






#博学谷IT学习技术支持#
1. Structured Streaming基本概述
Structured Streaming 是基于 Spark SQL 引擎构建的可扩展和容错流处理引擎. 基于Structured Streaming可以像对静态数据的批处理一样的进行流式计算操作. Spark SQL 引擎将负责以增量和连续的方式运行它,并随着流数据的不断到达而更新最终结果. 可以使用 Scala、Java、Python 或 R 中的Dataset/DataFrame API来表示流聚合、事件时间窗口、流到批处理连接等
计算在同一个优化的 Spark SQL 引擎上执行。最后,系统通过检查点和预写日志确保端到端的精确一次容错保证。简而言之,结构化流式处理提供快速、可扩展、容错、端到端的一次性流处理,用户无需对流式处理进行推理。
在内部,默认情况下,结构化流查询使用微批处理引擎处理,该引擎将数据流作为一系列小批量作业处理,从而实现低至 100 毫秒的端到端延迟和一次性容错保证. 但是,从 Spark 2.3 开始,Spark引入了一种新的低延迟处理模式,称为Continuous Processing,它可以实现低至 1 毫秒的端到端延迟,并保证至少一次。在不更改查询中的 Dataset/DataFrame 操作的情况下,能够根据应用程序要求选择对应的模式。
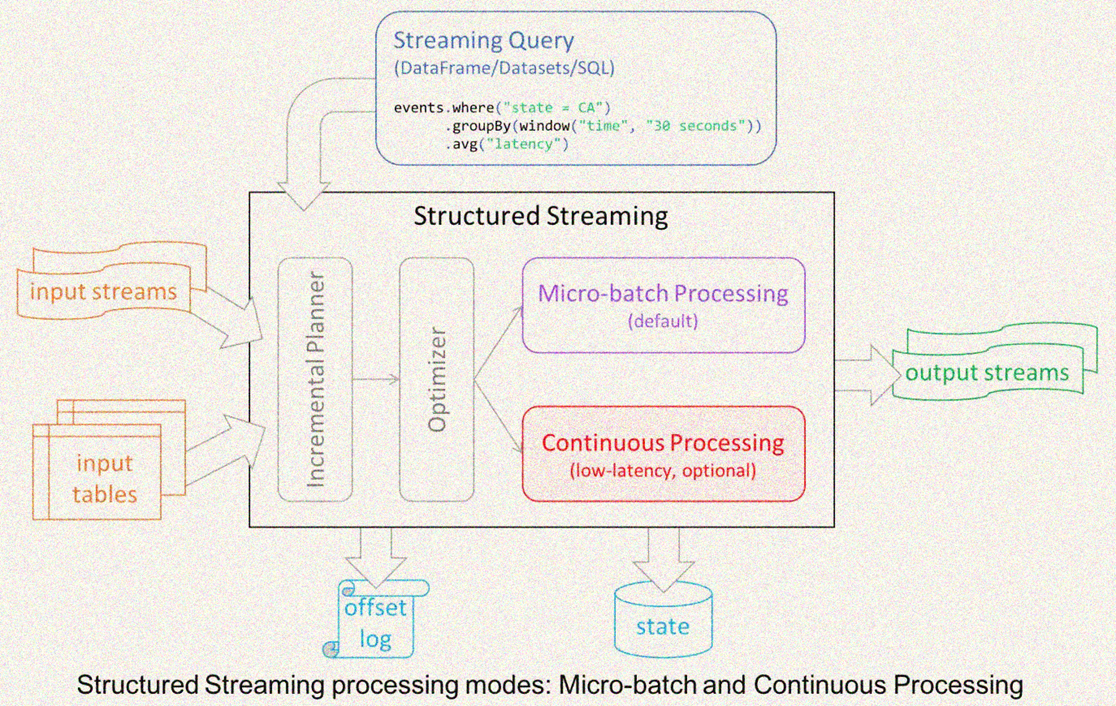

