







此文是斯坦福大学,机器学习界 superstar — Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记。力求简洁,仅代表本人观点,不足之处希望大家探讨。
课程网址:https://www.coursera.org/learn/machine-learning/home/welcome
Week 9 后半部分 Recommender Systems:http://blog.csdn.net/ironyoung/article/details/49340133
Week 9:
异常检测 & 高斯分布
异常检测是一种介于监督学习与非监督学习之间的机器学习方式。一般用于检查大规模正品中的小规模次品。根据单个特征量的概率分布,从而求出某个样本正常的概率,若正常的概率小于阈值,即 p(x)<ϵ 视其为异常(次品)。正品与次品的 label 值 y 定义为:
y={01if p(x)≥ϵif p(x)<ϵ
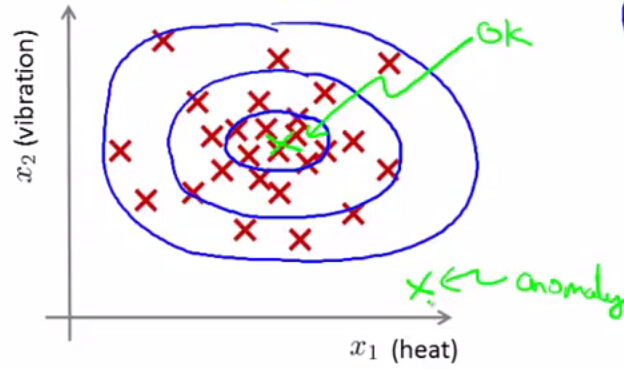
如果某个样本由 x1,x2 两个变量决定,如下图红色叉所示:
同一个圆圈内部,表示的是成为正品的概率相同。越中心的圆圈内部正品率越高。越外层的圆圈内正品率越低。异常检测一般将每个特征量的分布假设为正态分布(如果特征量与正态分布差距很大,之后我们会提到方法对其进行修正)。为什么是正态分布?因为在生产与科学实验中发现,很多随机变量的概率分布都可以近似地用正态分布来描述(猜测正确的概率更大)。因此,以下稍微介绍一下正态分布的基础知识,如果很熟悉的同学可以略过这部分。
正态分布(高斯分布),包含两个参数:均值 μ (分布函数取峰值时所对应横坐标轴的值),与方差 σ2 (标准差为 σ ,控制分布函数的“胖瘦”)。如果变量 x 满足于正态分布,将其记为
x∼N(μ,σ2) 。而取某个 x 的对应正品概率为:p(x)=12π√σe−(x−μ)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9374
9374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









