






1.k-means算法的主要特点:
a、对二维的数据进行分割;b、其分割的区域多少是人为设定的
c、其聚类的正确性很依赖于分类中心的初始化,以前一般都采取随机初始化,但是会存在一个问题:如果数据在某个部分较密集,那么产生的随机数会以更高’的概率靠近这些数据。这就导致如果没有没迭代足够的次数是很难达到较好的聚类效果的。所以一般使用kmeans++来初始化中心。
靠的太近的结果:
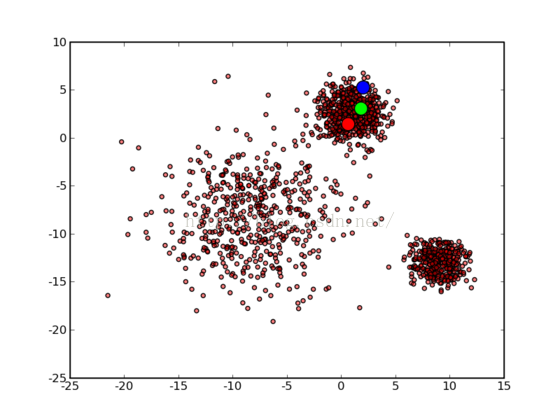
分的不好的结果:
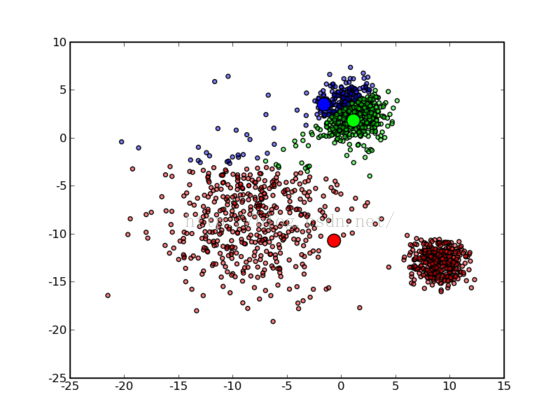
介绍:
为了解决上述问题,David Arthur 提出了 Kmeans++ 算法,该方法可以有效的产生好的聚类中心,过程如下:
1、从输入的数据点集合中随机选择一个点作为第一个聚类中心
2、对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3、选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4、重复2和3直到k个聚类中心被选出来
5、利用这k个初始的聚类中心来运行标准的k-means算法
其中,第 3 步的实现为,先取一个能落在Sum(D(x))中的随机值 Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
假设第一个聚类中心为 1,那么,所有输入数据与聚类中心的距离 D为:
D(x)=[0.2,0.15,0.1,0.05,0,0.05,0.1,0.2,2.,2.1,2.2]
对 D 求前缀和,得到 D1,D1为:
D1=[0.2,0.35,0.45,0.5,0.5,0.55,0.65,0.85,2.85,4.95,7.15]
如下图所示:

此时产生一个随机数 random∈(0, 1),并乘以 D1(end) = 7.15,那么,该数大于等于 0.85 的概率会非常大,假设为 4,那么第10 个数,4.95 是第一个大于 4 的数,就把输入数据中的第 10 个,也就是 3.1 作为新的聚类中心。
上述过程的意义为:让新的聚类中心以更大的概率远离已有的聚类中心,以避免聚类中心以高概率分布在数据密集的部份。
litekmeans
两处优化:
1.在分配数据点时,算法所关心的并非真正的距离值,而是对距离的排序。因而,在计算过程中可以去除那些并不影响排序的计算项。
观察
||xi−cj||2=||xi||2+||cj||2−2<xi,cj>
这条距离计算式可以发现,在kmeans迭代过程中,
||xi||2
不影响排序,因而可以不进行计算。
问题转化为求:
min(||cj||2−2<xi,cj>)
为了方便矩阵运算,将问题进一步改写为:
max(2<xi,cj>−||cj||2)
(个人理解:其实都是nkd的复杂法,只是为了方便matlab的内部快速运行能调用bsxfun,||Cj||而改写的)
其中
||cj||2
的矩阵大小远小于
<xi,cj>
的矩阵大小,于是改变常数2的位置将进一步优化计算。最后该问题的求解进一步转换为:
max(<xi,cj>−||cj||2/2)
2.将中心点的更新矢量化。这里主要引入了示性矩阵E,如果样本i属于集合k,则E(i,k)=1/n(k),其它为0。之后中心点的计算就由矩阵运算表示(公式难打,请看着代码脑补)。
function [label, centroids] = litekmeans(X, k)
n = size(X, 2);
last = 0;
label = X(:, randsample(n,k)); %随机初始化
while any(label ~= last)
E = sparse(1:n, label, 1, n, k, n); %构建示性矩阵
m = X*(E*spdiags(1./sum(E,1)',0,k,k)); %计算每个集合的均值
last = label; %保存上一次计算结果
[~,label] = max(bsxfun(@minus,m'*X,dot(m,m,1)'/2,[],1); %分配样本所属集合
end
end* 仔细研究计算过程,去掉不必要的计算;
* 运用矩阵运算性质,将计算矢量化(本文中运用了示性矩阵和对角矩阵);
* 在Matlab中稀疏矩阵乘法运算速度快于稠密矩阵,将必要矩阵存储为稀疏矩阵形式。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









