







 Presto是一款由Facebook开源的分布式SQL查询引擎,适用于交互式分析查询,支持从GB到PB级数据量。其架构源自关系型数据库,具备独立运行能力,无需依赖外部系统。Presto的特点包括清晰架构、简单数据结构、丰富插件接口、多数据源支持、扩展性、混合计算、高性能及流水线处理。本文深入讲解Presto的架构、数据模型、内存管理及其HA解决方案。
Presto是一款由Facebook开源的分布式SQL查询引擎,适用于交互式分析查询,支持从GB到PB级数据量。其架构源自关系型数据库,具备独立运行能力,无需依赖外部系统。Presto的特点包括清晰架构、简单数据结构、丰富插件接口、多数据源支持、扩展性、混合计算、高性能及流水线处理。本文深入讲解Presto的架构、数据模型、内存管理及其HA解决方案。
Presto的简介
Presto是一个facebook开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。presto的架构由关系型数据库的架构演化而来。presto之所以能在各个内存计算型数据库中脱颖而出,在于以下几点:
- 清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。例如调度,presto自身提供了对集群的监控,可以根据监控信息完成调度。
- 简单的数据结构,列式存储,逻辑行,大部分数据都可以轻易的转化成presto所需要的这种数据结构。
- 丰富的插件接口,完美对接外部存储系统,或者添加自定义的函数。
Presto的优点和特点
多数据源、支持SQL、扩展性(可以自己扩展新的connector)、混合计算(同一种数据源的不同库 or表;将多个数据源的数据进行合并)、高性能、流水线(pipeline)

