






同样的sql,测试环境数据多一点,运行速度反而比线上快。join 字段都是有索引的。(直接答案是:排序导致)
准备了两张表测试 test_a 23M, test_c 4M. mysql 版本 5.7.36
三张表都有一个字段 a, 且都加了索引

平时业务开发都会有排序,然后我就测试了排序对性能的影响(线上的那个老sql 是从20多秒,优化到了1秒内,我自己造的数据比较少,演示下意思就行了)
先拿test_a 和 test_c 测试,分别按 tc.a 和 ta.a 进行排序, 分别运行时间是 86 毫秒和 277 毫秒
看下面的执行计划应该就能明白了。
select ta.id from test_a ta
join test_c tc on ta.a = tc.a
order by tc.a

select ta.id from test_a ta
join test_c tc on ta.a = tc.a
order by ta.a

原因:mysql 优化器帮我们做了“优化”,让小表驱动大表。也就是 test_c 成了驱动表,当排序字段在驱动表上时,才能正常使用索引排序。
所以我遇到的问题就是:虽然测试环境总数据多一点,按 test_a 排序的话。测试环境 test_a 数据相对少,恰好成了驱动表。而正式环境,test_a 比 test_c 数据多很多,然后驱动表变成了 test_c。导致 Using filesort。表现得结果就是总数据多一点得库,查询速度还快一点
还有一个优化,如果id是递增的,很多时候排序都是按时间排序,这个时候直接改成按id排序,这样可以少建一个索引。
因为业务需求排序就得按a表排,我当时直接改成了 straight_join 手动确定主次表关系。如下图,排序就会变得正常。真实环境数据比较大,sql又复杂的情况下,Using filesort 会导致 sql 卡得让人怀疑人生。。。
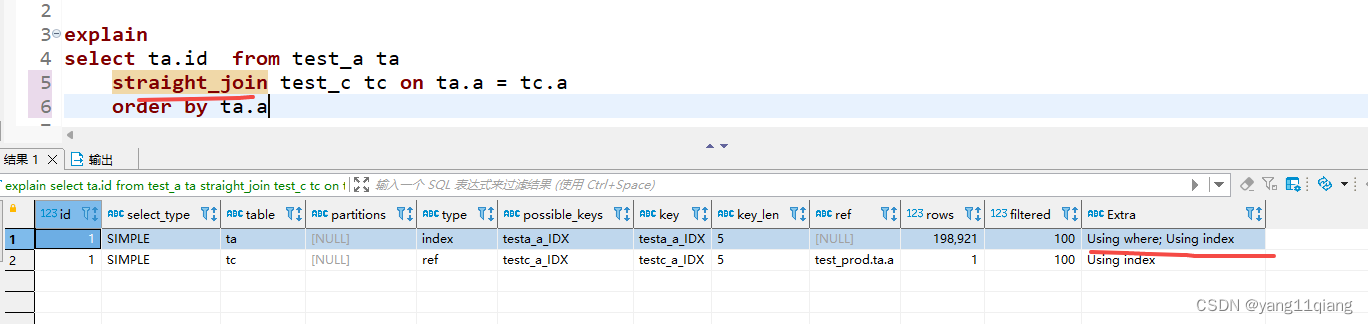
排序字段需要是驱动表才能使用索引。很好理解。相当于嵌套循环,只有外循环(驱动表)有序才能保证整体顺序嘛。















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









