






哈姆雷特英文词频统计
def getText():
txt=open("hamlet.txt","r").read()
txt=txt.lower()#避免大小写对词频统计的干扰
for ch in '!"#$%&()+,-./:;<>=?@[\\]^_{}|':#去掉其中的特殊符号替换成空格
txt=txt.replace(ch," ")
return txt
hamletTxt=getText() #对文件进行读取 对文本进行归一化
words=hamletTxt.split() #用空格分隔返回为列表形式
counts={}
for word in words:
counts[word]=counts.get(word,0)+1#用某个英文单词作为键索引字典
#遍历统计完所有出现次数后 对词频出现次数进行排序
items=list(counts.items())#将字典类型转换为列表类型便于操作
items.sort(key=lambda x:x[1],reverse=True)#从大到小排序
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
运行结果
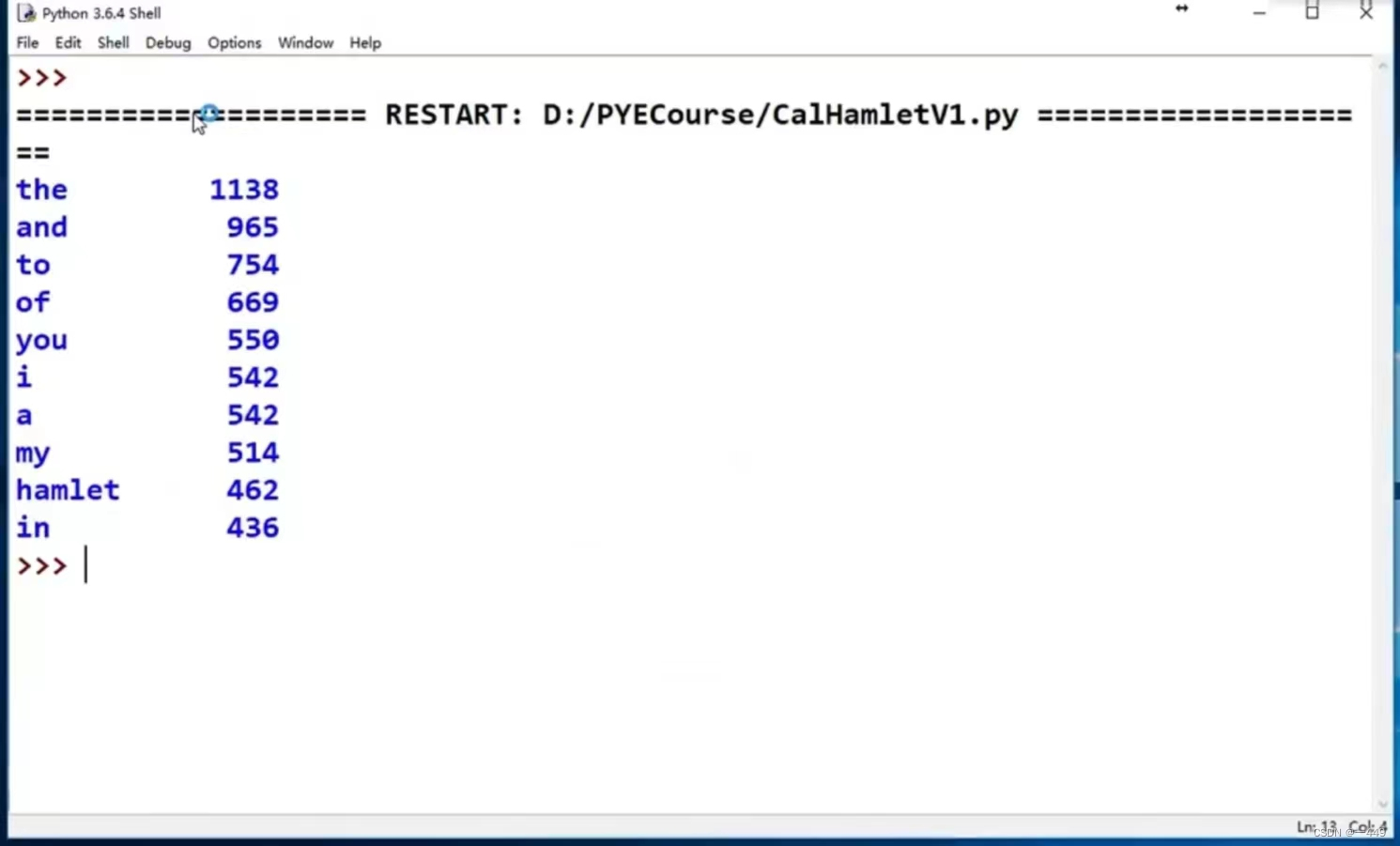
三国演义人物出场次数统计
用jieba库进行中文分词
import jieba
txt = open("threekingdoms.txt","r",encoding=utf-8).read()
words=jieba.lcut(txt)#分词处理形成列表
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
jieba分词统计出来有很多不是人名,可以将这些词加入列表排除。重复人名比如诸葛亮 孔明通过for循环统计进去算作一个人物。















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









