







YangNet_v1.0:从零构造一个基于C++的深度学习框架
前言
本文将介绍如何使用C++从零创造一个简单的深度学习框架,该框架仅供学习使用。通过学习该框架,可深入了解神经网络的作用机理和数学原理。目前该框架只提供一些基本功能,并不支持GPU加速,同时也不支持批量学习,未来笔者若时间充裕,将为该框架增添更多组件并实现GPU加速。
yangnet.h文件:
#pragma once
/*
typedef enum {
LOGISTIC, RELU, RELIE, LINEAR, RAMP, TANH, PLSE, LEAKY, ELU, LOGGY, STAIR, HARDTAN, LHTAN, SELU
} ACTIVATION;
*/
const int SECRET_NUM = -32767;
typedef enum {
CONVOLUTION, DECONVOLUTION, CONNECTED, MAXPOOL, SOFTMAX, DETECTION, DROPOUT, CROP, ROUTE, COST, NORMALIZATION, AVGPOOL,
LOCAL, SHORTCUT, ACTIVE, RNN, GRU, LSTM, CRNN, BATCHNORM, NETWORK, XNOR, REGION, YOLO, ISEG, REORG, UPSAMPLE, LOGXENT, L2NORM, BLANK,
RELU, SIGMOID, AFFINE, INPUT
} LAYER_TYPE;
typedef enum {
RAND, GAUSS
} WEIGHT_INI_METHOD;
typedef enum {
SGD, ADAM, MOMENTUM
}OPTIMIZER;
一、基本数据结构:三维矩阵类
头文件matrix.h
#pragma once
#include<stdlib.h>
#include<time.h>
#include<iostream>
#include"functions.h"
using std::cout;
class Matrix
{
public:
//类的成员
int row;
int col;
int chan;
double*** weight;
//重要的成员函数
Matrix(int r = 1, int c = 1, int ch = 1);
Matrix(const Matrix& Mtr);
Matrix& operator=(const Matrix& Mtr);
~Matrix();
void init();
//矩阵间的运算
void add(const Matrix& B, Matrix& OUT);
void mul(const Matrix& B, Matrix& OUT);
void dot_mul(const Matrix& B, Matrix& OUT);
void dot_mul(double x, Matrix& OUT);
void sub_m(Matrix&, int row_begin = 0, int col_begin = 0, int chan_begin = 0);//从0开始计算
//矩阵的访问
double sum();
double max();
void show();
double value(int r = 0, int c = 0, int ch = 0);
int size();
//矩阵赋值
void reweight(double x, int r = 0, int c = 0, int ch = 0);
void reweight(const Matrix&, int row_s = 0, int row_e = -1, int col_s = 0, int col_e = -1, int chan_s = 0, int chan_e = -1);
void zeros();
void ones();
void neg_ones();
void identity();
void randm();
void gaussrand(double mean = 0.0, double var = 1.0);
//矩阵修改
void reshape(int r = -1, int c = 1, int ch = 1);
void padding(int pad)&;
};
源文件matrix.cpp
#include "matrix.h"
Matrix::Matrix(int r, int c, int ch)
{
row = r;
col = c;
chan = ch;
init();
}
Matrix::Matrix(const Matrix& Mtr)
{
row = Mtr.row;
col = Mtr.col;
chan = Mtr.chan;
init();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
for (int k = 0; k < chan; k++)
{
weight[i][j][k] = Mtr.weight[i][j][k];
}
}
}
}
Matrix& Matrix::operator=(const Matrix& Mtr)
{
if (this == &Mtr)
return *this;
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
delete weight[i][j];
}
delete weight[i];
}
delete weight;
row = Mtr.row;
col = Mtr.col;
chan = Mtr.chan;
init();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
for (int k = 0; k < chan; k++)
{
weight[i][j][k] = Mtr.weight[i][j][k];
}
}
}
return *this;
}
void Matrix::init()
{
weight = new double** [row];
for (int i = 0; i < row; i++)
{
weight[i] = new double* [col];
for (int j = 0; j < col; j++)
weight[i][j] = new double[chan];
}
}
Matrix::~Matrix()
{
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
delete weight[i][j];
}
delete weight[i];
}
delete weight;
}
void Matrix::add(const Matrix& B, Matrix& OUT)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
OUT.weight[i][j][k] = weight[i][j][k] + B.weight[i][j][k];
}
}
void Matrix::mul(const Matrix& B, Matrix& OUT)
{
if (col != B.row)
{
std::cout << "The scale of the two matrixs does not match";
}
double s;
for (int k = 0; k < chan; k++)
for (int i = 0; i < row; i++)
for (int j = 0; j < B.col; j++)
{
s = 0;
for (int tmp = 0; tmp < col; tmp++)
{
s += weight[i][tmp][k] * B.weight[tmp][j][k];
}
OUT.weight[i][j][k] = s;
}
}
void Matrix::dot_mul(const Matrix& B, Matrix& OUT)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
OUT.weight[i][j][k] = weight[i][j][k] * B.weight[i][j][k];
}
}
void Matrix::dot_mul(double x, Matrix& OUT)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
OUT.reweight(weight[i][j][k] * x, i, j, k);
}
}
void Matrix::sub_m(Matrix& OUT, int row_s, int col_s, int chan_s)//从0开始计算
{
for (int i = 0; i < OUT.row; i++)
for (int j = 0; j < OUT.col; j++)
for (int k = 0; k < OUT.chan; k++)
{
OUT.weight[i][j][k] = weight[row_s + i][col_s + j][chan_s + k];
}
}
double Matrix::sum()
{
double rs = 0.0;
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
rs += weight[i][j][k];
return rs;
}
double Matrix::max()
{
double tmp = weight[0][0][0];
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
if (weight[i][j][k] > tmp)
tmp = weight[i][j][k];
}
return tmp;
}
void Matrix::show()
{
for (int k = 0; k < chan; k++)
{
std::cout << "The " << k + 1 << "_th channel:\n";
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
std::cout << weight[i][j][k] << '\t';
}
std::cout << '\n';
}
}
}
double Matrix::value(int r, int c, int ch)
{
return weight[r][c][ch];
}
int Matrix::size()
{
return row * col * chan;
}
void Matrix::zeros()
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
weight[i][j][k] = 0;
}
void Matrix::ones()
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
weight[i][j][k] = 1;
}
void Matrix::neg_ones()
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
weight[i][j][k] = -1;
}
void Matrix::identity()
{
for (int k = 0; k < chan; k++)
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
if (i == j)
weight[i][j][k] = 1;
else
weight[i][j][k] = 0;
}
}
void Matrix::reweight(double x, int r, int c, int ch)
{
weight[r][c][ch] = x;
}
void Matrix::reweight(const Matrix& Mtr, int row_s, int row_e, int col_s, int col_e, int chan_s, int chan_e)
{
if (row_e == -1)
row_e = row - 1;
if (col_e == -1)
col_e = col - 1;
if (chan_e == -1)
chan_e = chan - 1;
for (int i = row_s; i < row_e; i++)
for (int j = col_s; j < col_e; j++)
for (int k = chan_s; k < chan_e; k++)
{
weight[i][j][k] = Mtr.weight[i - row_s][j - col_s][k - chan_s];
}
}
void Matrix::randm()
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
weight[i][j][k] = 0.01 * (rand() % 100);
}
}
void Matrix::gaussrand(double m, double var)
{
for (int k = 0; k < chan; k++)
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
weight[i][j][k] = Functions::gaussrand() * var + m;
}
}
void Matrix::reshape(int r, int c, int ch)
{
if (r == -1)
{
reshape(size(), 1, 1);
return;
}
if (r * c * ch != size())
{
cout << "矩阵改变形状前后元素个数必须保持一致";
exit(0);
}
Matrix Result(r, c, ch);
double* tmp = new double[size()];
int n = 0;
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
tmp[n] = weight[i][j][k];
n++;
}
n = 0;
for (int i = 0; i < r; i++)
for (int j = 0; j < c; j++)
for (int k = 0; k < ch; k++)
{
Result.weight[i][j][k] = tmp[n];
n++;
}
delete[] tmp;
*this = Result;
}
void Matrix::padding(int pad)&
{
Matrix Result(row + pad * 2, col + pad * 2, chan);
Result.zeros();
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
Result.weight[i + pad][j + pad][k] = value(i, j, k);
}
*this = Result;
}
该框架的基本数据结构是一个三维矩阵,每个对象都记录了矩阵的行、列、通道数三维形状信息,并由一个三维指针记录了矩阵的所有元素。
Matrix类还提供了以下函数:
矩阵间的加法、乘法、点乘运算。矩阵与浮点数的点乘、矩阵取子矩阵运算,矩阵元素的求和、取矩阵中所有元素的最大值、向用户显示矩阵中所有元素,取矩阵中指定位置的值、计算矩阵所有元素的个数,对矩阵特定位置的元素重新赋值、使用其它矩阵对原矩阵中的元素批量赋值(用于赋值的矩阵大小要小于被赋值的矩阵)、对矩阵所有元素赋值0、1、-1,将矩阵初始话为单位矩阵,对矩阵每个元素随机赋值[0,1]之间的数、对矩阵每个元素赋值符合高斯分布的数,修改矩阵的形状(修改前后矩阵的元素个数一致),对矩阵执行padding操作(增加矩阵的行数和列数并对新增元素赋值为0)。
二、网络层的实现及正向传播和反向传播的数学推导
2.1. 头文件layers.h
网络层的类中记录了层的形状、类型、输出张量、损失函数对输出输出张量中每个元素的偏导数,权重层还保存有权重数据和前一层的输出张量,以及卷积层进行卷积的步长、padding大小,Dropout层的“抛弃节点概率”等信息。在基本类的基础上实现了输入层、卷积层、激活函数层、最大池化层、全连接层、Dropout层和Softmax层,每个层进行前向传播时都接受前一层的输出张量作为该层的输入张量,输入层则直接接收原始数据作为输出,Softmax层会额外接受网络训练/测试标签和原始数据的真实标签作为输入。每个层进行反向传播时都无需接受其它额外输出,即可求得损失函数对前一层的输出张量各个元素的偏导数。
#pragma once
#include"matrix.h"
#include"functions.h"
#include"yangnet.h"
#include"params.h"
class Layer
{
public:
LAYER_TYPE layer_type;
~Layer();
int row, col, chan;
Matrix y;
Matrix dy;
Conv_params conv_weight;
Fc_params fc_weight;
int stride;
int pad;
int** max_idx;//Maxpool层中存储输入数据mask区域数据最大值的坐标
double loss;
float m_ratio;
int m_label;
Matrix mask;
Matrix input_data;
void Input(int row, int col=1, int chan=1);
void Convolution(int out_row, int out_col, int out_chan, Conv_params &weight, int stride = 1, int pad = 0);
void Relu(int out_row, int out_col=1, int out_chan=1);
void Maxpool(int out_row, int out_col=1, int out_chan=1, int pool_stride = 2);
void Sigmoid(int out_row, int out_col=1, int out_chan=1);
void Affine(int input_size, int out_size, Fc_params &weight);
void Softmax(int out_size);
void Dropout(int out_row, int out_col=1, int out_chan=1, float ratio = 0.5);
void forward(Matrix& input_matrix, bool train_flag = false, int t = SECRET_NUM);
void backward(Matrix& dout2dinput);
};
2.2. 输入层
构造函数的输入为输入数据的形状,以Mnist数据集为例,每张图片的大小为28×28×1,则输入层的输入就是28,28,1,每轮迭代正向传播时该层都会保存原始输入图像的数据,该层直接将原始数据作为输出。
void Layer::Input(int r, int c, int ch)
{
layer_type = INPUT;
row = r;
col = c;
chan = ch;
y = Matrix(r, c, ch);
dy = Matrix(r, c, ch);
}
2.3. 卷积层
这一层保存有卷积层的输出张量形状、padding和卷积步长的大小、卷积滤波器的大小和数量、权重和损失函数对权重的导数、adam优化器所需的其它参数等信息。
void Layer::Convolution(int r, int c, int ch, Conv_params &weight,int p_stride, int p_pad)
{
layer_type = CONVOLUTION;
row = r;
col = c;
chan = ch;
stride = p_stride;
pad = p_pad;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
conv_weight = weight;
}
前向传播:
前向传播函数的输入为前一层的输出张量x,函数输出为卷积层的输出张量y,每个卷积滤波器的权重w都与输入张量x进行卷积操作并加上偏置 b,得到卷积层输出的一个单通道。
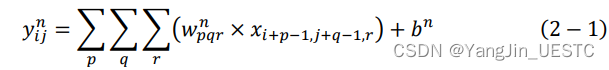

