







1 来源

paper地址:https://arxiv.org/abs/2202.12024
2 思想及用法

NoisyTune 的目标是更有效地对下游任务的 PLM 进行微调。 PLM 在一些带有一些自我监督任务的未标记语料库上进行了很好的预训练,它们可能会过度拟合这些预训练数据和任务,这通常与下游任务和数据存在差距。 PLM 可能难以有效地适应下游任务,尤其是当这些任务中的标记数据有限时。 如图 1 所示,我们建议在 PLM 的参数中添加一些噪声,然后在下游任务上对其进行微调,以在参数空间中进行一些“探索”,并降低过度拟合预训练任务和数据的风险。
PLM 通常具有不同类型的参数矩阵,例如查询、键、值和前馈网络矩阵。PLM 中的不同参数矩阵通常具有不同的特征和尺度。 例如,一些研究人员发现,Transformers 中的自注意力参数和前馈网络参数具有非常不同的属性,例如秩和密度。 因此,向 PLM 中的所有参数矩阵添加统一噪声可能不是保持其良好模型效用的最佳选择。 为了应对这一挑战,我们提出了一种矩阵扰动方法,该方法根据方差将不同强度的噪声添加到不同的参数矩阵中。

for name,para in model.named_parameters():
model.state_dict[name ][:] +=
(torch.rand(para.size())-0.5)*noise_lambda*torch.std(para)
结果展示
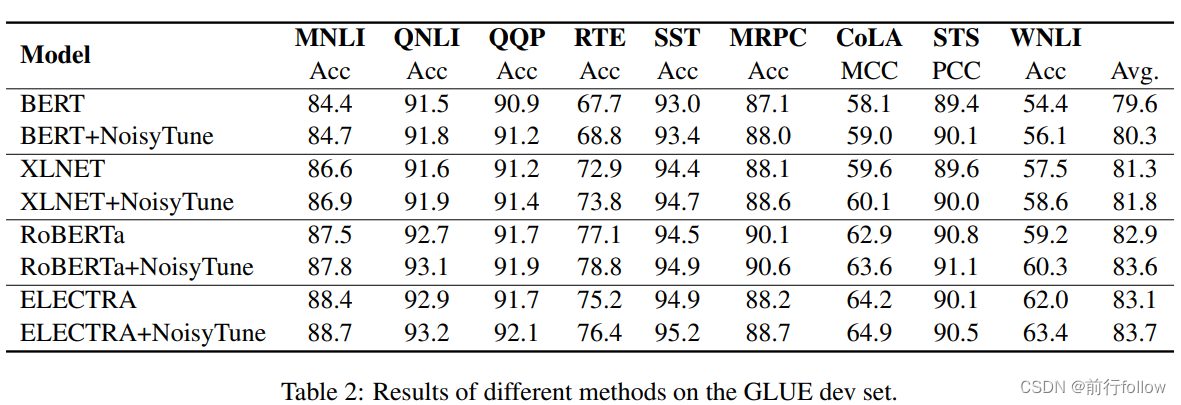
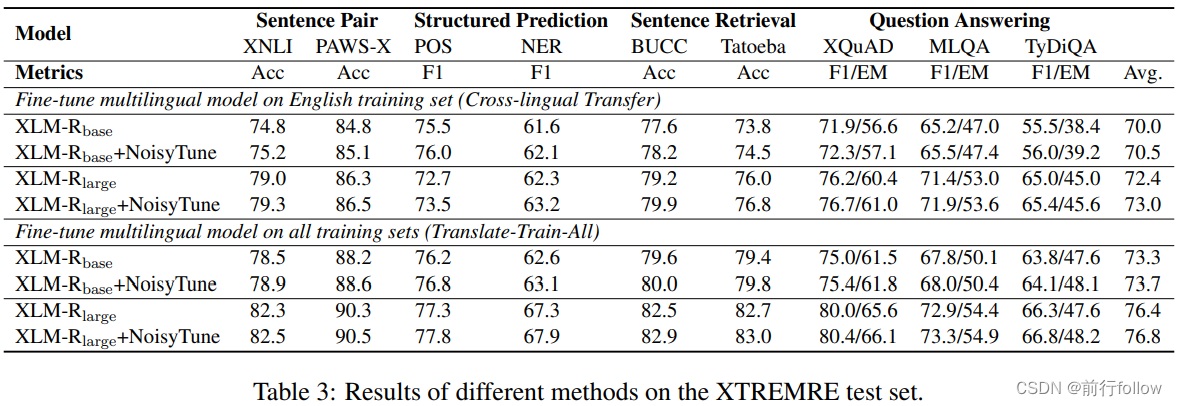














 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









