







评价门槛
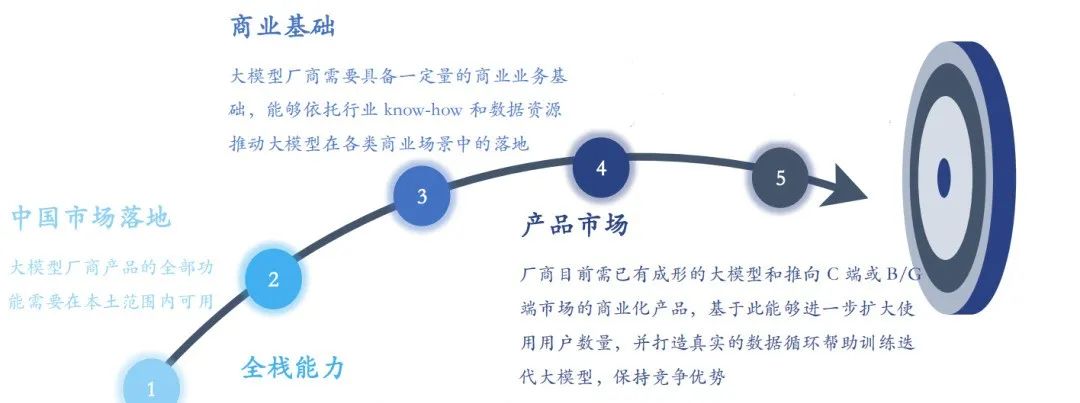
本次竞争力评估模型设定了四项核心基准,包括“中国市场适应性”“技术能力全面性”“商业实力”以及“产品市场竞争力”。只有同时符合这四个基准的大模型提供商,方能进入我们的竞争力评估范围。
中国市场适应性:考虑到海外大模型提供商如OpenAI、谷歌和Meta等在中国市场的服务尚未官方落地,其产品和服务体系以及生态环境建设在中国均存在明显的短板。通过非官方渠道使用这些服务的企业,将面临不可忽视的风险。相对而言,接入本土研发及自主创新的大模型显得更为稳妥、可靠且易于掌控。
技术能力全面性:在评估大模型服务时,我们重视提供商在从算力基础建设、深度学习架构到算法优化等全链条的技术解决方案能力,及其在工程化实施和运营管理方面的实绩。因此,合格的提供商需展示其全方位的技术实力,包括但不限于自建且独立运营的算力基础、卓越的算法设计等。
商业实力:除了技术层面的持续投入,大模型提供商还需展现其将大模型技术有效融入现有业务、提升行业认知和应用理解的能力,以确保在应对市场突变和技术革新时能保持稳健的发展态势。
产品市场竞争力:在日益激烈的市场竞争中,提供商必须已经开发出成熟的大模型产品,并具备商业化运营的能力,以抢占市场先机。同时,通过不断收集和分析用户反馈及行业数据,来持续优化和提升大模型的性能。
综合竞争力评价的四大基线
评价模型及指标体系
三方维度诠释主要厂商综合竞争力
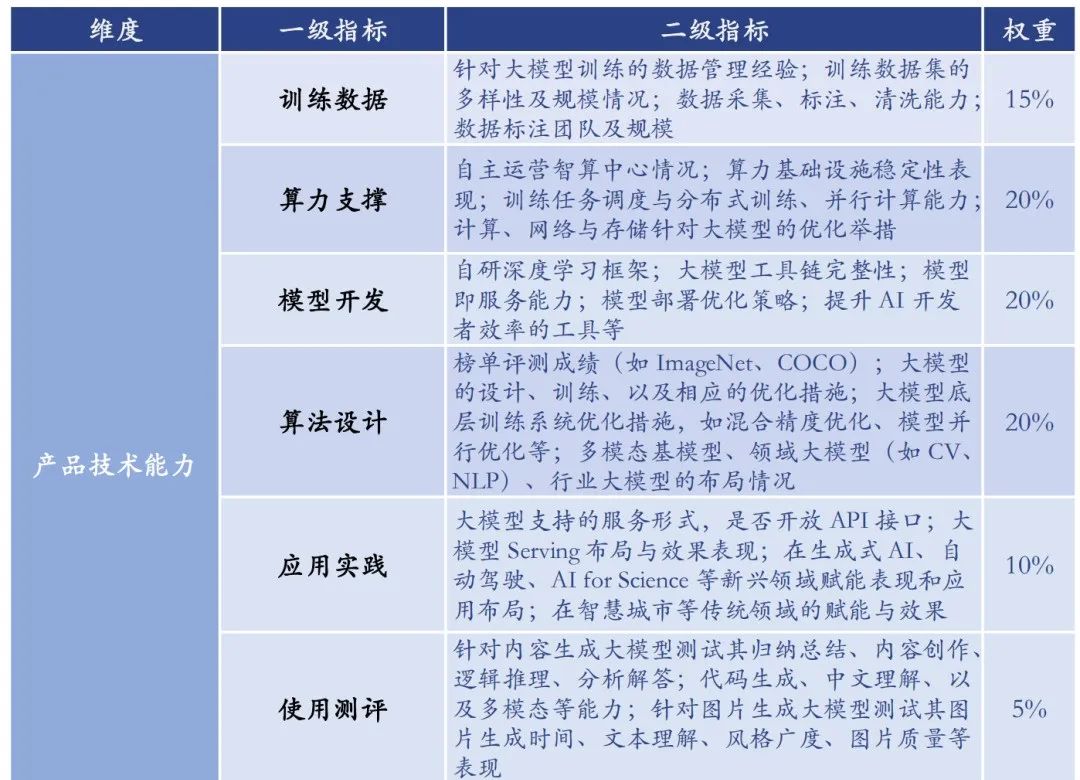
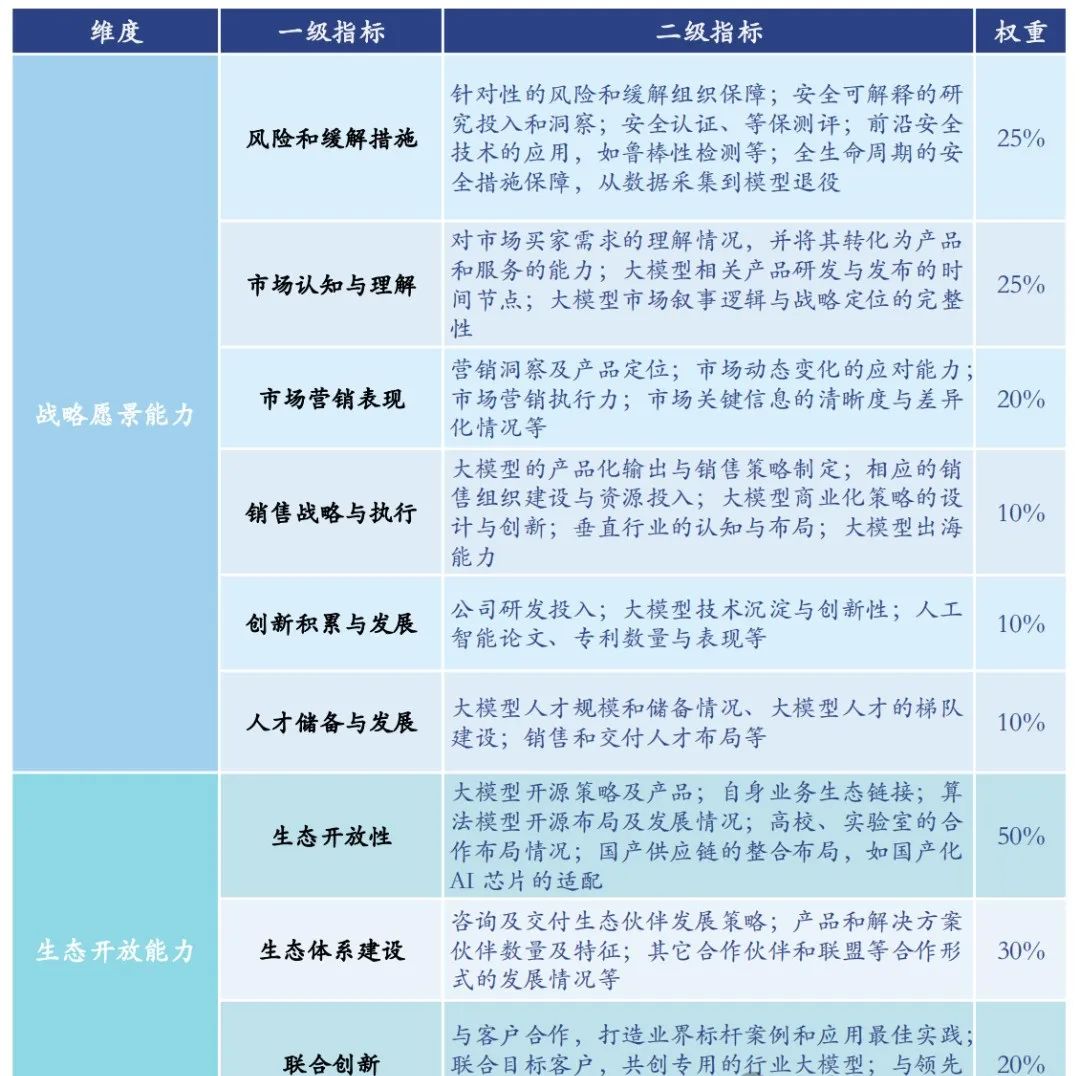
产品技术能力:AI大模型的性能和应用效果受多个因素影响,其中训练数据的质量和数量、算力对模型开发的支撑等都起到了决定性作用。产品技术能力越强,意味着该厂商在大模型的底层技术研发上更为扎实,其应用服务也相应地表现出更高的水准。这种能力是保证AI大模型在实际应用中稳定、高效运行的关键。
战略愿景能力:这一指标通过评估风险应对策略、对市场的深入认知和理解等方面来衡量大模型厂商的战略远见。战略愿景能力的评分越高,表明该厂商不仅关注当前的市场和技术动态,还有长远的发展规划和应对未来挑战的准备。这种能力有助于厂商在快速变化的市场环境中保持领先。
