







目录
0. 相关文章链接
1. 星型模型
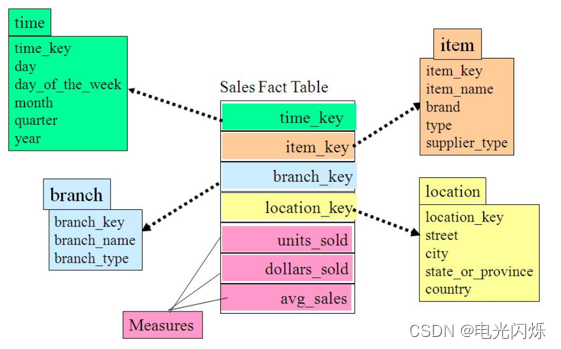
星型模型中只有一张事实表,以及0张或多张维表,事实表与维表通过主键外键相关联,维表之间不存在关联关系,当所有维表都关联到事实表时,整个图形非常像一种星星的结构,所以称之为“星型模型”。
星型模型是最简单最常用的模型。星型模型本质是一张大表,相比于其他数据模型更合适于大数据处理。其他模型可以通过一定的转换,变为星型模型。
星型模型的缺点是存在一定程度的数据冗余。因为其维表只有一个层级,有些信息被存储了多次。如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
星型模型强调的是对维度进行预处理,将多个维度集合到一个事实表,形成一个宽表。这也是我们在使用hive时,经常会看到一些大宽表的原因,大宽表一般都是事实表,包含了维度关联的主键和一些度量信息,而维度表则是事实表里面维度的具体信息,使用时候一般通过join来组合数据,相对来说对OLAP的分析比较方便。
2. 雪花模型
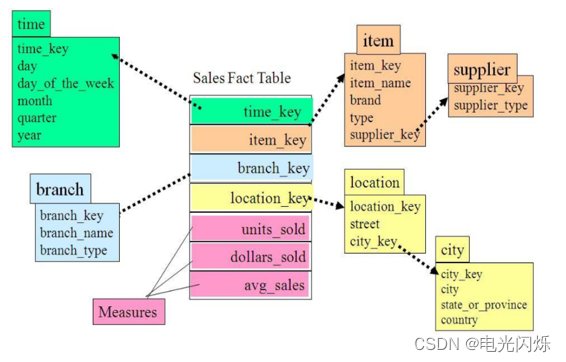
当一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展,它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如将地域维表分解为国家,省份,城市等维表。
它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,去除了数据冗余,但是在分析数据的时候,操作比较复杂,需要join的表比较多所以其性能并不一定比星型模型高,并且不利于开发。
3. 星座模型

星座模型只跟数据和需求有关系,跟设计没关系,跟星型模型和雪花模型不是同一类。星座模型是基于多个事实表,而星型模型和雪花模型是基于一张事实表的。
基本上是很多数据仓库的常态,因为很多数据仓库都是多个事实表的。所以星座不星座只反映是否有多个事实表,他们之间是否共享一些维度表。
4. 对比和选择
Ralph Kimball,数据仓库大师,讲述了三个例子。对于三个例子,使用雪花模型不仅仅是可接受的,而且可能是一个成功设计的关键。
- 一个用户维度表且数据量较大。其中,80%的事实度量表是匿名访问者,仅包含少数详细信息。20%的是可靠的注册用户,且这些注册用户有较为详细的信息,与多个维度表中的数据相连。
- 例如一个金融产品维度表,且这些金融产品有银行类的,保险类等等区别。因此不同种类的产品有自己一系列的特殊属性,且这些属性并非是所有产品共享的。
- 多个企业共用的日历维度表。但每个企业的财政周期不同,节假日不同等等。在数据仓库的环境中用雪花模型,降低储存的空间,到了具体某个主题的数据集市再用星型模型。
根据上述总结我们可以看出:
- 雪花模型使得维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司是在线的?”,星形模型用来做指标分析更适合,比如“给定的一个客户他们的收入是多少?”
- 在数据仓库建设中大多时候比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好;而雪花模型在关系型数据库中如MySQL,Oracle中非常常见,尤其像电商的数据库表。
总结:星型还是雪花,取决于性能优先,还是灵活更优先。并且在目前实际的企业开发中,不会绝对选择一种,根据情况灵活组合,甚至并存(一层维度和多层维度都保存)。但是整体来看,更倾向于维度更少的星型模型。尤其是Hadoop体系,减少Join就是减少Shuffle,性能差距很大。(关系型数据可以依靠强大的主键索引)
注:其他 离线数仓 相关文章链接由此进 -> 离线数仓文章汇总


















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











