







海量数据处理一般常见方法:
海量数据量很大时-->hash
海量数据的最大或者最小K个-->堆
海量数据的最值-->hash+内排序+归并
海量数据统计出现次数-->hash_map或者Trie树
文件之间共同值-->set
海量数据直接重复性判断-->bitmap/bloom filter
具体总结如下:
1. Bloom Filter
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
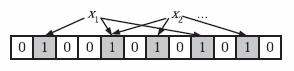
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。
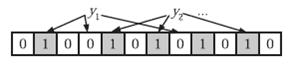
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
2. Hash
hash技术是基于key-lococation关系而非key-compared关系的查询结构。常用的hash函数:
线性hash;平方取中;数字分析;除留余数;随机法,总体原则是尽量分配均匀
当然再好的hash函数也会存在hash冲突即不同的Key映射到相同位置,此时解决hash冲突:
1 线性探测或者平方探测
2 拉链法
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
3. bit-map
基本原理及要点:使用bit数组来表示某些元素是否存在
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
4. 堆
利用堆结构进行TOP K获取。
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当前元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较小的情况,这样可以扫描一遍即可得到所有的前n元素,效率很高。
代码:
//堆
void heap_fixup(int a[],int n,int i){
int tmp=a[i];
int j=(i-1)/2;//parent node
while(j>=0&&i>=0){
if(a[j]<=tmp)break;
a[i]=a[j];//较大向下移动
i=j;
j=(i-1)/2;
}
a[i]=tmp;
}
void heap_insort(int a[],int n,int k){
a[n]=k;
heap_insort(a,n+1,n);
}
void heap_fixdown(int a[],int n,int i){
int tmp=a[i];
int j=2*i+1;
while(j<n&&i<n){
if(j+1<n&&a[j]>a[j+1])j++;
if(tmp<=a[j])break;
a[i]=a[j];//小的上
i=j;
j=2*i+1;
}
a[i]=tmp;
}
void heap_delete(int a[],int n){
int tmp=a[0];
a[0]=a[n-1];
a[n-1]=tmp;
heap_fixdown(a,n-1,0);//n-1,ignore the last one
}
void heap_sort(int a[],int n){
int i;
for(i=n-1/2;i>=0;i--)
heap_fixdown(a,n,i);
for(i=n-1;i>0;i--){
int tmp=a[0];
a[0]=a[i];
a[i]=tmp;
heap_fixdown(a,i,0);
}
}Trie树又被称为字典树、前缀树,是一种用于快速检索的多叉树。Tried树可以利用字符串的公共前缀来节省存储空间。但如果系统存在大量没有公共前缀的字符串,相应的Trie树将非常消耗内存。构造如下:

相关细节见我另一blog:Trie















 859
859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