生态开放能力:主要从生态的开放性、生态体系的建设以及与其他企业或机构的联合创新能力来评价大模型厂商的生态实力。生态开放能力越强,反映出该厂商更愿意与外界合作,其大模型的开放程度更高,更能够促进产业内的协作和创新。这种能力对于推动整个AI产业的发展和进步具有重要意义。
评价模型及指标体系
三方维度诠释主要厂商综合竞争力
评价模型及指标体系
部分指标中的厂商基本情况
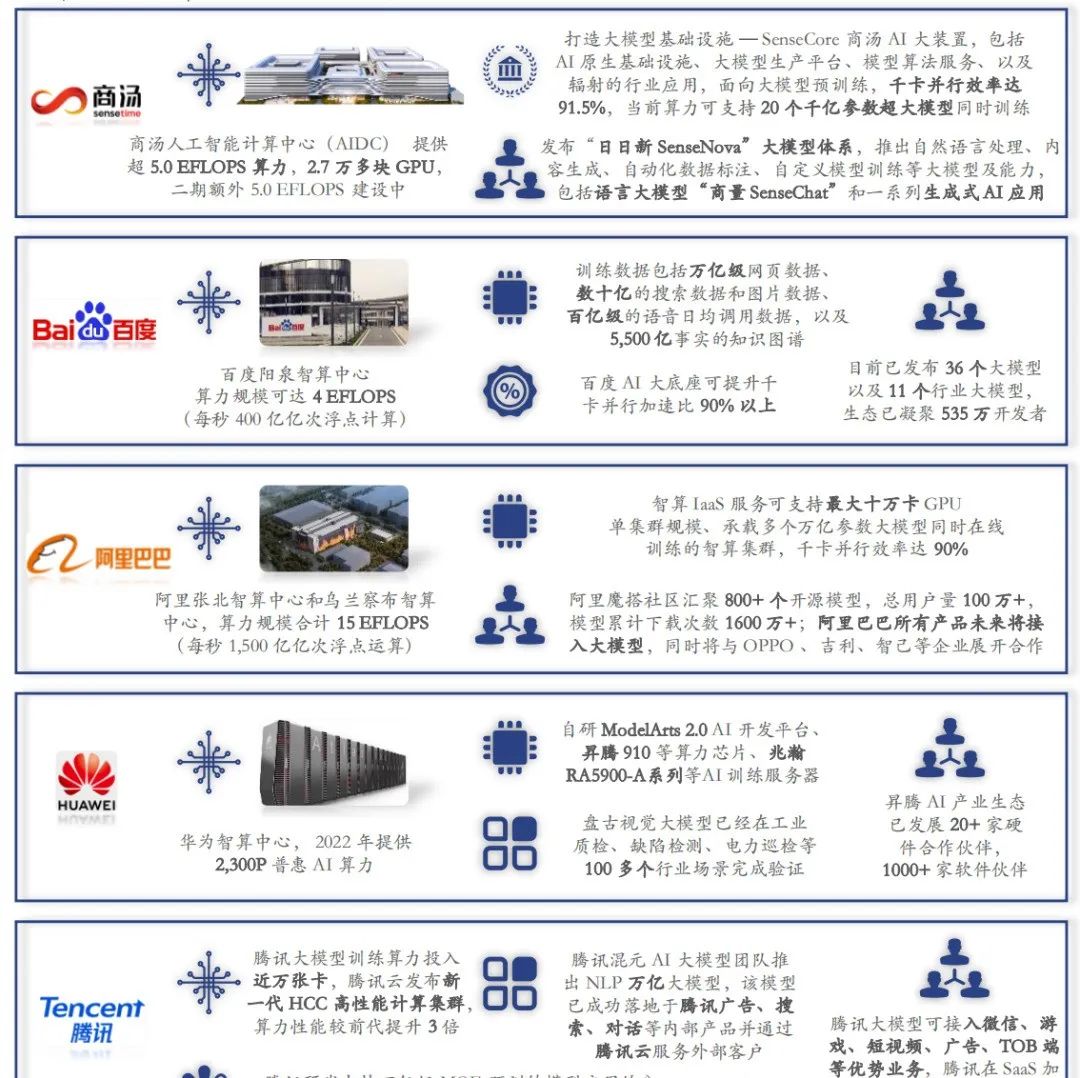
综合竞争力表现
• 本报告将根据最终评价的 AI 大模型在产品技术能力、战略愿景能力、生态开放能力三个维度的综合表现对比相关厂商在 AI 大模型领域的综合竞争力

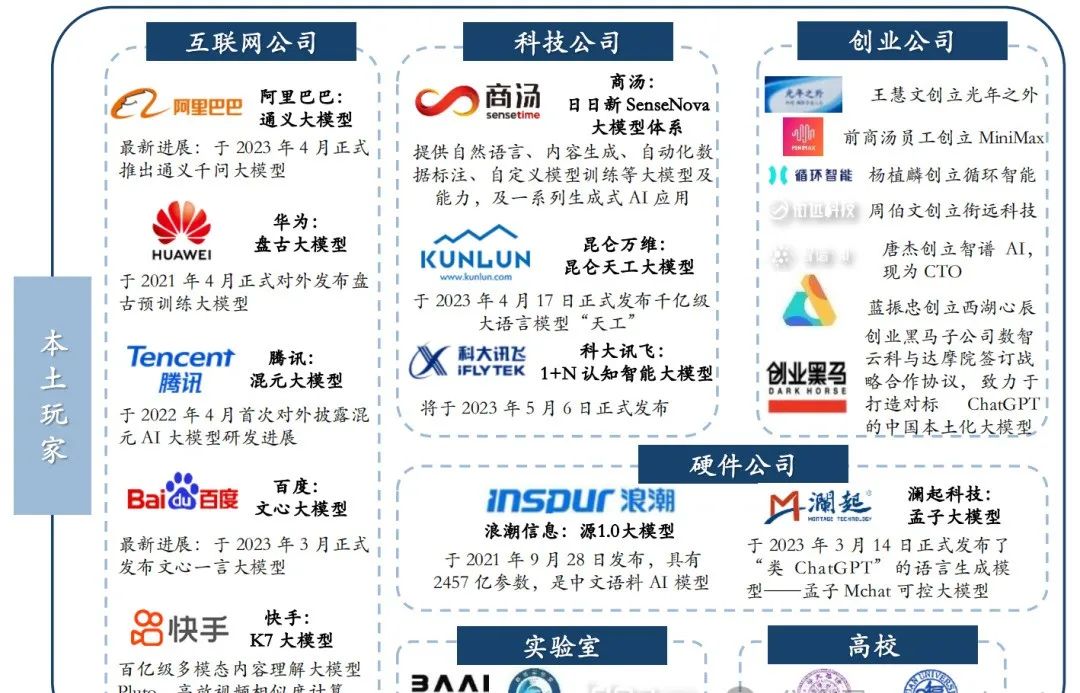
中国主要 AI 大模型厂商介绍
商汤:SenseCore 商汤 AI 大装置 + 商汤日日新 SenseNova大模型体系
◼ 从基础设施到模型研发的全栈能力
基于“大模型+大装置”的技术路径,商汤推进 AGI 为核心的发展战略。
商汤科技领先发布了名为“日日新SenseNova”的大模型体系,这一体系提供了包括自然语言处理、内容生成、自动化数据标注以及自定义模型训练等多项功能。通过与决策智能大模型的结合,该体系为实现通用人工智能(AGI)奠定了重要基础。除了语言大模型“商量SenseChat”外,商汤还推出了一系列生成式AI模型,如“如影SenseAvatar”用于2D/3D数字人生成,“琼宇SenseSpace”针对大场景生成,“格物SenseThings”专注于小物体生成,以及“秒画SenseMirage”用于文生图创作。
在过去的五年里,商汤投入巨资建设了AI大装置,这是国内罕见的大模型建设基础设施,旨在为AGI时代的到来奠定坚实基础。基于这一大装置,商汤成功打造了大模型生产的核心平台。该平台不仅支持了日日新大模型体系的内部开发,还具备对外提供大模型训练赋能的服务能力,涵盖从工程开发到生产部署的全过程。截至目前,该平台已经成功服务了8家大型客户,展现了商汤在AI领域的深厚实力和广泛影响力。
◼ 具有前瞻性的开放生
