






问耕 郭一璞 发自 凹非寺
量子位 报道 | 公众号 QbitAI

记得神笔马良的故事么?
拿到神笔的马良,可以画物品、画动物、画食物,而且,这些画作都可以一秒钟从画面上出来,变成真实世界中存在的东西。
虽然这只是一个童话故事,不过,英伟达和MIT联手的最新研究,基本上马良的“神笔”造了个八九不离十。
来自英伟达和MIT的研究团队,最近搞出了迄今最强的高清视频生成AI。这个团队,包括来自英伟达的Ting-Chun Wang、刘明宇(Ming-Yu Liu),以及来自MIT的朱俊彦(Jun-Yan Zhu)等。
他们的成果到底有多强、多可怕?一起来看。
只要一幅动态的语义地图,你就可以获得和真实世界几乎一模一样的视频。换句话说,只要把你心中的场景勾勒出来,不用去实拍,电影级的视频就可以自动P出来,像下面一样:

这可不是在播放录像,街景中的道路、车辆、建筑、绿植都是自动生成的。原本只是简单勾勒景物轮廓的语义分割图,摇身一变就成了真实的街景。
真实的有点过分。
而且,还可以生成各种不同风格的视频:

甚至,它还能把街景改掉。比如把道路两侧的建筑全都变成树木,顿时有一种行驶在森林公园的感觉:

或者把行道树也给变成建筑,不过这些建筑倒是看起来有年头了:

随意的生成变化,就像偷来了哈利·波特的魔杖,无需咒语,就可以把这个场景中所有的元素变变变。
还有厉害的。
通过一个简单的素描草图,就能生成细节丰富、动作流畅的高清人脸:
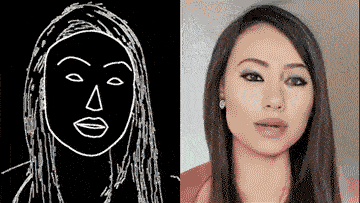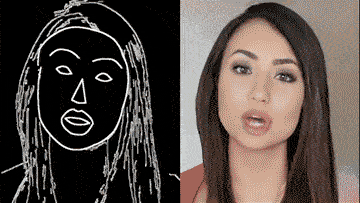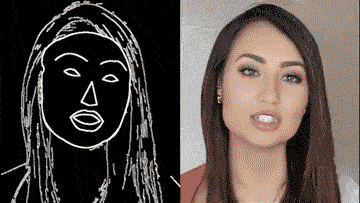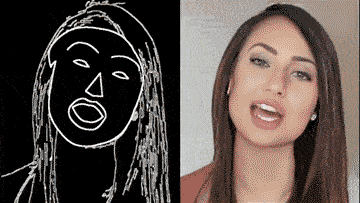
根据勾勒出的人脸轮廓,系统自动生成了一张张正在说话的脸,脸型、面部五官、发型、首饰都可以生成。
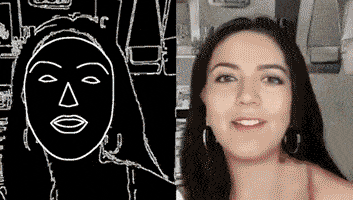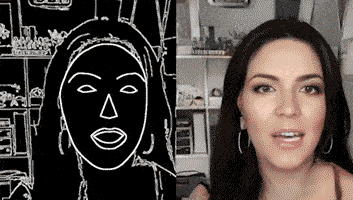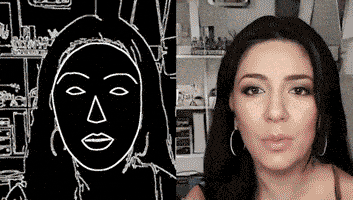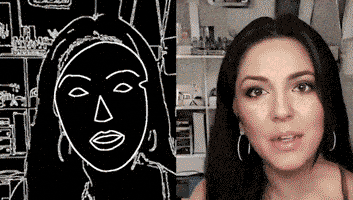
甚至还主动承担了给人脸绘制背景的任务。
除此之外,人脸的面色、发色也可以定制化选择,皮肤或深或浅,发色或黑或白,全都自然生成无压力:
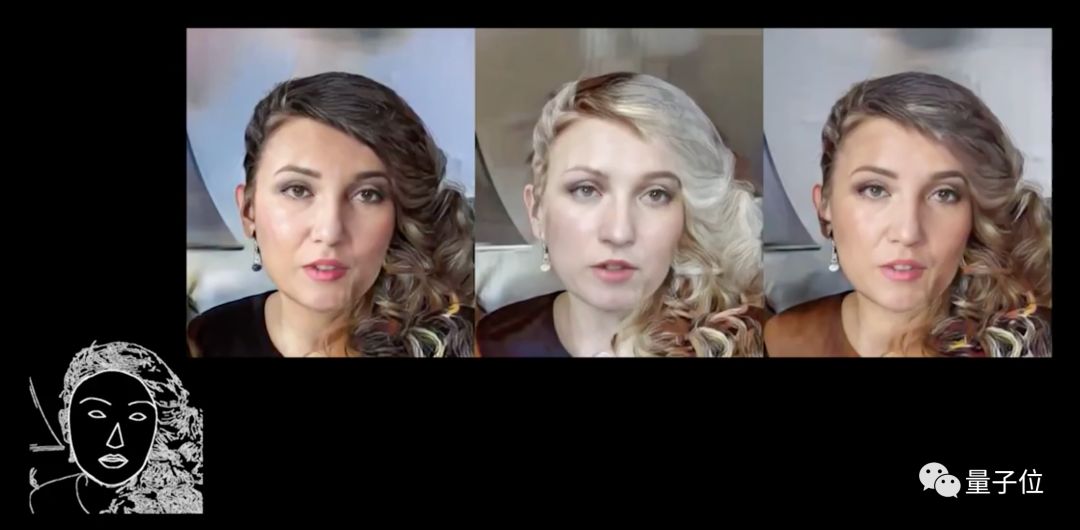

