







程序运行效果图:
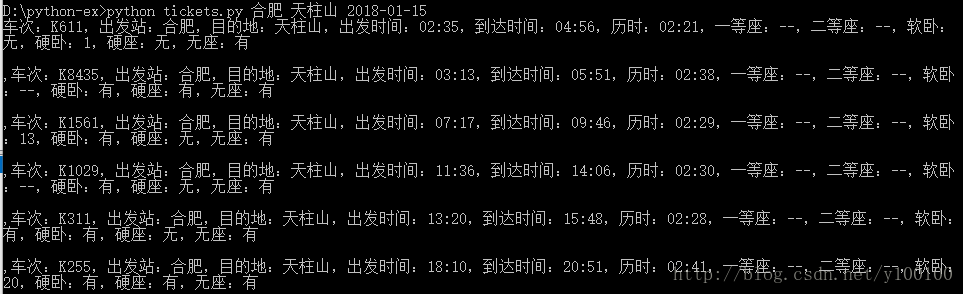
首先简单介绍下用到的2个重要的库:requests和docopt,可使用命令pip install requests docopt进行安装。
- requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。
- docopt 命令行参数解析库,docopt 本质上是在 Python 中引入了一种针对命令行参数的形式语言,需实现两个部分:1、在代码的最开头使用 """ """文档注释的形式写出符合要求的文档,就会自动生成对应的parse;2、在代码执行中加入
arguments=docopt(__doc__)。
通过分析12306的网站发现请求中的站点都是站点代码,所以先通过下列代码parse_stations.py得到站点名称:站点代码的列表,
执行:python parse_stations.py > stations.py 将打印结果重定向到stations.py文件中,方便后续调用
# -*- coding: utf-8 -*-
import re
import requests
from pprint import pprint
# 此url地址可以通过分析12306页面源码得到
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9044'
response = requests.get(url, verify=False) #利用requests发送get请求
# 此句得到的数据格式是[('北京北', 'VAP'), ('北京东', 'BOP'), ('北京', 'BJP'), ...]
# 使用正则表达式,([\u4e00-\u9fa5]+)至少一个汉字,([A-Z]+)至少一个大写字母
stations = re.findall('([\u4e00-\u9fa5]+)\|([A-Z]+)', response.text)
# 调用dict()后将格式转为字典{'北京北': 'VAP', '北京东': 'BOP', '北京': 'BJP', ...]
print(dict(stations))
1、由于stations中字典的key是站点名称,value是站点代码,而页面中查询结果使用的是站点代码,所以需要将此字典的key、value互换
new_stations = {v : k for k, v in stations.items()}# -*- coding: utf-8 -*-
""" 命令行火车票查看器
Usage:
tickets [-gdtkz] <from> <to> <date>
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets 北京 上海 2018-01-13
tickets -dg 成都 南京 2018-01-13
"""
import requests
import json
from docopt import docopt
# key:站点名称 value: 站点代码
from stations import stations
# 反转k,v形成新的字典,站点代码:站点名称
new_stations = {v : k for k, v in stations.items()}
def cli():
"""command-line interface"""
arguments = docopt(__doc__)
# python tickets.py -dg 合肥 天柱山 2018-01-13
# {'-d': True,
#'-g': True,
# '-k': False,
# '-t': False,
# '-z': False,
# '<date>': '2018-01-13',
# '<from>': '合肥',
# '<to>': '天柱山'}打印arguments得到一个字典
# print(arguments)
from_station = stations.get(arguments['<from>'])
to_station = stations.get(arguments['<to>'])
date = arguments['<date>']
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(date, from_station, to_station)
info_list = get_train_info(url)
print(','.join(info_list))
# resp = requests.get(url, verify=False)
# print(json.loads(resp.text)['data']['result'])
# print(resp.json()['data']['result'])
def get_train_info(url):
info_list = []
try:
resp = requests.get(url, verify=False)
raw_trains = resp.json()['data']['result']
for raw_train in raw_trains:
data_list = raw_train.split('|')
train_no = data_list[3]
# 起点站
from_station_code = data_list[6]
from_station_name = new_stations.get(from_station_code)
# 终点站
to_station_code = data_list[7]
to_station_name = new_stations.get(to_station_code)
start_time = data_list[8]
arrive_time = data_list[9]
time_fucked_up = data_list[10]
first_class_seat = data_list[31] or '--'
second_class_seat = data_list[30] or '--'
soft_sleeper = data_list[23] or '--'
hard_sleeper = data_list[28] or '--'
hard_seat = data_list[29] or '--'
no_seat = data_list[26] or '--'
info = '车次:{},出发站:{},目的地:{},出发时间:{},到达时间:{},历时:{},一等座:{},二等座:{},软卧:{},硬卧:{},硬座:{},无座:{}\n\n'.format(
train_no, from_station_name, to_station_name, start_time, arrive_time, time_fucked_up, first_class_seat,
second_class_seat, soft_sleeper, hard_sleeper, hard_seat, no_seat)
info_list.append(info)
return info_list
except:
return "输入信息有误,请重新输入!"
if __name__ == '__main__':
cli()















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