商汤开源了多模态多任务大模型“书生2.5”,这款模型拥有30亿参数,不仅在全球开源模型中达到了ImageNet的最高准确度,同时也是规模最大的模型。值得一提的是,在物体检测的标杆数据集COCO中,“书生2.5”是唯一一个超过65.0mAP的大模型,展现了卓越的性能。
为了与业界共享创新成果,商汤还构建了包括OpenMMLab、OpenDILab、OpenXRLab和OpenPPL在内的开源算法框架体系。这些开源框架为开发者提供了丰富的工具和资源,推动了AI技术的普及和发展。
此外,商汤还积极与国产芯片厂商合作,致力于提高GPU的训练能力。双方已合作上线了大模型推理服务,并成功攻关千卡国产训练集群。目前,商汤的大装置已经完成了58款国产芯片的适配与应用,这不仅提升了商汤的技术实力,也为国产芯片产业的发展注入了新的活力。
总的来说,商汤在AI领域取得了显著的成果,不仅推动了开源模型和算法框架的发展,还积极与国产芯片厂商合作,共同推动AI和芯片产业的进步。
商汤大模型发展关键事件时间点

商汤日日新自研大模型体系

中国主要 AI 大模型厂商介绍
商汤:SenseCore 商汤 AI 大装置 + 商汤日日新 SenseNova 大模型体系
◼ 体系化研发能力下产业应用积累
商汤科技在人工智能领域展现了卓越的大模型研发实力,从底层训练系统到算法设计优化,形成了一套完整的研发体系。其中,商汤研发的Uni-Perceiver技术独具特色,它能够兼容多种解码建模方式,将各类模态的数据巧妙地编码到一个统一的表示空间中,实现了不同任务范式的统一处理。这种技术使得商汤能够以一个通用的架构和共享的模型参数,灵活地应对各种模态和任务的处理需求。
商汤还积极采用前沿的大模型结构设计,并辅以大batch训练优化算法,显著提升了模型的性能。以“秒画SenseMirage”为例,该模型的参数量远超Stable Diffusion,不仅在文本理解泛化性方面表现优异,还在图像生成风格的多样性和图像生成的细节质量上实现了显著提升。
在提供服务方面,商汤通过API接口向外界提供强大的大模型服务,同时,这些大模型也成为推动商汤自身业务创新和效率提升的重要驱动力。特别是“商量SenseChat”,它不仅具备进行多轮对话和超长文本理解的能力,还支持编程助手功能,为开发者在编写和调试代码方面提供了极大的便利,展现了多样化的创新应用。