△ 面色红润style

△ 一脸苍白style

△ 脸色蜡黄style
简直就像同一个人染了头发拍了三遍,这种逼真的效果,真怕有一天朋友圈三无化妆品微商们拿去造假骗人。(当然,仔细看眉毛,还是有一些破绽)
不只人脸,整个身子都能搞定:

随着左侧人体模型的跳动、位移和肢体不断变换,右侧的真人视频中,主角也在随之舞蹈,无论你想要什么样的姿势,变高、变矮、变胖、变瘦,只要把左侧的人体模型调整一下,右侧的真人视频就会乖乖的听你调教。
与之前的研究相比,英伟达这个vid2vid的效果怎么样,大家一看便知。
这是2017年ICCV上的COVST的效果:

这是2018年CVPR上的pix2pixHD的效果:

而最新的效果是这样:

没有模糊,没有扭曲,没有异常的闪动,画面平稳流畅,色调柔和。如果应用在视频生产中,简直可以让抠图小鲜肉们一年拍10000部电影都不成问题。
最后,清晰的效果欢迎大家点开视频查看:
技术细节
这么NB的效果,是怎么实现的?
说下要点。
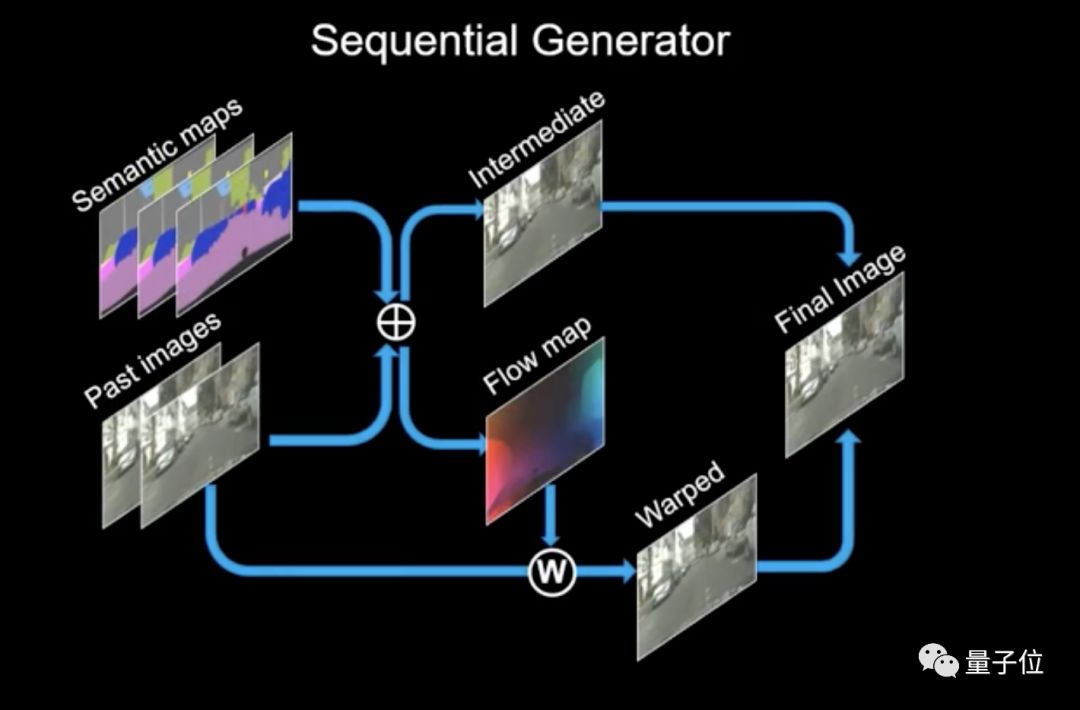
研究团队使用了序列生成器和多尺度鉴别器来训练神经网络。生成器接收输入映射和前序帧,然后生成中间帧和Flow map。Flow map用于处理前序帧,然后与中间帧合并,从而生成最终帧。
生成下一帧时,最终帧变成输入,以此类推。

