







 假设检验是统计学中用于判断样本与总体差异的重要方法,基于小概率事件原理,通过设定原假设和备择假设,通过统计量计算和拒绝域判断来决策。常见的假设检验包括Z检验、t检验、卡方检验和F检验。在执行假设检验时,需确定假设、选择检验统计量、设定显著性水平、验证前提条件并计算P值。统计功效衡量拒绝错误假设的能力,对实验设计和样本量选择有重要意义。在实际应用中,如生产线技术改造效果评估和产品口味改善等,都需要将问题转化为统计问题并进行假设检验,最终将统计结果转化为实际决策。
假设检验是统计学中用于判断样本与总体差异的重要方法,基于小概率事件原理,通过设定原假设和备择假设,通过统计量计算和拒绝域判断来决策。常见的假设检验包括Z检验、t检验、卡方检验和F检验。在执行假设检验时,需确定假设、选择检验统计量、设定显著性水平、验证前提条件并计算P值。统计功效衡量拒绝错误假设的能力,对实验设计和样本量选择有重要意义。在实际应用中,如生产线技术改造效果评估和产品口味改善等,都需要将问题转化为统计问题并进行假设检验,最终将统计结果转化为实际决策。
1. 定义:假设检验(hypothesis testing),又称统计假设检验,是用来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。显著性检验是假设检验中最常用的一种方法,也是一种最基本的统计推断形式,其基本原理是先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。常用的假设检验方法有Z检验、t检验、卡方检验、F检验等 。
2. 基本思想:假设检验的基本思想是“小概率事件”原理,其统计推断方法是带有某种概率性质的反证法。小概率思想是指小概率事件在一次试验中基本上不会发生。反证法思想是先提出检验假设,再用适当的统计方法,利用小概率原理,确定假设是否成立。即为了检验一个假设H0是否正确,首先假定该假设H0正确,然后根据样本对假设H0做出接受或拒绝的决策。如果样本观察值导致了“小概率事件”发生,就应拒绝假设H0,否则应接受假设H0 。
假设检验中所谓“小概率事件”,并非逻辑中的绝对矛盾,而是基于人们在实践中广泛采用的原则,即小概率事件在一次试验中是几乎不发生的,但概率小到什么程度才能算作“小概率事件”,显然,“小概率事件”的概率越小,否定原假设H0就越有说服力,常记这个概率值为α(0<α<1),称为检验的显著性水平。对于不同的问题,检验的显著性水平α不一定相同,一般认为,事件发生的概率小于0.1、0.05或0.01等,即“小概率事件” 。
3. 假设检验的执行步骤:

确定假设---》选择检验统计量----》确定拒绝域----》求出P值(小于或者等于拒绝域向上的一个样本数值的概率)-----》判断样本结果是否位于拒绝域中-----》做出决策。
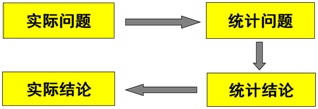
将实际问题提炼为统计问题
这是很重要的一步,也是关键的一步。举个例子来说明,某工厂对生产线进行了技术改造,老板想知道改造后生产线有什么提升。首先就要搞清楚对比什么,是加工精度提高了?是合格率提高了?是加工工时缩短了?还是人力节省了?等等。如果老板关注产能是不是提升了,那么实际问题就可以提炼成“改造后的每小时产出数是否高于改进前”这样一个统计问题。当然老板可能不止关注一个问题,那你就需要提炼出多个统计问题,每个问题所采用的推断方法可能不同。
再举个例子,如果你是面包房的老板,最近改进了配方,你想知道在客户那里面包的口味是否变得更好了。这时你就要首先考虑如何对口味进行评价,是由客户打分呢?还是仅仅让客户评价一下,然后计数看看客户的喜好呢?我们搞简单一点,两种面包都让客户品尝,然后有多少人喜欢老面包,有多少人喜欢新面包。那这个实际问题就可以提炼成“配方更改后面包口味是否高于更改前”这样一个统计问题。
建立假设
假设检验需要建立一对相互对立的假设,原假设和备择假设(有很多地方写成),通常我们将无区别的、不需证明的放在原假设,将有差别的、需要证明的放在备择假设 (关于如何做假设,下一篇细谈)。
在例1中,生产线改造前的均值和方差都已经盖棺定论了,这里我们就算是已知,改造后待运行稳定后抽样,这样我们可以建立的假设如下:
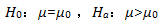
在总体均值和方差已知的条件下,可知这是一个单样本z检验
在例2中,我们感兴趣的问题是喜欢新面包的客户是不是比喜欢老面包的多,也就是说喜欢新面包客户的比率是不是大于0.5,于是可以建立这样的假设:
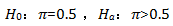
这里π是总体的比率。这是一个单比率检验。
确定显著性水平α
显著性水平在这里也叫第一类风险,大多数情况下取0.05,当然也有取0.1或者0.01的。
验证前提条件
在很多的方法应用中,都会有一些前提条件,如单样本z检验要求收集的数据要服从正态分布;方差分析中要求每个样本都要服从正态分布,且要满足方差齐性即方差相等的要求。这是因为每一种检验方法都是在这些前提假设中推导出来的,如果这些前提条件不能满足,则这个方法应用的效果就要大打折扣,这就是在每次检验是要验证前提条件的原因。
确定检验统计量
这是关键的一步,确定了检验方法后,就可以列出它的检验统计量,如例1中,检验统计量就是前面介绍的
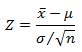
而例2的检验统计量则是
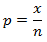
其中n是品尝面包的客户数,x是选择新面包的客户数。
确定拒绝域
在确定了显著性水平后,即可以根据检验统计量计算出拒绝域。所谓的拒绝域,就是根据原假设划定的一个区域,当所抽样本计算出的统计量落在这个区域时,就可以拒绝原假设,可想而知,它代表的是样本远离原假设的程度。拒绝域有很多种,后面会另行介绍。就本文的例1来说,拒绝域的范围是z>1.645,是不是觉得这个值很面熟啊?对!在介绍正态分布的时候重点介绍过。
根据样本计算检验统计量的值并进行判断
确定了拒绝域,下面就是根据样本计算检验统计量的值,如果这个值落在拒绝域中,则拒绝原假设,接受备择假设;如果没有落在拒绝域,就说明拒绝原假设的证据还不够充分,但尽量不要说接受原假设。
现在流行的方法是计算p值,即备择假设远离以及更远离原假设的概率,这主要是因为统计软件已经非常普及了。举例来说,如果原假设是μ=10,备择假设是μ>10,抽样计算出的样本均值是10.5,则p值就是μ≥10.5的概率;如果备择假设是μ<10,则p值就是μ≤10.5的概率。将这个p值与α进行比较,如果p<α则说明样本均值离原假设比较远,可以拒绝原假设;如果p>α,则说明没有足够的证据证明原假设不成立,所以无法拒绝原假设。
将统计判断结果转换成实际结果
最后一步,要把统计上得出的结论转换为实际的结论,并据此作出相应的决策。如在例1中,如果证明备择假设成立,那就说明老板的钱花对了,皆大欢喜;如果证明没有显著提高,那还要进一步研究,找出产能没有有效释放的原因。
在例2中,由于是离散的二项分布,要想得出较确切的拒绝原假设的结论有两种情况,一种是n比较小但p=x/n很大(注意这里的p与上一小节所说的p值完全不是一个概念),如果样本量很小的话,你会看到即使p大到0.8、0.9都不一定显著;另一种是p=x/n比0.5大不了多少,但n非常大。没办法,熟悉的人都知道,相同样本量的连续数据所包含的信息要远远多于离散数据。因此在对离散数据进行分析时,尽可能获取大样本通常是必需的。
实践中, 统计功效大量地应用于医学、生物学、 生态学和人文社会科学等方面的统计检验中。
例如, 在国外抽样调查设计方案中, 对统计功效的要求如同对显著性水平α一样, 是不可缺少的内容。这是有道理的。因为在统计推论中, 既要控制α错误, 又要控制β错误, 满足双重控制条件下的样本量才是更有效的样本量。统计功效的大小取决于多种因素, 包括: 检验的类型、 样本容量、α水平、单侧双侧, 以及抽样误差的状况。统计功效分析应是上面诸因素结合在一起的综合分析。
一些统计软件, 如SA S、 SPSS等虽都有计算统计功效的功能, 但由于它们不是功效分析的专用统计软件, 因而在使用中有不少局限,如在使用范围、 检验类型、 文件切换、 提供的使用说明等方面与专门的功效分析统计软件相比, 都有一定的差距。且一般统计软件在计算统计功效时也不够简便, 这使功效的应用受到了限制。
鉴于统计功效在推论统计中的重要地位, 国外科研学术机构和商业公司对统计功效的软件开发进行了大量投入, 已研制出不少专门的分析软件。 这当中有些是免费提供的, 可以从互联网上查到, 并下载使用。(比如Gpower)






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