此外,商汤充分发挥大模型的能力,全面赋能其业务体系,特别是在智慧商业、智慧城市、智慧生活和智能汽车这四大关键领域,积极构建以AGI为核心的能力。目前,商汤的超大模型已经深入渗透到公司的核心业务中,成功在20多个应用场景中交付了大模型,同时有5个以上的项目已经进入了生产Serving阶段。
商汤大模型产业布局与应用场景积累
商汤大模型的体系化研发能力

百度:AI 大底座+文心大模型
◼ 产业级知识增强大模型,夫嫩行业大模型发展
百度文心大模型不仅源于产业实践,更是服务于产业发展的关键力量,它代表着产业级的知识增强大模型。通过与国产深度学习框架的深度融合和创新发展,百度成功构建了具有自主知识产权的AI基础平台,从而显著降低了AI技术的开发和应用难度。
文心大模型的核心特点之一是“知识增强”。百度自主研发了多源异构知识图谱,这一图谱汇集了超过5500亿条的专业知识,并被巧妙地融入到文心大模型的预训练过程中。这种融合不仅丰富了模型的知识库,还提升了其理解和应对复杂任务的能力。
得益于海量的数据和大规模知识的联合学习,文心大模型在效率、效果和可解释性方面都实现了显著的提升。它能够更加迅速地处理任务,提供更精准的结果,并且其决策过程也更具透明度,这使得文心大模型在多个产业领域中都有着广泛的应用前景。通过这种方式,百度文心大模型不仅推动了AI技术的进步,也为产业发展注入了新的活力。
◼ 大模型架构分三层体系
百度文心通过构建三层体系,即文心大模型层、工具与平台层、产品与社区层,打造了一个全面而高效的AI生态系统。
在文心大模型层,百度建设了基础、任务和行业三层大模型体系,旨在更适配不同场景的需求。目前,文心已经成功建设了36个大模型,这些模型针对不同领域和任务进行了优化,能够提供更为精准和高效的解决方案。
在工具与平台层,百度提供了文心API以及EasyDL和BML开发平台,这些工具为应用开发者提供了全流程的支持。通过这些工具,开发者可以轻松地调用和应用文心大模型,从而大大降低了AI应用的门槛。无论是初学者还是专业人士,都能通过这些工具快速上手,实现自己的AI应用。