void Layer::forward(Matrix& x, bool train_flag, int t)
{
if (layer_type == CONVOLUTION)
{
double tmp;
input_data = x;
input_data.padding(pad);
for (int k = 0; k < chan; k++)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
tmp = 0;
for (int p = 0; p < conv_weight.row; p++)
for (int q = 0; q < conv_weight.col; q++)
for (int r = 0; r < conv_weight.chan; r++)
{
tmp += conv_weight.w[k].value(p, q, r) * input_data.value(i + p, j + q, r);
}
y.weight[i][j][k] = tmp + conv_weight.b.value(k);
}
}
}
反向传播:
反向传播函数无需额外输入,但需要用到记录的前一层输出张量的值,输出为损失函数对前一层的输出张量各个元素的偏导数


void Layer::backward(Matrix& dx)
{
if (layer_type == CONVOLUTION)
{
double tmp;
for (int i = pad; i < dx.row + pad; i++)
for (int j = pad; j < dx.col + pad; j++)
for (int k = 0; k < dx.chan; k++)
{
tmp = 0;
for (int p = 0; p < conv_weight.row && i >= p; p++)
for (int q = 0; q < conv_weight.col && j >= q; q++)
for (int r = 0; r < conv_weight.num; r++)
{
if (i - p < dy.row && j - q < dy.col)
{
tmp += conv_weight.w[r].value(p, q, k) * dy.value(i - p, j - q, r);
}
}
dx.weight[i - pad][j - pad][k] = tmp;
}
//get dw
//double tmp;
for (int k = 0; k < conv_weight.num; k++)
{
for (int p = 0; p < conv_weight.row; p++)
for (int q = 0; q < conv_weight.col; q++)
for (int r = 0; r < dx.chan; r++)
{
tmp = 0;
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
tmp += dy.value(i, j, k) * input_data.value(i + p, j + q, r);
}
conv_weight.dw[k].weight[p][q][r] = tmp;
}
}
//get db
//double tmp
for (int n = 0; n < conv_weight.num; n++)
{
tmp = 0;
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
tmp += dy.value(i, j, n);
}
conv_weight.db.reweight(tmp, n);
}
}
2.4. 激活函数层
这一层保存有对前一层的输出张量进行激活函数转换后的张量形状信息,以及在基本类中提及的信息。
1)以ReLU为例
void Layer::Relu(int r, int c, int ch)
{
layer_type = RELU;
row = r;
col = c;
chan = ch;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
}
前向传播:
前向传播函数的输入为前一层的输出张量x,函数输出为对x中每个元素做ReLU变换的输出张量y。
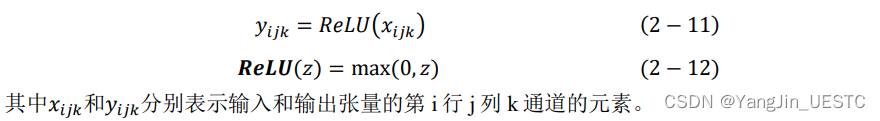
void Layer::forward(Matrix& x, bool train_flag, int t)
{
else if (layer_type == RELU)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
y.weight[i][j][k] = Functions::relu(x.value(i, j, k));
}
}
}
反向传播:
反向传播函数无需额外输入,输出为损失函数对前一层的输出张量各个元素的偏导数

void Layer::backward(Matrix& dx)
{
else if (layer_type == RELU)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
if (y.value(i, j, k) > 0)
dx.weight[i][j][k] = dy.value(i, j, k);
else
dx.weight[i][j][k] = 0;
}
}
}
2)以Sigmoid为例
void Layer::Sigmoid(int r, int c, int ch)
{
layer_type = SIGMOID;
row = r;
col = c;
chan = ch;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
}
前向传播:
与ReLU基本一致,只是对元素进行的变换由ReLU换为Sigmoid。

void Layer::forward(Matrix& x, bool train_flag, int t)
{
else if (layer_type == SIGMOID)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
y.weight[i][j][k] = Functions::sigmoid(x.value(i, j, k));
}
}
}
反向传播:
与ReLU基本一致。

void Layer::backward(Matrix& dx)
{
else if (layer_type == SIGMOID)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
dx.weight[i][j][k] = dy.value(i, j, k) * y.value(i, j, k) * (1.0 - y.value(i, j, k));
}
}
}
2.5. 最大池化层
这一层保存有输出张量的形状信息和池化步长、池化区域大小。另外,为了能保证反向传播的正常进行,还需要保存输入数据的池化区域数据最大值的索引。
void Layer::Maxpool(int r, int c, int ch, int p_stride)
{
layer_type = MAXPOOL;
row = r;
col = c;
chan = ch;
stride = p_stride;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
max_idx = new int* [3];
for (int i = 0; i < 3; i++)
max_idx[i] = new int[row * col * chan];
}
前向传播:
池化按各通道独立进行,池化内核遍历输入数据。前向传播函数的输入为前一层的输出张量x,对x的相应池化区域选择最大值作为池化层输出张量y对应位置的值。
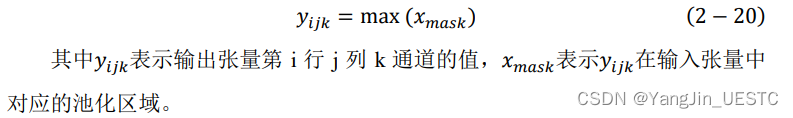
void Layer::forward(Matrix& x, bool train_flag, int t)
{
else if (layer_type == MAXPOOL)
{
double max;
int idx = 0;
for (int k = 0; k < chan; k++)
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
int p = i * stride;
int q = j * stride;
max = x.value(p, q, k);
for (int m = p; m < p + stride; m++)
for (int n = q; n < q + stride; n++)
{
if (x.value(m, n, k) >= max)
{
max = x.value(m, n, k);
max_idx[0][idx] = m;
max_idx[1][idx] = n;
}
}
y.weight[i][j][k] = max;
max_idx[2][idx] = k;
idx++;
}
}
}
反向传播:
反向传播函数无需额外输入,需要用到前向传播时记录的输入张量每个池化区域的最大值坐标索引,输出为损失函数对输入张量每个元素的偏导数。