鉴别器共有两种,一种处理图片,一种处理视频。
图片鉴别器同时获取输入图像和输出图像,并从多个特征尺度进行评估,这与pix2pixHD类似。视频鉴别器接收Flow maps以及相邻帧以确保时间一致性。
所有帧在进入鉴别器之前,还进行了下采样,这可以看做是时域中的多尺度。
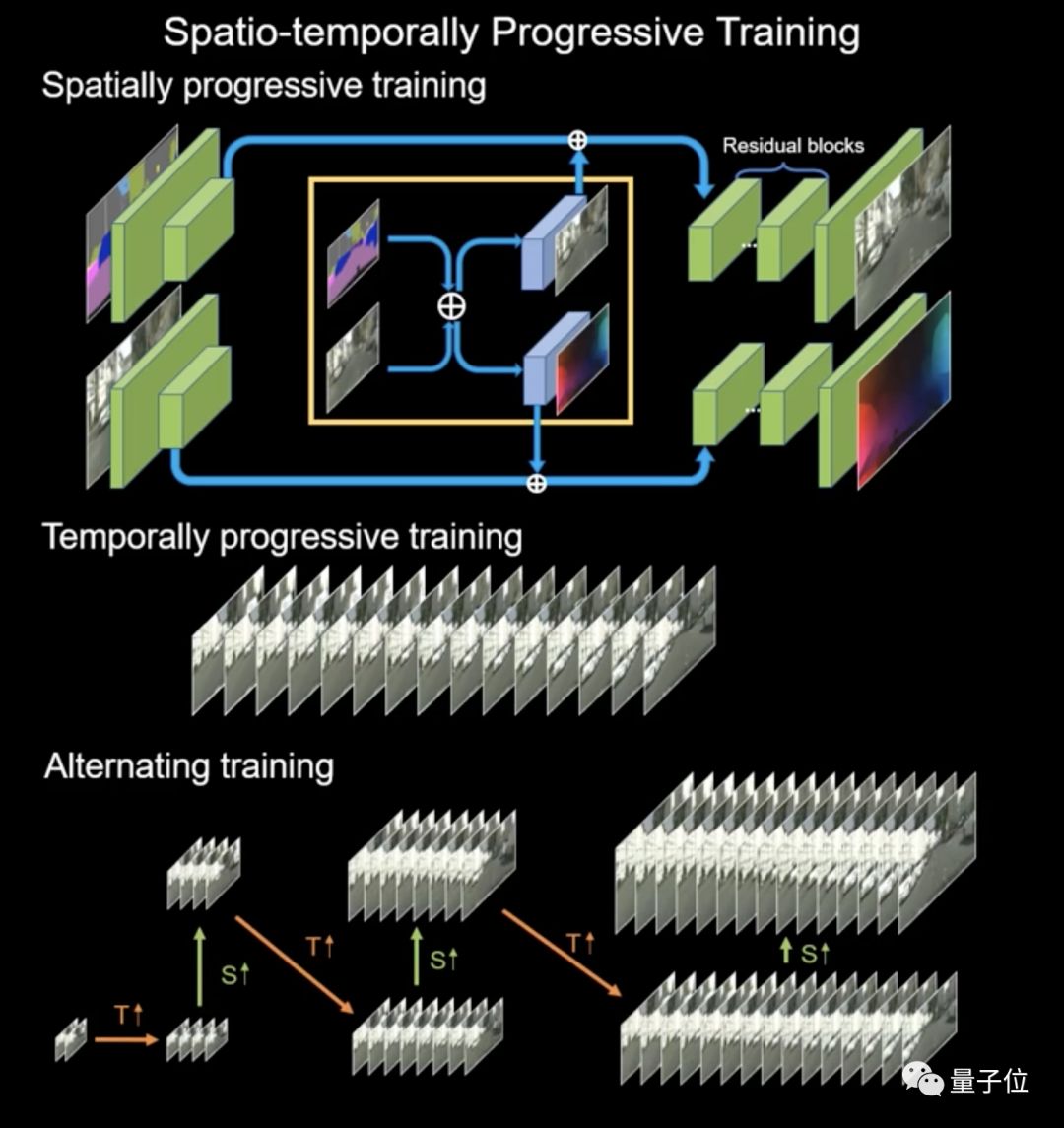
训练从低分辨率开始,然后结合低分辨率特征进行高分辨率的训练。同样,训练先从几帧开始,然后逐渐增加训练帧的数量。这两个步骤不断交替,形成渐进式的训练流程,最终让神经网络学会生成高分辨率和长时间的视频。
更多细节,可以从Paper中查看。
论文中表示,这是一种在生成对抗性学习框架下的新方法:精心设计的生成器和鉴别器架构,再加上时空对抗目标。这种方法可以在分割蒙版、素描草图、人体姿势等多种输入格式上,实现高分辨率、逼真、时间相干的视频效果。
这种新方法训练出来的模型,能够生成长达30秒的2K分辨率街景视频,显著提升了视频合成的技术水平,而且这个方法还能用来预测未来的视频发展。
论文传送门:
https://tcwang0509.github.io/vid2vid/paper_vid2vid.pdf