最后,在产品与社区层,百度新增了“文心一格”、“文心百中”和旸谷社区等产品与社区。这些产品和社区不仅让更多人能够零距离感受到先进的AI大模型技术带来的新体验,还为开发者提供了一个交流和分享的平台。在这里,人们可以共同探讨AI技术的发展趋势,分享自己的应用经验,推动AI技术的普及和进步。
总的来说,百度文心通过构建三层体系,实现了从大模型建设到应用落地的全流程支持,让更多人能够轻松接触和应用AI技术,推动了AI技术的普及和发展。
百度文心大模型全景图
_
_
百度:AI 大底座+文心大模型
◼ 飞桨平台助力大模型落地
预训练大模型市场目前正处于迅猛发展的阶段,面临着不同开发者和企业在差异化需求下的应用挑战。百度飞桨深度学习平台通过向下兼容多种硬件,为文心大模型的开发、高性能训练、模型压缩及服务部署等提供了全方位的支持,从而打通了整个AI产业链,并构建了一个全栈化的产业生态体系。
百度飞桨与文心大模型的结合,形成了一个强大的生态共享系统。在这个生态中,文心大模型作为飞桨模型库的关键组成部分,不仅丰富了飞桨的模型资源,还通过共享生态,为开发者和企业提供了更多的选择和可能性。
文心大模型所包含的产业级知识增强大模型体系,结合工具平台、API和创意社区,为整个生态注入了强大的活力和创新力。这种全面的生态支持,使得开发者和企业能够更高效地应对差异化的应用需求,推动AI技术的广泛应用和发展。
同时,百度飞桨作为国产开发框架的代表,已经在与产业的深度融合中展现出其强大的实力和影响力。在社区生态建设上,百度飞桨持续发力,通过丰富的活动、培训和支持,吸引和培养了大量的开发者和企业用户,进一步巩固了其在AI领域的领先地位。
文心大模型与飞桨深度学习平台的关系

区助力大模型的高效应用。飞桨深度学习平台能助力解决大模型研发和部署的各类问题,大模型使得 AI 模型的研发门槛更低、效果更好、流程更加标准化,硬件厂商、开发者以及模型应用企业在文心+飞桨生态中,紧密链接、相互促进,形成共聚、共研、共创的健康生态。
百度大模型发展历史

◼ 拓展产业链生态,赋能大模型