void Layer::backward(Matrix& dx)
{
else if (layer_type == MAXPOOL)
{
dx.zeros();
int n = 0;
int p, q, r;
for (int i = 0; i < row * col * chan; i++)
{
p = (int)(max_idx[0][n] / stride);
q = (int)(max_idx[1][n] / stride);
r = max_idx[2][n];
dx.weight[max_idx[0][n]][max_idx[1][n]][max_idx[2][n]] = dy.value(p, q, r);
n++;
}
}
}
2.6. 全连接层
这一层保存有全连接层的输出张量形状和输入张量的大小,以及全连接层节点的权重和损失函数对权重的导数、Adam优化器所需的其它参数等信息。
void Layer::Affine(int in_size, int out_size, Fc_params& weight)
{
layer_type = AFFINE;
row = out_size;
y = Matrix(out_size);
dy = Matrix(out_size);
fc_weight = weight;
}
前向传播:
该层前向传播的一个节点的输出为对输入张量x中的每个元素用该节点上的所有权重做乘法求和并加以偏置b后的值,所有节点的输出构成的张量即该层的输出张量。

void Layer::forward(Matrix& x, bool train_flag, int t)
{
else if (layer_type == AFFINE)
{
Matrix x_copy = x;
x_copy.reshape(-1);
input_data = x_copy;
double tmp;
for (int j = 0; j < row; j++)
{
tmp = 0;
for (int i = 0; i < x.size(); i++)
{
tmp += x_copy.value(i) * fc_weight.w.value(i, j);
}
y.reweight(tmp + fc_weight.b, j);
}
}
}
反向传播:
反向传播函数无需额外输入,但需要用到记录的前一层输出张量的值,输出为损失函数对前一层的输出张量各个元素的偏导数。
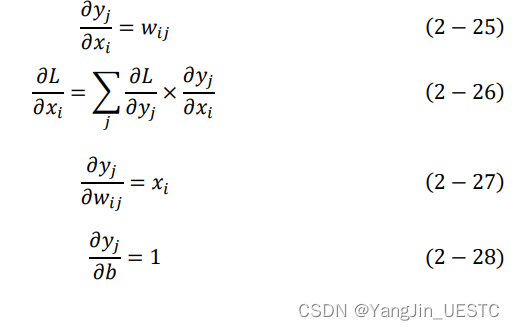

void Layer::backward(Matrix& dx)
{
else if (layer_type == AFFINE)
{
int r_orgi, c_orgi, ch_orgi;
r_orgi = dx.row;
c_orgi = dx.col;
ch_orgi = dx.chan;
dx.reshape(-1);
double tmp;
double db_tmp = 0;
for (int i = 0; i < dx.size(); i++)
{
tmp = 0;
for (int j = 0; j < row; j++)
{
tmp += dy.value(j) * fc_weight.w.value(i, j);
fc_weight.dw.weight[i][j][0] = dy.value(j) * input_data.value(i);
if (i == 0)
{
db_tmp += dy.value(j);
}
}
dx.reweight(tmp, i);
if (i == 0)
fc_weight.db = db_tmp;
}
dx.reshape(r_orgi, c_orgi, ch_orgi);
}
}
2.7. Softmax层
这一层保存有分类器的分类类别数量(即该层输出向量的大小)以及网络输入数据的真实标签,一般而言,这一层会放在网络的最后,所以也会计算网络的loss值。
void Layer::Softmax(int out_size)
{
layer_type = SOFTMAX;
row = out_size;
y = Matrix(row);
}
前向传播:
前向传播函数的输入为网络输入数据的真实标签(会保存用于反向传播时使用),以及网络的训练/测试标签(在网络的训练阶段和测试阶段这一层会执行不同操作)。输入为前一层的输出张量x,对输入张量x进行softmax操作即可得到这一层的输出张量y。

void Layer::forward(Matrix& x, bool train_flag, int t)
{
else if (layer_type == SOFTMAX)
{
if (t == SECRET_NUM)
{
Functions::softmax(x, y);
}
else
{
m_label = t;
Functions::softmax(x, y);
loss = -log(y.value(m_label));
}
}
}
反向传播:
反向传播函数无需额外输入,但需要用到正向传播时记录的网络输入数据的真实标签,输出为损失函数对前一层的输出张量各个元素的偏导数。

