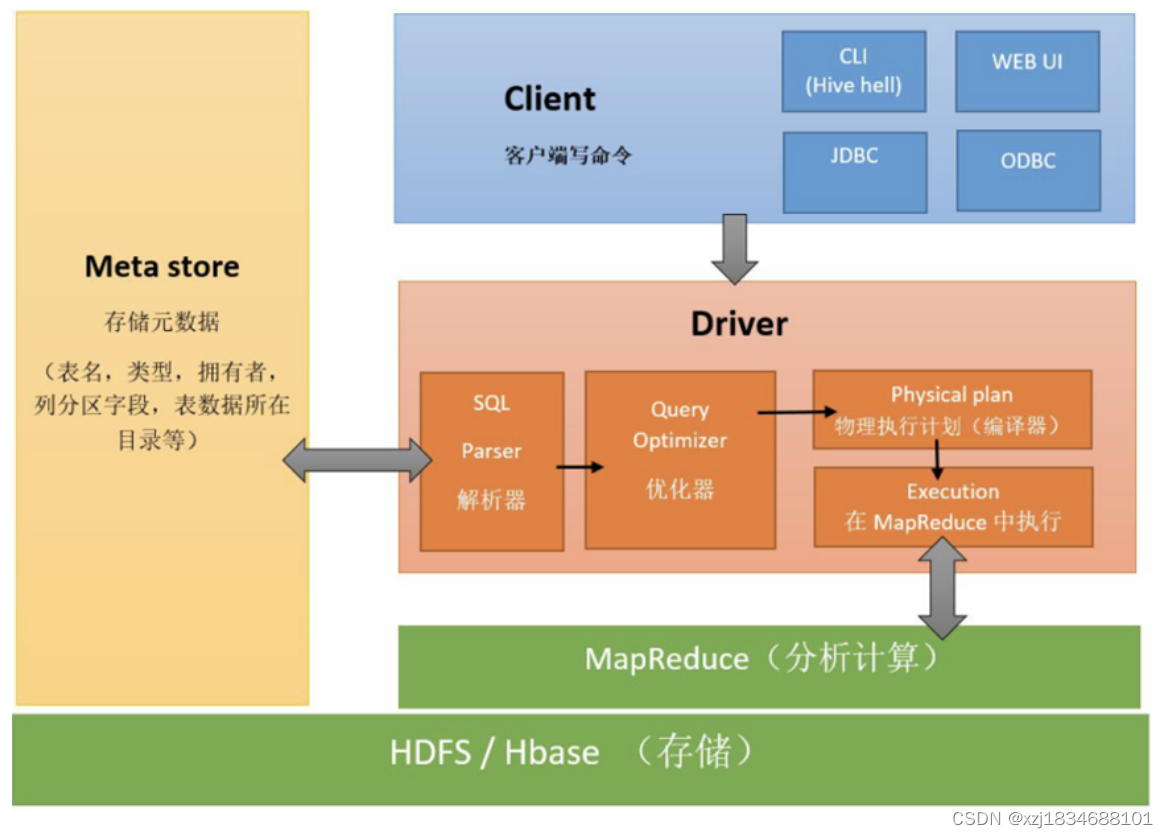
Hive是数仓管理工具,用来管理数仓
Hive可以将数仓存在HDFS上的文件变成一张张的表
Hive提供一种HiveSQL可以表进行分析处理
HiveSQL底层默认是MapReduce,以后可以换成其他的引擎(Spark),我们写HiveSQL会去匹配底层的MR模板,匹配上则执行,否则不能执行
Hive的特点
Hive本身只是一个工具,它不存任何数据: Hive的表数据存在HDFS上,Hive的元数据(表结构和HDFS文件之间的映射关系)存在第三方的数据库中(MySQL) select * from itheima_order_goods;
Hive底层引擎默认是MapReduce,你也可以换成其他引擎(Tez,Spark)















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