百度专注于打造强大的生态体系,并积极拓展生态合作伙伴,以共同推动行业的发展。通过与深圳燃气、吉利、泰康保险、TCL、上海辞书出版社等各领域的企业紧密合作,百度文心发布了覆盖电力、燃气、金融、航天、传媒、城市、影视、制造、社科等多个领域的行业大模型。这些大模型的推出,正在加速各行业的智能化转型升级。
百度文心大模型已经吸引并服务了大量的开发者和企事业单位。目前,这个生态已经聚集了535万开发者,为20万家企事业单位提供服务。此外,百度还与12家硬件伙伴联合发布了飞桨生态发行版,旨在推动深度学习平台与更多硬件的适配,从而进一步提升AI技术的应用范围和效果。
除了与企业的合作,百度还与国内科研院所、实验室以及高校强强联手,共同攻克AI技术难关。这种产学研的合作模式,不仅有助于推动AI技术的创新和发展,还为培养AI人才提供了良好的平台。目前,百度已经赋能了389所高校,服务了747名教师,并通过学分课培养了10万余名AI学子。
总的来说,百度文心大模型通过聚焦生态打造、拓展生态伙伴以及产学研合作等方式,正在积极推动AI技术的创新、应用和人才培养,为各行业的智能化转型升级提供了有力的支持。
阿里:M6-OFA +“通义”大模型系列
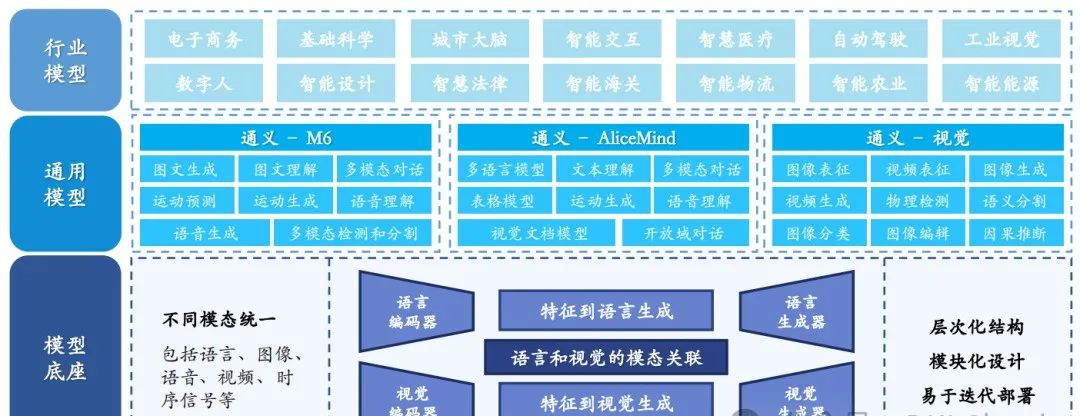
◼ 统一底座为基础,构建层次化的模型体系
阿里巴巴的通义大模型以统一底座为基础,巧妙地构建了层次化的模型体系。这个体系包括通用模型层和专业模型层,展现出阿里巴巴在大模型领域的深入研究和广泛应用。
通用模型层是这一体系的基础,它覆盖了自然语言处理、多模态和计算机视觉等多个领域,显示出阿里巴巴在自然语言和多模态处理方面的强大能力。而专业模型层则深入到了电商、医疗、法律、金融、娱乐等各个行业,通过针对特定行业进行建模和优化,提供了更加精准和高效的解决方案。
阿里巴巴自2020年起便不断在多模态及语言大模型领域进行突破,先后发布了多个版本的大模型。这些模型在超大模型规模、低碳训练技术、平台化服务以及具体落地应用等方面都取得了显著的成果。目前,通义大模型系列已经在超过200个场景中提供服务,并且实现了2%~10%的应用效果提升,这充分证明了阿里巴巴在大模型应用方面的实力。
为了进一步加快大模型的规模化应用,阿里巴巴达摩院还研发了超大模型落地关键技术——S4框架。这一框架在模型压缩方面取得了显著成效,即使在压缩率达到99%的情况下,多任务精度仍然可以接近无损。这一技术的研发和应用,无疑将极大地推动大模型在实际场景中的广泛应用和落地。