Structured Streaming 主要特点:
1- 增量查询模式(incremental query model):
Structured Streaming 将会在新增的流式数据上不断执行增量查询,同时代码的写法和批处理 API(基于Dataframe和Dataset API)完全一样,而且这些API非常的简单。
2- 支持端到端应用(Support for end-to-end application)
Structured Streaming 和内置的 connector 使的 end-to-end 程序写起来非常的简单,而且 "correct by default"。数据源和sink满足 "exactly-once" 语义,这样我们就可以在此基础上更好地和外部系统集成。
3- 复用 Spark SQL 执行引擎
Spark SQL 执行引擎做了非常多的优化工作,比如执行计划优化、codegen、内存管理等。这也是Structured Streaming取得高性能和高吞吐的一个原因。
2. Structured Streaming 入口案例
需求: 监听node1节点的9999的端口号, 从端口号中获取单词数据, 将其转换为DF进行单词统计
1- 构建SparkSession对象
说明: Structured Streaming 是基于 spark SQL的, 故也是采用统一的入口
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
importos
os.environ["SPARK_HOME"] = "/export/server/spark"
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()2- 构建一个支持流式的dataFrame, 监听 node1:9999, 将其转换为DF
lines_df = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()3- 基于DF进行数据处理即可: 此部分与spark SQL 是一致的
Words_df = lines_df.select(
explode(
split(lines.value, " ")
).alias("word"))
wordCounts_df = words_df.groupBy("word").count()4- 启动程序
query = Words_df \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
# 等待查询终止, 防止查询处于活动状态时进程退出
query.awaitTermination()测试:
在node1中安装nc命令, 开启9999连接, 写入数据操作
# 下载
yum -y install nc
# 连接9999端口, 即可发送数据
nc -lk 9999
可能出现的问题:

3.编程模型
Structured Streaming的模型十分简洁,易于理解。一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾,用户可以使用Dataset/DataFrame 或者 SQL 来对这个动态数据源进行实时查询。
如下图所示,通过将流式数据理解成一张不断增长的表,从而就可以像操作批的静态数据一样来操作流数据了。

在这个模型中,主要存在下面几个组成部分:
1:Input Table(Unbounded Table),流式数据的抽象表示,没有限制边界的,表的数据源源不断增加;
2:Query,对 Input Table 的增量式查询,只要Input Table中有数据,立即(默认情况)执行查询分析操作,然后进行输出(类似SparkStreaming中微批处理);
3:Result Table,Query 产生的结果表;
4:Output,Result Table 的输出,依据设置的输出模式OutputMode输出结果;

核心思想
Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项就像是表中的一个新行被附加到无边界的表中,用静态结构化数据的批处理查询方式进行流计算。
请注意,结构化流不会具体化整个表。它从流数据源读取最新的可用数据,增量处理以更新结果,然后丢弃源数据。它只保留更新结果所需的最小中间状态数据(例如前面示例中的中间计数)。
该模型与许多其他流处理引擎有很大不同。许多流系统要求用户自己维护正在运行的聚合,因此必须考虑容错性和数据一致性(至少一次,或最多一次,或精确一次)。在该模型中,Spark 负责在有新数据时更新 Result Table,从而减轻用户对它的推理。
3. Source数据源
Spark支持从各个数据源中读取数据, 从而转换为DF对象的操作, 目前spark内置的数据源主要有以下内容:
1- File Source(文件源、测试):
将写入目录中的文件作为数据流读取。文件将按照文件修改时间的顺序进行处理。如果latestFirst设置,顺序将被颠倒。支持的文件格式为文本、CSV、JSON、ORC、Parquet。
2- kafka Source(kafka 源) : 从kafka中读取数据 (后续讲解、生产可用)
3- Socket Source(测试):
4- Rate Source(速率源、测试):
以每秒指定的行数生成数据,每个输出行包含一个timestamp和value。wheretimestamp是Timestamp包含消息发送时间的类型,value是Long包含消息计数的类型,从0开始作为第一行。此源用于测试和基准测试
3.1 File Source(文件源)
将目录中写入的文件作为数据流读取,支持的文件格式为:text、csv、json、orc、parquet
option参数 | 描述说明 |
maxFilesPerTrigger | 每次触发时要考虑的最大新文件数 (默认: no max) |
latestFirst | 是否先处理最新的新文件, 当有大量文件积压时有用 (默认: false) |
fileNameOnly | 是否检查新文件只有文件名而不是完整路径(默认值:false) 将此设置为 `true` 时,以下文件将被视为同一个文件,因为它们的文件名“dataset.txt”相同: “file:///dataset.txt” “s3://a/dataset.txt " "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" |
需求说明: 监听某一个目录, 读取CSV格式的数据
测试数据
jack1;23;running
jack2;23;running
jack3;23;running
bob1;20;swimming
bob2;20;swimming
tom1;28;football
tom2;28;football
tom3;28;football
tom4;28;football代码实现:
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import os
os.environ["SPARK_HOME"] = "/export/server/spark"
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"
if __name__ == '__main__':
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
schema = StructType().add('name', StringType()).add('age', IntegerType()).add('hobby', StringType())
fileDf = spark.readStream.csv(path='file:///export/data/workspace/StructuredStreaming_Parent/data', schema=schema,
sep=';', header=False)
# 输出操作:
fileDf \
.writeStream \
.outputMode('update') \
.format('console') \
.option('truncate', 'false') \
.start() \
.awaitTermination()3.2 Rate Source(速率源) --了解
此数据源的提供, 主要是用于进行基准测试
option参数 | 描述说明 |
rowsPerSecond | 每秒应该生成多少行 : (例如 100,默认值:1) |
rampUpTime | 在生成速度变为rowsPerSecond之前应该经过多久的加速时间(例如5s,默认0) |
numPartitions | 生成行的分区号: (例如 10,默认值:Spark 的默认并行度) |
需求: 以每秒指定的行数生成数据,每个输出行包含2个字段:timestamp和value
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import os
os.environ["SPARK_HOME"] = "/export/server/spark"
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"
if __name__ == '__main__':
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
rateDf = spark.readStream.format('rate').option("rowsPerSecond","10").option('numPartitions',2).load()
rateDf.printSchema()
# 输出操作:
rateDf \
.writeStream \
.outputMode('update') \
.format('console') \
.option('truncate', 'false') \
.start() \
.awaitTermination()4.Operations: 操作
获得到Source之后的基本数据处理方式和之前学习的DataFrame、DataSet一致,不再赘述
DSL方式:

SQL的方式:

5. Sink相关内容
在StructuredStreaming中定义好Result DataFrame/Dataset后,调用writeStream()返回DataStreamWriter对象,设置查询Query输出相关属性,启动流式应用运行,相关属性如下:

输出模式
Spark提供了以下几种类型的输出模式:
append mode(默认): 这是默认模式, 只有自上次触发后添加到结果表的新行才会输出到接收器。这仅适用于那些添加到结果表中的行永远不会更改的查询。因此,此模式保证每行将仅输出一次(假设容错接收器)。例如,只有select, where, map, flatMap, filter,join等的查询将支持追加模式。
Complete mode(完整输出模式) : 每次触发后, 整个结果表都将输出到接收器, 仅支持聚合操作
Update mode(更新模式): 2.1.1版本后支持, 只有自上次触发后更新的结果表中的行才会输出到接收器
不同类型的流式查询支持不同的输出模式。这是兼容性矩阵。

输出终端/位置
以下为spark提供的内置输出接收器:
File Sink: 文件接收器, 将输出存储到目录 , 仅支持追加模式
可选项:
Path: 输出目录的路径,必须指定
retention: 输出文件的生存时间 (TTL)。提交的批次早于 TTL 的输出文件最终将被排除在元数据日志中。这意味着读取接收器输出目录的读取器查询可能不会处理它们。可以将值提供为时间的字符串格式。(如“12h”、“7d”等)默认情况下它是禁用的。
writeStream.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
Kafka Sink: 将输出存储到kafka中的一个或多个主题, 三种输出模式均支持
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()Foreach Sink和foreachBatch: 对输出中的记录运行任意计算 三种输出模式均支持
无参数
writeStream
.foreach(...)
.start()Console Sink: 用于调试, 每次有触发器时将输出打印到控制台/标准输出. 支持追加,完成和更新输出模式
可选参数:
numRows: 每个触发器打印的行数(默认:20)
Truncate: 如果太长,是否截断输出(默认:true)
writeStream
.format("console")
.start()Memory Sink: 输出作为内存表存储在内存中。支持追加和完成输出模式。 由于存储在内存中, 仅适用于小数据量, 慎重使用
无参数
writeStream
.format("memory")
.queryName("tableName")
.start()Foreach和ForeachBatch说明:
foreach和foreachBatch操作允许您在流式查询的输出上应用任意操作和编写逻辑。它们的用例略有不同——虽然foreach 允许在每一行上自定义写入逻辑,但foreachBatch允许在每个微批次的输出上进行任意操作和自定义逻辑。
ForeachBatch函数:
def foreach_batch_function(df, epoch_id):
# Transform and write batchDF
pass
streamingDF.writeStream.foreachBatch(foreach_batch_function).start() Foreach函数:
在 Python 中,您可以通过两种方式调用 foreach:在函数中或在对象中。该函数提供了一种简单的方法来表达您的处理逻辑,但不允许您在故障导致重新处理某些输入数据时对生成的数据进行重复数据删除。对于这种情况,您必须在对象中指定处理逻辑。
方式一:
def process_row(row):
# Write row to storage
passquery = streamingDF.writeStream.foreach(process_row).start() 方式二:
class ForeachWriter:
def open(self, partition_id, epoch_id):
# 进行初始化相关的操作
pass def process(self, row):
# 进程方法, 每次处理数据都会执行
pass def close(self, error):
# 关闭方法, 一般来说, 仅当JVM 或者python进程再中间崩溃的时候, 会被调度Pass
query = streamingDF.writeStream.foreach(ForeachWriter()).start()查询名称
可以给每个查询Query设置名称Name,必须是唯一的,直接调用DataFrameWriter中queryName方法即可:

触发间隔
触发器Trigger决定了多久执行一次查询并输出结果
触发类型 | 描述 |
unspecified (default) 不指定,默认方案 | 如果没有明确指定触发设置,则默认情况下,查询将以微批处理模式执行,其中微批处理将在前一个微批处理完成后立即生成。 |
Fixed interval micro-batches 固定间隔微批次 | 查询将以微批处理模式执行,其中微批处理将以用户指定的时间间隔启动。
|
One-time micro-batch 一次性微批量 | 仅执行一次, 在定期启动集群、处理自上一时期以来可用的所有内容然后关闭集群的情况下很有用。在某些情况下,这可能会显着节省成本。 |
Continuous with fixed checkpoint interval (experimental) 以固定检查点间隔连续, 目前为实验性 | 查询将以新的低延迟、连续处理模式执行, 不支持聚合操作 和固定时间间隔差不多,就是延迟更低了。 |
官方案例
# 默认触发器
df.writeStream \
.format("console") \
.start()
# 固定间隔微批次
df.writeStream \
.format("console") \
.trigger(processingTime='2 seconds') \
.start()
# 一次性微批
df.writeStream \
.format("console") \
.trigger(once=True) \
.start()
# 以固定检查点间隔连续
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()Trigger.Processing表示每隔多少时间触发执行一次,此时流式处理依然属于微批处理;
Trigger.Continuous为Spark 2.3以后新增的连续处理模式,但不成熟
使用默认的尽可能快的执行即可
检查点位置
在Structured Streaming中使用Checkpoint 检查点进行故障恢复。如果实时应用发生故障,可以恢复之前的查询的进度和状态,并从停止的地方继续执行。
如果设置了检查点位置,那么查询将所有进度信息(即每个触发器中处理的偏移范围)和运行聚合(例如词频统计wordcount)保存到检查点位置。检查点位置必须是HDFS或兼容文件系统
两种方式设置checkpoint local位置:
方式一: 基于DataStreamWrite设置
streamDF.writeStream.option("checkpointLocation", "path")
方式二: SparkConf设置
sparkConf.set("spark.sql.streaming.checkpointLocation", "path")检查点目录包含以下几个内容:

1、偏移量目录【offsets】:记录每个批次中的偏移量。为了保证给定的批次始终包含相同的数据,在处理数据前将其写入此日志记录。此日志中的第 N 条记录表示当前正在已处理,第 N-1 个条目指示哪些偏移已处理完成。
2、提交记录目录【commits】:记录已完成的批次,重启任务检查完成的批次与 offsets 批次记录比对,确定接下来运行的批次;
3、元数据文件【metadata】:metadata 与整个查询关联的元数据,目前仅保留当前job id
4、数据源目录【sources】:sources 目录为数据源(Source)时各个批次读取详情
5、数据接收端目录【sinks】:sinks 目录为数据接收端(Sink)时批次的写出详情
6、记录状态目录【state】:当有状态操作时,如累加聚合、去重、最大最小等场景,这个目录会被用来记录这些状态数据,根据配置周期性地生成.snapshot文件用于记录状态。
代码演示
演示OutputMode和Trigger和checkpoint
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split
from pyspark.sql.types import *
import os
os.environ["SPARK_HOME"] = "/export/server/spark"
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"
if __name__ == '__main__':
# 1. 构建sparkSession 对象
spark = SparkSession \
.builder \
.appName("structuredStreaming") \
.master("local[*]") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# 2. 设置source
lines_df = spark.readStream.format('socket').option('host', 'node1').option('port', 9999).load()
# 3. 对数据进行转换处理操作
Words_df = lines_df.select(
explode(
split(lines_df.value, " ")
).alias("word"))
wordCounts_df = Words_df.groupBy("word").count()
# 4. 输出
# 说明:
# append:只输出无界表中的新的数据,只适用于简单查询
# complete:输出无界表中所有数据,必须包含聚合才可以用
# update:只输出无界表中有更新的数据,不支持排序
# trigger(processingTime='5 seconds') : 每隔5s
# trigger(once=True): 开启仅进行一次微批处理
# trigger(continuous='5 seconds') # 每隔5s
wordCounts_df \
.writeStream \
.outputMode('complete') \
.format('console') \
.option('truncate', 'false') \
.trigger(processingTime='0 seconds') \
.option('checkpointLocation', 'hdfs://node1:8020/ckp') \
.start() \
.awaitTermination()













 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