代码
好消息是,相关代码也已经在GitHub上公布。
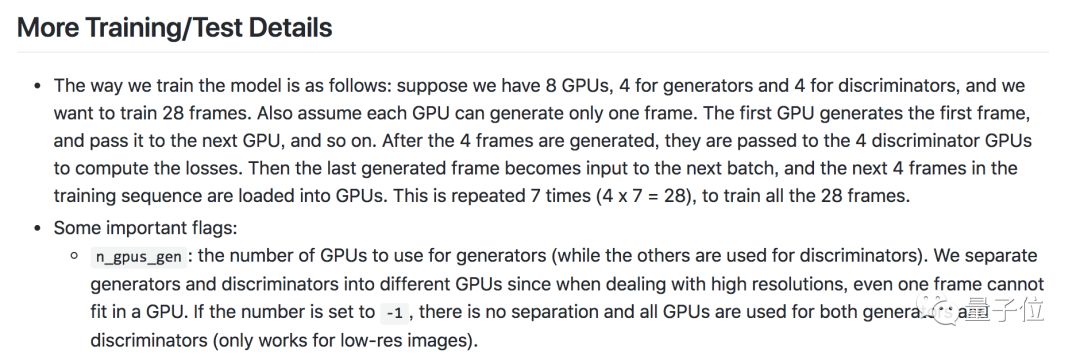
而且研究团队给出了详细的训练指南,可以算是手把手教你如何自己训练出一个类似的强大神经网络。
包括用8个GPU怎么训练,用1个GPU又该怎么设置等等。
你所需要准备的是,一个Linux或者macOS系统,Python 3,以及英伟达GPU+CUDA cuDNN。
GitHub页面传送门:
https://github.com/NVIDIA/vid2vid
— 完 —
活动推荐

加入社群
量子位AI社群19群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态














 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









