







项目要使用大数据环境,hadoop,所以研究了一下mapreduce,这里记录一下
window想要操作hadoop,需要配置环境,
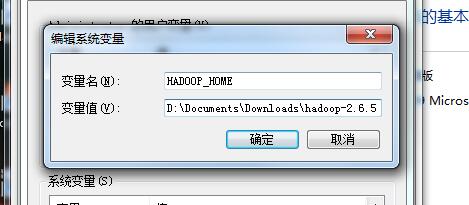
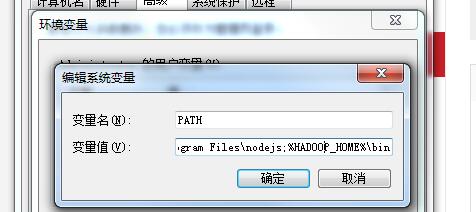
1,下载hadoop.2.6.5版本(主要是我操作的是2.6.5版本),解压后配置环境变量.这里的操作和配置java变量差不多.
需要配置HADOOP_HOME,和PATH这两个变量.
贴出我的变量配置
2,要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,可下载 Github 上的 hadoop2x-eclipse-plugin(备用下载地址:http://pan.baidu.com/s/1i4ikIoP)。
下载后,将 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar (还提供了 2.2.0 和 2.4.1 版本)复制到 Eclipse 安装目录的 plugins 文件夹中,运行 eclipse -clean 重启 Eclipse 即可(添加插件后只需要运行一次该命令,以后按照正常方式启动就行了)。这里可以参考这篇文章 点击打开链接
4.下载https://codeload.github.com/srccodes/hadoop-common-2.2.0-bin/zip/master下载hadoop-common-2.2.0-bin-master.zip,然后解压后,把hadoop-common-2.2.0-bin-master下的bin全部复制放到我们下载的Hadoop的bin Hadoop/bin目录下.
5.然后配置 Eclipse-》window-》Preferences 下的Hadoop Map/Peduce 把下载放在我们的磁盘的Hadoop目录引进来.
6,将 hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,然后重启电脑.
然后就可以运行自己的mapreduce程序了.这里也把我的mapreduce贴出来.
package testHbase2.controller;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;
public class HbaseMapReduce {
/**
* Mapper
*/
public static class MyMapper extends TableMapper<Text, NullWritable> {
public void map(ImmutableBytesWritable rows, Result result, Context context)
throws IOException, InterruptedException {
// 把取到的值直接打印
for (Cell kv : result.listCells()) { // 遍历每一行的各列
// 假如我们当时插入HBase的时候没有把int、float等类型的数据转换成String,这里就会乱码了
String row = new String(kv.getRowArray(), kv.getRowOffset(), kv.getRowLength(), "UTF-8");
String family =
new String(kv.getFamilyArray(), kv.getFamilyOffset(), kv.getFamilyLength(), "UTF-8");
String qualifier =
new String(kv.getQualifierArray(), kv.getQualifierOffset(), kv.getQualifierLength(),
"UTF-8");
String value =
new String(kv.getValueArray(), kv.getValueOffset(), kv.getValueLength(), "UTF-8");
System.out.println("row:" + row);
System.out.println("family:" + family);
System.out.println("qualifier:" + qualifier);
System.out.println("value:" + value);
System.out.println("timestamp:" + kv.getTimestamp());
System.out.println("-------------------------------------------");
}
}
}
/**
* Main
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
// 设置zookeeper
configuration.set("hbase.zookeeper.quorum", "hadoop1,hadoop2,hadoop3,hadoop4,hadoop5");//这里配置自己的hadoop服务端地址(配置在host文件中)
configuration.set("hbase.zookeeper.property.clientPort", "2181");//配置端口
// configuration.set(TableInputFormat.INPUT_TABLE, "EPBASEINFOPOJO");//这个属性我还没有弄明白,暂时不写注释
// 将该值改大,防止hbase超时退出
configuration.set("dfs.socket.timeout", "18000");
Scan scan = new Scan();
scan.setCaching(1024);
scan.setCacheBlocks(false);
Job job = new Job(configuration, "ScanHbaseJob");
TableMapReduceUtil.initTableMapperJob(Bytes.toBytes("EPBASEINFOPOJO"), scan, MyMapper.class,
Text.class, NullWritable.class, job);
job.setOutputFormatClass(NullOutputFormat.class);
job.setNumReduceTasks(1);
job.waitForCompletion(true);
}
}这里只是使用的map来读取数据,reduce程序就更具自己想要如何操作就如何写吧....(其实我还没有写...汉...)
这里还贴出我的pom.xml文件,我发现很多博客写贴出了代码,但找不到使用的是那些jar包...一直很困惑.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>testHbase2</groupId>
<artifactId>testHbase2</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<java.encoding>UTF-8</java.encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Camden.SR4</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.35</version>
</dependency>
<!-- swagger -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- boot-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<!-- hadoop 相关 -->
<!-- <dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.96.1.1-hadoop2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency> -->
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>2.0.2.RELEASE</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.16</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-sdk</artifactId>
<version>1.7.0</version>
</dependency>
<!-- websocket相关 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>














 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