通义千问 发展历程
_
_
◼ 关键技术开源,丰富合作生态
通义大模型系列中语言大模型 AliceMind PLUG 、 多 模 态 理 解 与 生 成 统 一 模 型AliceMind-mPLUG、多模态统一底座模型M6-OFA、超大模型落地关键技术 S4 框架等核心模型及能力已面向全球开发者开源。
阿里通义大模型架构
华为:ModelArts + 盘古大模型
◼ 全栈式 AI 解决方案助力 AI for Industry & AI for Science
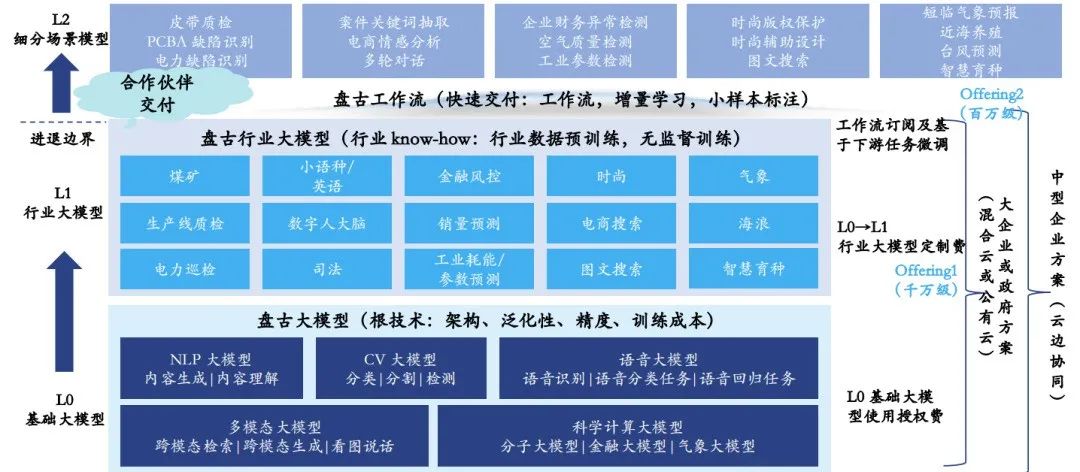
华为云在2020年内部启动了AI大模型项目,经过一年的精心研发,于2021年4月正式向外界推出了盘古预训练大模型。该模型的设计重点集中在数据丰富性、网络结构的优化以及强大的泛化能力。华为云为大模型的发展规划了清晰的路径:“L0 基础大模型-L1 行业大模型-L2 细分场景大模型”。
在L0阶段,盘古大模型涵盖了NLP、CV、语音、多模态以及科学计算等多个领域。特别是其CV大模型,拥有超过30亿参数,通过输入10亿级的图像数据进行预训练,使其既具备图像判别能力,又拥有图像生成能力。同时,NLP大模型在中文语言的理解和模型生成方面也展现了行业领先的水平。
进入L1阶段,华为云基于已建立的行业基础,进一步推出了盘古气象大模型、盘古矿山大模型、盘古OCR大模型等专门针对特定行业的大模型。这些模型在L2阶段的细分场景中,如煤矿环境下的瓦斯浓度预警、气象领域的天气预报等,都实现了有效的应用落地。
华为云致力于提供全栈式AI解决方案,将大模型与昇腾(Ascend)/鲲鹏芯片、昇思(MindSpore)编程语言和ModelArts开发平台紧密结合。通过这种全方位的整合,华为云以强大的算力底座、高效的服务器、全场景深度学习框架及开发平台,共同推动大模型技术的快速发展。
◼ 拓展产业链生态,赋能大模型
华为云积极拓展产业链上下游生态,通过鲲鹏凌云等合作伙伴计划,在算力、软硬件等方面建立生态伙伴网络,为 AI 大模型持续赋能,同时华为云与下游厂商联合发布行业解决方案,推动 AI 大模型商业化落地。