Presto的架构
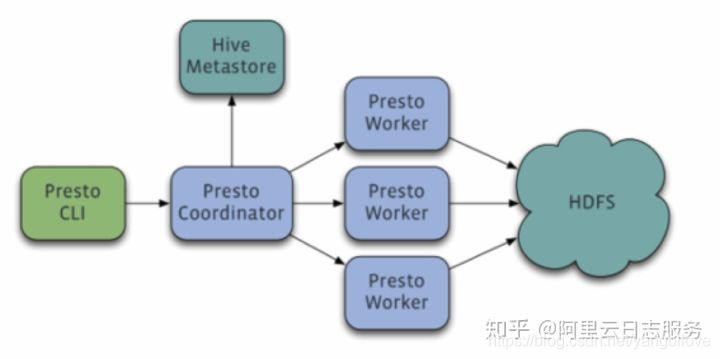
Presto采用典型的master-slave模型:
- coordinator(master)负责meta管理,worker管理,query的解析和调度。
- worker则负责计算和读写。
- discovery server, 通常内嵌于coordinator节点中,也可以单独部署,用于节点心跳。
Presto的数据模型
presto采取三层表结构:
- 1、catalog 对应某一类数据源,例如hive的数据,或mysql的数据。
- 2、schema 对应mysql中的数据库。
- 3、table 对应mysql中的表。
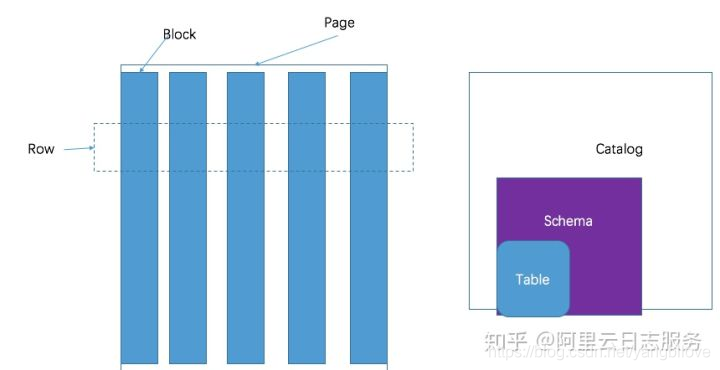
presto的存储单元包括:
- 1、Page: 多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
- 2、Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接presto。
不同类型的block:
1、array类型block,应用于固定宽度的类型,例如int,long,double。block由两部分组成。
- boolean valueIsNull[]表示每一行是否有值。
- T values[] 每一行的具体值。
2、可变宽度的block,应用于string类数据,由三部分信息组成。
- Slice : 所有行的数据拼接起来的字符串。
- int offsets[] :每一行数据的起始偏移位置。每一行的长度等于下一行的起始便宜减去当前行的起始偏移。
- boolean valueIsNull[] 表示某一行是否有值。如果有某一行无值,那么这一行的便宜量等于上一行的偏移量。
3、固定宽度的string类型的block,所有行的数据拼接成一长串Slice,每一行的长度固定。
4、字典block:对于某些列,distinct值较少,适合使用字典保存。主要有两部分组成:
- 字典,可以是任意一种类型的block(甚至可以嵌套一个字典block),block中的每一行按照顺序排序编号。
- int ids[] 表示每一行数据对应的value在字典中的编号。在查找时,首先找到某一行的id,然后到字典中获取真实的值。
Presto的内存管理
Presto是一款内存计算型的引擎,所以对于内存管理必须做到精细,才能保证query有序、顺利的执行,部分发生饿死、死锁等情况。
内存池
Presto采用逻辑的内存池,来管理不同类型的内存需求。
Presto把整个内存划分成三个内存池,分别是System Pool ,Reserved Pool, General Pool。
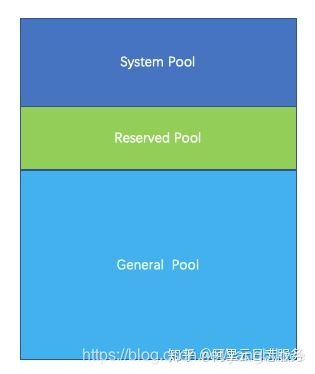
- 1、System Pool 是用来保留给系统使用的,默认为40%的内存空间留给系统使用。
- 2、Reserved Pool和General Pool 是用来分配query运行时内存的。
- 3、其中大部分的query使用general Pool。 而最大的一个query,使用Reserved Pool, 所以Reserved Pool的空间等同于一个query在一个机器上运行使用的最大空间大小,默认是10%的空间。
- 4、General则享有除了System Pool和General Pool之外的其他内存空间。
为什么要使用内存池
System Pool用于系统使用的内存,例如机器之间传递数据,在内存中会维护buffer,这部分内存挂载system名下。
那么,为什么需要保留区内存呢?并且保留区内存正好等于query在机器上使用的最大内存?
如果没有Reserved Pool, 那么当query非常多,并且把内存空间几乎快要占完的时候,某一个内存消耗比较大的query开始运行。但是这时候已经没有内存空间可供这个query运行了,这个query一直处于挂起状态,等待可用的内存。 但是其他的小内存query跑完后,又有新的小内存query加进来。由于小内存query占用内存小,很容易找到可用内存。 这种情况下,大内存query就一直挂起直到饿死。
所以为了防止出现这种饿死的情况,必须预留出来一块空间,共大内存query运行。 预留的空间大小等于query允许使用的最大内存。Presto每秒钟,挑出来一个内存占用最大的query,允许它使用reserved pool,避免一直没有可用内存供该query运行。
Presto的内存管理
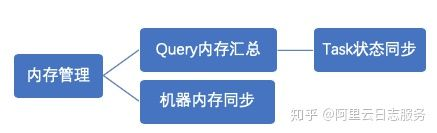
Presto内存管理,分两部分:
1、query内存管理:
- query划分成很多task, 每个task会有一个线程循环获取task的状态,包括task所用内存。汇总成query所用内存。
- 如果query的汇总内存超过一定大小,则强制终止该query。
2、机器内存管理
- coordinator有一个线程,定时的轮训每台机器,查看当前的机器内存状态。
当query内存和机器内存汇总之后,coordinator会挑选出一个内存使用最大的query,分配给Reserved Pool。
内存管理是由coordinator来管理的, coordinator每秒钟做一次判断,指定某个query在所有的机器上都能使用reserved 内存。那么问题来了,如果某台机器上,,没有运行该query,那岂不是该机器预留的内存浪费了?为什么不在单台机器上挑出来一个最大的task执行。原因还是死锁,假如query,在其他机器上享有reserved内存,很快执行结束。但是在某一台机器上不是最大的task,一直得不到运行,导致该query无法结束。
Presto的master的HA
可以通过配置Discovery Service或者keepalive来实现:
参考链接:
- 配置Discovery Service
https://blog.csdn.net/anghiking20140716/article/details/101312055 - keepalive
https://blog.csdn.net/liaynling/article/details/86589488

















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