对式(2-35),其中p_t表示网络对正确解标签的输出概率,不妨将loss记作L,t为正确解标签。则有:

void Layer::backward(Matrix& dx)
{
else if (layer_type == SOFTMAX)
{
for (int i = 0; i < row; i++)
{
if (i == m_label)
dx.reweight(y.value(i) - 1.0, i);
else
dx.reweight(y.value(i), i);
}
}
}
2.8. Dropout层
Dropout层通常接在全连接层之后,按一定的概率“抛弃”全连接层的节点。因此这一层保存有节点失活概率和节点失活后的输出张量,并保存有网络的训练/测试标签,并在网络训练过程中要保留失活节点的位置信息。
void Layer::Dropout(int r, int c, int ch, float ratio)
{
layer_type = DROPOUT;
m_ratio = ratio;
row = r;
col = c;
chan = ch;
y = Matrix(r, c, ch);
dy = Matrix(r, c, ch);
mask = Matrix(r, c, ch);
}
前向传播:
前向传播函数的输入为前一层(通常是全连接层)的输出张量x,当网络在进行训练时,对x中的每个元素按概率置零后并进行等比拉伸操作得到这一层的输出张量y;而当网络在进行测试时,则不进行任何操作,直接将输入张量作为输出张量。如下所示:
当网络进行训练时:
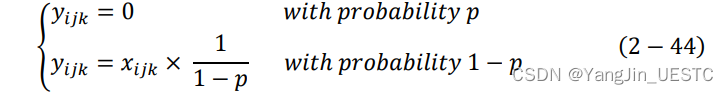
当网络进行测试时:

void Layer::forward(Matrix& x, bool train_flag, int t)
{
else if (layer_type == DROPOUT)
{
if (train_flag)
{
mask.randm();
for (int i = 0; i < x.row; i++)
for (int j = 0; j < x.col; j++)
for (int k = 0; k < x.chan; k++)
{
if (mask.value(i, j, k) < m_ratio)
mask.reweight(0.0, i, j, k);
else
mask.reweight(1.0, i, j, k);
}
x.dot_mul(mask, y);
y.dot_mul(1.0 / (1.0 - m_ratio), y);
}
else
y = x;
}
}

