







 本文介绍了搜索引擎爬虫的四种抓取策略:宽度优先遍历、非完全PageRank、OCIP和大站优先策略。这些策略的目标是优先抓取重要网页,通过网页流行性和重要性指标来确定抓取顺序。宽度优先策略按链接顺序抓取;非完全PageRank策略基于局部PageRank计算;OCIP策略是一种快速计算重要性的方法;大站优先策略侧重大型网站的网页。
本文介绍了搜索引擎爬虫的四种抓取策略:宽度优先遍历、非完全PageRank、OCIP和大站优先策略。这些策略的目标是优先抓取重要网页,通过网页流行性和重要性指标来确定抓取顺序。宽度优先策略按链接顺序抓取;非完全PageRank策略基于局部PageRank计算;OCIP策略是一种快速计算重要性的方法;大站优先策略侧重大型网站的网页。
爬虫的不同抓取策略,就是利用不同的方法确定待抓取URL队列中URL优先顺序的。
爬虫的抓取策略有很多种,但不论方法如何,基本目标一致:优先选择重要网页进行抓取。
网页的重要性,评判标准不同,大部分采用网页的流行性进行定义。
效果较好或有代表性的抓取策略:
1、宽度优先遍历策略
2、非完全PageRank策略
3、OCIP策略
4、大站优先策略
1、宽度优先策略(Breath First)
基本思想:将新下载网页包含的链接直接追加到待抓取URL队列末尾。
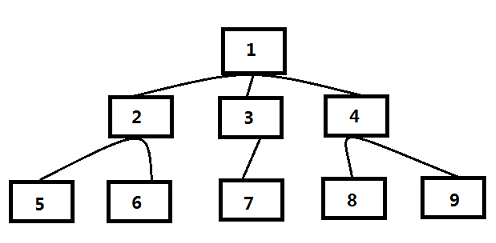
上图即为此策略示意图:
假设队头的网页是1号网页,从1号网页中抽取出3个链接指向2号、3号和4号网页,于是按照编号顺序依次放入待抓取URL队列,图中网页的编号就是在待抓取URL队列中的顺序编号,之后爬虫以此顺序进行下载。
实验表明,这种策略效果很好,虽然看似机械,但实际上的网页抓取顺序基本上是按照网页的重要性排序。之所以如此,有研究人员认为:如果某个网页包含很多入链,那么更有可能被宽度优先遍历策略早早抓到,入链个数从侧面体现了网页的重要性,即实际上宽度优先遍历策略隐含了一些网页优先级假设。
2、非完全PageRank策略(Partial PageRank)
基
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









