







简介
用pandas很容易读取Excel文件并将数据转换为DataFrame。然而现实世界中的Excel文件往往构造不佳,在那些数据散落在工作表中的情况下,你可能需要定制读取数据的方式。本文将讨论如何使用pandas和openpyxl来读取这些类型的Excel文件,并干净地将数据转换为适合进一步分析的DataFrame。
问题
pandas 的 read_excel函数在读取Excel工作表方面做得很好。然而,在数据不是从A1单元格开始的连续表格的情况下,结果可能不是你所期望的那样。
比如当你尝试使用 read_excel(src_file)读取下面这个电子表格样本。
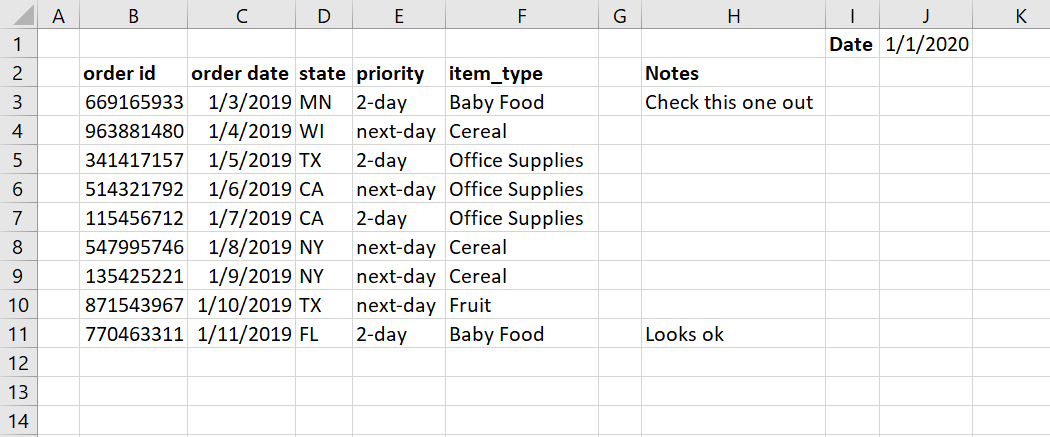
你会得到一些下面这样的东西。
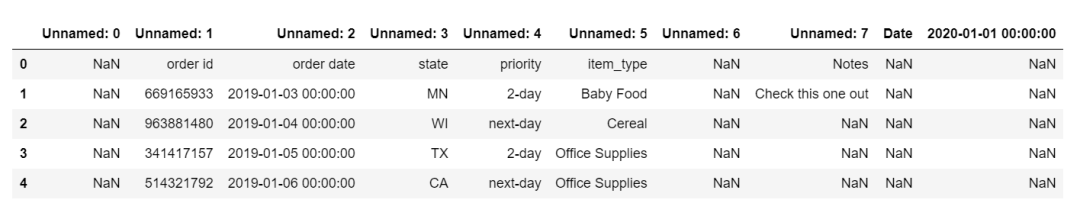
这些结果包括很多 Unnamed的列、行内的标题标签以及一些我们不需要的额外列。
Pandas解决方案
对于这个数据集,最简单的解决方案是使用 read_excel()的 header和 usecols参数。尤其是 usecols参数,对于控制你想包括的列非常有用。
如果你想继续学习这些例子,文件在github上。
-
https://github.com/chris1610/pbpython/blob/master/data/shipping_tables.xlsx
下面是一个替代方法,只读取我们需要的数据。
-
import pandas as pd -
from pathlib importPath -
src_file
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