void Layer::backward(Matrix& dx)
{
else if (layer_type == DROPOUT)
{
dy.dot_mul(mask, dx);
dx.dot_mul(1.0 / (1.0 - m_ratio), dx);
}
}
2.9. 源文件layers.cpp
本节是对网络层所有源代码的汇总,如下所示
#include "layers.h"
Layer::~Layer()
{
if (layer_type == MAXPOOL)
{
for (int i = 0; i < 3; i++)
delete max_idx[i];
delete max_idx;
}
}
void Layer::Input(int r, int c, int ch)
{
layer_type = INPUT;
row = r;
col = c;
chan = ch;
y = Matrix(r, c, ch);
dy = Matrix(r, c, ch);
}
void Layer::Convolution(int r, int c, int ch, Conv_params &weight,int p_stride, int p_pad)
{
layer_type = CONVOLUTION;
row = r;
col = c;
chan = ch;
stride = p_stride;
pad = p_pad;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
conv_weight = weight;
}
void Layer::Relu(int r, int c, int ch)
{
layer_type = RELU;
row = r;
col = c;
chan = ch;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
}
void Layer::Maxpool(int r, int c, int ch, int p_stride)
{
layer_type = MAXPOOL;
row = r;
col = c;
chan = ch;
stride = p_stride;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
max_idx = new int* [3];
for (int i = 0; i < 3; i++)
max_idx[i] = new int[row * col * chan];
}
void Layer::Sigmoid(int r, int c, int ch)
{
layer_type = SIGMOID;
row = r;
col = c;
chan = ch;
y = Matrix(row, col, chan);
dy = Matrix(row, col, chan);
}
void Layer::Affine(int in_size, int out_size, Fc_params& weight)
{
layer_type = AFFINE;
row = out_size;
y = Matrix(out_size);
dy = Matrix(out_size);
fc_weight = weight;
}
void Layer::Softmax(int out_size)
{
layer_type = SOFTMAX;
row = out_size;
y = Matrix(row);
}
void Layer::Dropout(int r, int c, int ch, float ratio)
{
layer_type = DROPOUT;
m_ratio = ratio;
row = r;
col = c;
chan = ch;
y = Matrix(r, c, ch);
dy = Matrix(r, c, ch);
mask = Matrix(r, c, ch);
}
void Layer::forward(Matrix& x, bool train_flag, int t)
{
if (layer_type == CONVOLUTION)
{
double tmp;
input_data = x;
input_data.padding(pad);
for (int k = 0; k < chan; k++)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
tmp = 0;
for (int p = 0; p < conv_weight.row; p++)
for (int q = 0; q < conv_weight.col; q++)
for (int r = 0; r < conv_weight.chan; r++)
{
tmp += conv_weight.w[k].value(p, q, r) * input_data.value(i + p, j + q, r);
}
y.weight[i][j][k] = tmp + conv_weight.b.value(k);
}
}
}
else if (layer_type == RELU)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
y.weight[i][j][k] = Functions::relu(x.value(i, j, k));
}
}
else if (layer_type == MAXPOOL)
{
double max;
int idx = 0;
for (int k = 0; k < chan; k++)
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
int p = i * stride;
int q = j * stride;
max = x.value(p, q, k);
for (int m = p; m < p + stride; m++)
for (int n = q; n < q + stride; n++)
{
if (x.value(m, n, k) >= max)
{
max = x.value(m, n, k);
max_idx[0][idx] = m;
max_idx[1][idx] = n;
}
}
y.weight[i][j][k] = max;
max_idx[2][idx] = k;
idx++;
}
}
else if (layer_type == SIGMOID)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
y.weight[i][j][k] = Functions::sigmoid(x.value(i, j, k));
}
}
else if (layer_type == AFFINE)
{
Matrix x_copy = x;
x_copy.reshape(-1);
input_data = x_copy;
double tmp;
for (int j = 0; j < row; j++)
{
tmp = 0;
for (int i = 0; i < x.size(); i++)
{
tmp += x_copy.value(i) * fc_weight.w.value(i, j);
}
y.reweight(tmp + fc_weight.b, j);
}
}
else if (layer_type == SOFTMAX)
{
if (t == SECRET_NUM)
{
Functions::softmax(x, y);
}
else
{
m_label = t;
Functions::softmax(x, y);
loss = -log(y.value(m_label));
}
}
else if (layer_type == DROPOUT)
{
if (train_flag)
{
mask.randm();
for (int i = 0; i < x.row; i++)
for (int j = 0; j < x.col; j++)
for (int k = 0; k < x.chan; k++)
{
if (mask.value(i, j, k) < m_ratio)
mask.reweight(0.0, i, j, k);
else
mask.reweight(1.0, i, j, k);
}
x.dot_mul(mask, y);
y.dot_mul(1.0 / (1.0 - m_ratio), y);
}
else
y = x;
}
}
void Layer::backward(Matrix& dx)
{
if (layer_type == CONVOLUTION)
{
double tmp;
for (int i = pad; i < dx.row + pad; i++)
for (int j = pad; j < dx.col + pad; j++)
for (int k = 0; k < dx.chan; k++)
{
tmp = 0;
for (int p = 0; p < conv_weight.row && i >= p; p++)
for (int q = 0; q < conv_weight.col && j >= q; q++)
for (int r = 0; r < conv_weight.num; r++)
{
if (i - p < dy.row && j - q < dy.col)
{
tmp += conv_weight.w[r].value(p, q, k) * dy.value(i - p, j - q, r);
}
}
dx.weight[i - pad][j - pad][k] = tmp;
}
//get dw
//double tmp;
for (int k = 0; k < conv_weight.num; k++)
{
for (int p = 0; p < conv_weight.row; p++)
for (int q = 0; q < conv_weight.col; q++)
for (int r = 0; r < dx.chan; r++)
{
tmp = 0;
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
tmp += dy.value(i, j, k) * input_data.value(i + p, j + q, r);
}
conv_weight.dw[k].weight[p][q][r] = tmp;
}
}
//get db
//double tmp
for (int n = 0; n < conv_weight.num; n++)
{
tmp = 0;
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