华为云盘古预训练大模型架构
腾讯:HCC 高性能计算集群+混元大模型
◼ 新一代 HCC 高性能计算集群为大模型提供底层支持
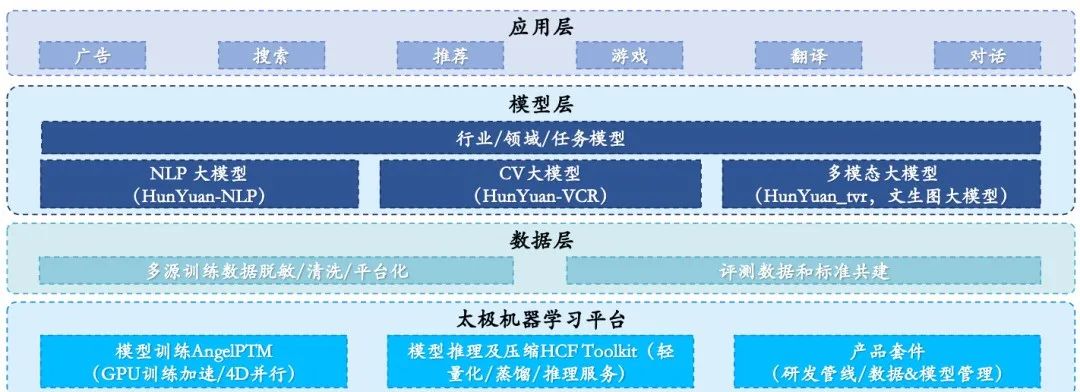
在2022年4月,腾讯首次公开介绍了其混元AI大模型,这一模型集中了腾讯在预训练技术方面的研发实力,通过一个统一的平台实现了技术的复用和业务的成本降低,从而更好地支持各种场景和应用。值得一提的是,混元AI大模型全面覆盖了NLP大模型、CV大模型、多模态大模型、文生图大模型以及众多针对特定行业和领域设计的任务模型。这一全面的覆盖范围使得混元AI大模型在MSR-VTT、MSVD等五大权威数据集榜单上都取得了领先的地位,实现了跨模态领域的大满贯。
目前,HunYuan NLP 1T大模型已经在腾讯的多个核心业务场景中得到了应用,并显著提升了业务效果。最近,腾讯还正式推出了全新的AI智能创作助手“腾讯智影”,其中包含了智影数字人、文本配音、文章转视频等创新的AI创作工具。
进入2023年4月,腾讯云又发布了新一代HCC高性能计算集群,这一集群将为混元大模型提供坚实的底层支持。新一代集群基于腾讯自研的星脉高性能计算网络和存储架构构建,同时集成了腾讯云自研的TACO训练加速引擎,从而大幅缩短了训练时间,节约了训练调优和算力成本。此外,腾讯太极机器学习平台自研的训练框架AngelPTM也已经通过腾讯云TACO提供服务,这将有助于企业更快地实现大模型的落地应用。
◼ 用户生态繁荣,促进模型迭代
腾讯在社交、阅读、游戏等领域拥有庞大用户群体与强大生态,具有丰富的语料资源、数据积累和场景优势。腾讯高级执行副 总 裁 汤 道 生 表 示,腾 讯 正 在 研 发 类ChatGPT 聊天机器人,将集成到 QQ、微信上。目前在智能写作、AI 绘图、游戏场景生成等方面都有新产品发布或迭代升级,有望助力其大模型在自有生态中快速迭代成长。
腾讯 HunYuan 大模型全景图
名词解释
_
_















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









