







误差选择均方误差
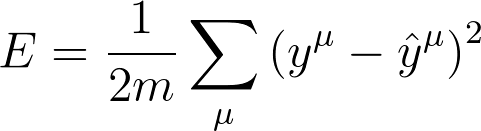
梯度下降步骤:

数据集为研究生学院录取数据,来源。
数据格式:
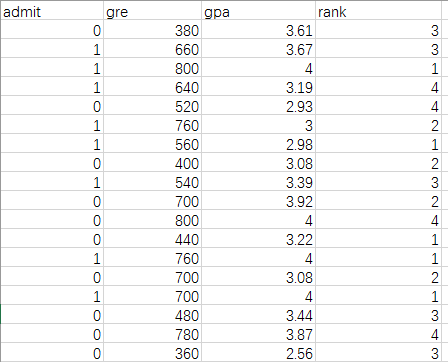
admit这一栏为标签,其余的栏目是特征。
网络没有设置隐层。
代码:
import pandas as pd
import numpy as np
admissions = pd.read_csv('binary.csv')
#把rank特征转换成one-hot
data = pd.concat([admissions, pd.get_dummies(admissions['rank'], prefix='rank')], axis = 1)
data = data.drop('rank', axis = 1)
#归一化
for field in ['gre', 'gpa']:
mean, std = data[field].mean(), data[field].std()
data.loc[:, field] = (data[field] - mean) / std
#划分测试集
np.random.seed(1)
sample = np.random.choice(data.index, size = int(len(data) * 0.9), replace = False)
data, test_data = data.ix[sample], data.drop(sample)
features, targets = data.drop('admit', axis = 1), data['admit']
featrues_test, targets_test = test_data.drop('admit', axis = 1), test_data['admit']
def sigmoid(x):
return 1 / (1 + np.exp(-x))
n_records, n_features = features.shape
last_loss = None
weights = np.random.normal(scale = 1 / n_features ** .5, size=n_features)
epoches = 5000
learn_rate = 0.5
for e in range(epoches):
del_w = np.zeros(weights.shape)
for x, y in zip(features.values, targets):
output = sigmoid(np.dot(x, weights))
error = y - output
del_w += error * output * (1 - output) * x
weights += learn_rate * del_w / n_records
if e % (epoches / 10) == 0:
out = sigmoid(np.dot(features, weights))
loss = np.mean((out - targets) ** 2)
if last_loss and last_loss < loss:
print("Train loss: ", loss, " loss increasing")
else:
print("Train loss: ", loss)
last_loss = loss
test_out = sigmoid(np.dot(featrues_test, weights))
predictions = test_out > 0.5
accuracy = np.mean(predictions == targets_test)
print('accuracy:%.3f'%accuracy)















 2206
2206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