{
tmp += dy.value(i, j, n);
}
conv_weight.db.reweight(tmp, n);
}
}
else if (layer_type == RELU)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
if (y.value(i, j, k) > 0)
dx.weight[i][j][k] = dy.value(i, j, k);
else
dx.weight[i][j][k] = 0;
}
}
else if (layer_type == MAXPOOL)
{
dx.zeros();
int n = 0;
int p, q, r;
for (int i = 0; i < row * col * chan; i++)
{
p = (int)(max_idx[0][n] / stride);
q = (int)(max_idx[1][n] / stride);
r = max_idx[2][n];
dx.weight[max_idx[0][n]][max_idx[1][n]][max_idx[2][n]] = dy.value(p, q, r);
n++;
}
}
else if (layer_type == SIGMOID)
{
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
for (int k = 0; k < chan; k++)
{
dx.weight[i][j][k] = dy.value(i, j, k) * y.value(i, j, k) * (1.0 - y.value(i, j, k));
}
}
else if (layer_type == AFFINE)
{
int r_orgi, c_orgi, ch_orgi;
r_orgi = dx.row;
c_orgi = dx.col;
ch_orgi = dx.chan;
dx.reshape(-1);
double tmp;
double db_tmp = 0;
for (int i = 0; i < dx.size(); i++)
{
tmp = 0;
for (int j = 0; j < row; j++)
{
tmp += dy.value(j) * fc_weight.w.value(i, j);
fc_weight.dw.weight[i][j][0] = dy.value(j) * input_data.value(i);
if (i == 0)
{
db_tmp += dy.value(j);
}
}
dx.reweight(tmp, i);
if (i == 0)
fc_weight.db = db_tmp;
}
dx.reshape(r_orgi, c_orgi, ch_orgi);
}
else if (layer_type == SOFTMAX)
{
for (int i = 0; i < row; i++)
{
if (i == m_label)
dx.reweight(y.value(i) - 1.0, i);
else
dx.reweight(y.value(i), i);
}
}
else if (layer_type == DROPOUT)
{
dy.dot_mul(mask, dx);
dx.dot_mul(1.0 / (1.0 - m_ratio), dx);
}
}
三、框架的通用函数
头文件function.h
#pragma once
#ifndef functions_H_
#define functions_H_
#endif
#include"matrix.h"
#include<math.h>
class Functions
{
friend class Matrix;
public:
static double relu(double x);
static void relu(Matrix& X, Matrix& OUT);
static double sigmoid(double x);
static void sigmoid(Matrix& X, Matrix& OUT);
static void softmax(Matrix& X, Matrix& OUT);
static double gaussrand();
static double cross_entropy_error(Matrix& y, int& label);
static double cross_entropy_error(Matrix& y, int*& label);
};
源文件
#include"functions.h"
double Functions::relu(double x)
{
double y = x > 0 ? x : 0;
return y;
}
void Functions::relu(Matrix& X, Matrix& OUT)
{
for (int i = 0; i < X.row; i++)
for (int j = 0; j < X.col; j++)
for (int k = 0; k < X.chan; k++)
OUT.weight[i][j][k] = X.value(i, j, k) > 0 ? X.value(i, j, k) : 0;
}
double Functions::sigmoid(double x)
{
return 1.0 / (1.0 + exp(-x));
}
void Functions::sigmoid(Matrix& X, Matrix& OUT)
{
Matrix Y(X.row, X.col, X.chan);
for (int i = 0; i < X.row; i++)
for (int j = 0; j < X.col; j++)
for (int k = 0; k < X.chan; k++)
Y.weight[i][j][k] = 1.0 / (1.0 + exp(-X.value(i, j, k)));
OUT = Y;
}
void Functions::softmax(Matrix& X, Matrix& OUT)
{
double max = X.max();
double sum = 0.0;
for (int i = 0; i < X.size(); i++)
{
sum += exp(X.value(i) - max);
// sum += exp(X.value(i));
}
for (int i = 0; i < X.size(); i++)
{
OUT.weight[i][0][0] = exp((X.value(i) - max)) / sum;
// OUT.weight[i][0][0] = exp(X.value(i)) / sum;
}
}
double Functions::gaussrand()
{
static double V1, V2, S;
static int phase = 0;
double X;
if (phase == 0) {
do {
double U1 = (double)rand() / RAND_MAX;
double U2 = (double)rand() / RAND_MAX;
V1 = 2 * U1 - 1;
V2 = 2 * U2 - 1;
S = V1 * V1 + V2 * V2;
} while (S >= 1 || S == 0);
X = V1 * sqrt(-2 * log(S) / S);
}
else
X = V2 * sqrt(-2 * log(S) / S);
phase = 1 - phase;
return X;
}
double Functions::cross_entropy_error(Matrix& y, int& label)
{
double loss = 0.0;
loss = -log(y.value(label) + exp(-7));
return loss;
}
double Functions::cross_entropy_error(Matrix& y, int*& label)
{
int batch_size = y.row;
double loss = 0.0;
for (int i = 0; i < batch_size; i++)
{
loss += -log(y.value(label[i], i) + exp(-7));
}
loss /= batch_size;
return loss;
}
relu、sigmoid和softmax函数是用于激活函数层的函数,gaussrand函数用于产生符合均值为0,方差为1的高斯分布的浮点数。cross_entropy_error函数用于在神经网络的Softmax层中计算交叉熵误差。
四、网络权重层的权重参数类
头文件params.h
#pragma once
#include"matrix.h"
#include"yangnet.h"
class Conv_params
{
public:
int num;
int row;
int col;
int chan;
Matrix* w;
Matrix* dw;
Matrix b;
Matrix db;
Matrix *w_m;
Matrix *w_v;
Matrix b_m;
Matrix b_v;
Conv_params(int filter_num = 0, int filter_row = 0, int filter_col = 0, int filter_chan = 0);
void show();
};
class Fc_params
{
public:
int in_size;
int out_size;
Matrix w;
Matrix dw;
double b;
double db;
Matrix w_m;
Matrix w_v;
double b_m;
double b_v;
Fc_params(int input_size = 0, int output_size = 0);
void show();
};
class Params
{
public:
//int batch_size;
int iter;
//adam参数
double beta1 = 0.9;
double beta2 = 0.999;
double epsilon = exp(-8);
Conv_params* conv_params;
Fc_params* fc_params;
int conv_layer_num, fc_layer_num;
double m_learning_rate;
Params(int CONV_LAYER_NUM = 0, int FC_LAYER_NUM = 0, double learning_rate = 0.01);
void init(WEIGHT_INI_METHOD method,double AVE=0.0,double VAR=1.0);
void update(OPTIMIZER method);
};
源文件params.cpp
#include "params.h"
Conv_params::Conv_params(int filter_num, int filter_row, int filter_col, int filter_chan)
{
num = filter_num;
row = filter_row;
col = filter_col;
chan = filter_chan;
w = new Matrix[filter_num];
dw = new Matrix[filter_num];
w_m= new Matrix[filter_num];
w_v = new Matrix[filter_num];
for (int i = 0; i < filter_num; i++)
{
w[i] = Matrix(filter_row, filter_col, filter_chan);
dw[i] = Matrix(filter_row, filter_col, filter_chan);
w_m[i] = Matrix(filter_row, filter_col, filter_chan);
w_v[i] = Matrix(filter_row, filter_col, filter_chan);
w_m[i].zeros();
w_v[i].zeros();
}
b = Matrix(filter_num);
db = Matrix(filter_num);
b_m = Matrix(filter_num);
b_v = Matrix(filter_num);
b_m.zeros();
b_v.zeros();
}
void Conv_params::show()
{
for (int i = 0; i < num; i++)
{
w[i].show();
}
}
Fc_params::Fc_params(int input_size, int output_size)
{
in_size = input_size;
out_size = output_size;
w = Matrix(in_size, out_size);
dw = Matrix(in_size, out_size);
w_m = Matrix(in_size, out_size);
w_v = Matrix(in_size, out_size);
w_m.zeros();
w_v.zeros();
b_m = 0;
b_v = 0;
}
void Fc_params::show()
{
w.show();
}
Params::Params(int conv_num, int fc_num,double lr)
{
m_learning_rate = lr;
conv_layer_num = conv_num;
fc_layer_num = fc_num;
conv_params = new Conv_params[conv_num];
fc_params = new Fc_params[fc_num];
iter = 0;
}
void Params::init(WEIGHT_INI_METHOD method,double ave,double var)
{
if (method == GAUSS)
{
for (int i = 0; i < conv_layer_num; i++)
{
for (int j = 0; j < conv_params[i].num; j++)
{
conv_params[i].w[j].gaussrand(ave, var);
}
conv_params[i].b.zeros();
}
for (int i = 0; i < fc_layer_num; i++)
{
fc_params[i].w.gaussrand(ave, var);
fc_params[i].b = 0.0;
}
}
}
void Params::update(OPTIMIZER method)
{
if (method == SGD)
{
for (int p = 0; p < conv_layer_num; p++)
{
for (int q = 0; q < conv_params[p].num; q++)
{
for (int i = 0; i < conv_params[p].row; i++)
for (int j = 0; j < conv_params[p].col; j++)
for (int k = 0; k < conv_params[p].chan; k++)
{
conv_params[p].w[q].weight[i][j][k] -=
m_learning_rate * conv_params[p].dw[q].weight[i][j][k];
}
conv_params[p].b.weight[q][0][0] -= m_learning_rate * conv_params[p].db.value(q);
}
}
for (int p = 0; p < fc_layer_num; p++)
{
fc_params[p].b -= m_learning_rate * fc_params[p].db;
for (int i = 0; i < fc_params[p].in_size; i++)
for (int j = 0; j < fc_params[p].out_size; j++)
{
fc_params[p].w.weight[i][j][0] -= m_learning_rate * fc_params[p].dw.weight[i][j][0];
}
}
}
else if (method == ADAM)
{
iter += 1;
const double lr_t = m_learning_rate * sqrt((1.0 - pow(beta2, iter)) / (1.0 - pow(beta1, iter)));
for (int p = 0; p < conv_layer_num; p++)
{
for (int q = 0; q < conv_params[p].num; q++)
{
for (int i = 0; i < conv_params[p].row; i++)
for (int j = 0; j < conv_params[p].col; j++)
for (int k = 0; k < conv_params[p].chan; k++)
{
conv_params[p].w_m[q].weight[i][j][k] += (1.0 - beta1) * (conv_params[p].dw[q].weight[i][j][k] - conv_params[p].w_m[q].weight[i][j][k]);
conv_params[p].w_v[q].weight[i][j][k] += (1.0 - beta2) * (pow(conv_params[p].dw[q].weight[i][j][k], 2) - conv_params[p].w_v[q].weight[i][j][k]);
conv_params[p].w[q].weight[i][j][k] -= lr_t * (conv_params[p].w_m[q].weight[i][j][k] / (sqrt(conv_params[p].w_v[q].weight[i][j][k]) + epsilon));
}
conv_params[p].b_m.weight[q][0][0] += (1.0 - beta1) * (conv_params[p].db.value(q) - conv_params[p].b_m.weight[q][0][0]);
conv_params[p].b_v.weight[q][0][0] += (1.0 - beta2) * (pow(conv_params[p].db.value(q), 2) - conv_params[p].b_v.weight[q][0][0]);
conv_params[p].b.weight[q][0][0] -= lr_t * (conv_params[p].b_m.weight[q][0][0] / (sqrt(conv_params[p].b_v.weight[q][0][0]) + epsilon));
}
}
for (int p = 0; p < fc_layer_num; p++)
{
fc_params[p].b_m += (1.0 - beta1) * (fc_params[p].db - fc_params[p].b_m);
fc_params[p].b_v += (1.0 - beta2) * (pow(fc_params[p].db, 2) - fc_params[p].b_v);
fc_params[p].b -= lr_t * (fc_params[p].b_m / (sqrt(fc_params[p].b_v) + epsilon));
for (int i = 0; i < fc_params[p].in_size; i++)
for (int j = 0; j < fc_params[p].out_size; j++)
{
fc_params[p].w_m.weight[i][j][0] += (1.0 - beta1) * (fc_params[p].dw.value(i, j) - fc_params[p].w_m.weight[i][j][0]);
fc_params[p].w_v.weight[i][j][0] += (1.0 - beta2) * (pow(fc_params[p].dw.value(i, j), 2) - fc_params[p].w_v.weight[i][j][0]);
fc_params[p].w.weight[i][j][0] -= lr_t * (fc_params[p].w_m.weight[i][j][0] / (sqrt(fc_params[p].w_v.weight[i][j][0]) + epsilon));
}
}
}
}
网络的权重参数主要有卷积层权重参数和全连接层权重参数,卷积层权重的参数有滤波器的形状、数量,还需要记录使用adam等优化算法时用到的动量等中间变量,以及滤波器的权重值和偏置值。全连接层的权重参数有输入向量和输出向量的大小,以及使用adam等优化算法时用到的中间变量,还有权重值矩阵和偏置值。目前对网络权重参数的初始化已经实现了两种方法,分别是高斯初始化和平均初始化,对偏置值均置零处理。网络权重的更新也实现了两种方法,分别是SGD优化算法和Adam优化算法。
SGD的算法原理非常简单,此处不展开赘述。下面详细介绍Adam的算法原理。

ADAM算法:

五、网络基类
为了方便实现其它复杂神经网络,框架实现了一个基类,其它神经网络可以通过该基类来实现。保存有网络层的数量、网络层、权重参数、权重层数量、迭代次数、每次输入数据的批次大小、输入数据的真实标签、迭代的loss值等信息,并实现了网络的前向传播和反向传播函数,同时能实现网络权重参数的更新。
头文件network.h
#pragma once
#include"layers.h"
class Network
{
public:
int layer_num;//网络的输入也作为单独的一层来处理
Layer* layers;
Params params;
int conv_layer_num, fc_layer_num;
int epochs;
int batch_size;
int ground_truth;
double m_loss;
Network(int layer_n);
~Network();
int predict();
void loss(int t = SECRET_NUM);
void update(OPTIMIZER method);
void show();
};
源文件network.cpp
#include "network.h"
Network::Network(int layer_n)
{
layer_num = layer_n;
layers = new Layer[layer_num];
}
Network::~Network()
{
delete[] layers;
}
int Network::predict()
{
int predict_result = 0;
double max;
for (int i = 1; i < layer_num; i++)
layers[i].forward(layers[i - 1].y);
max = layers[layer_num - 1].y.value(0);
for (int i = 0; i < layers[layer_num - 1].y.size() - 1; i++)
{
if (layers[layer_num - 1].y.value(i + 1) > max)
{
max = layers[layer_num - 1].y.value(i + 1);
predict_result = i + 1;
}
}
return predict_result;
}
void Network::loss(int t)
{
for (int i = 1; i < layer_num; i++)
{
layers[i].forward(layers[i - 1].y, true, t);
}
m_loss = layers[layer_num - 1].loss;
}
void Network::update(OPTIMIZER method)
{
for (int i = layer_num - 1; i > 0; i--)
{
layers[i].backward(layers[i - 1].dy);
}
//把层中的权重传到网络
for (int i = 0, p = 0, q = 0; i < layer_num - 1; i++)
{
if (layers[i].layer_type == CONVOLUTION)
{
params.conv_params[p] = layers[i].conv_weight;
p++;
}
if (layers[i].layer_type == AFFINE)
{
params.fc_params[q] = layers[i].fc_weight;
q++;
}
}
//权重更新
params.update(method);
//把网络中的权重传到层
for (int i = 0, p = 0, q = 0; i < layer_num - 1; i++)
{
if (layers[i].layer_type == CONVOLUTION)
{
layers[i].conv_weight = params.conv_params[p];
p++;
}
if (layers[i].layer_type == AFFINE)
{
layers[i].fc_weight = params.fc_params[q];
q++;
}
}
}
void Network::show()
{
for (int i = 0; i < layer_num; i++)
layers[i].y.show();
}
网络的前向传播
网络首先通过输入层获取原始数据,将每一层的输出数据作为下一层的输入数据,前向传播过程抵达网络最后一层时,经过softmax分类器可以得到网络此时对输入数据的分类情况,即可输出分类结果,并得到网络此时的loss值。
网络的反向传播和参数更新
网络首先从最后一层开始,将损失函数对每一层输出数据的偏导数作为前一层的输入,直到网络最前端,在此过程中,可以求得损失函数对网络全部权重参数的偏导数,随后便可以实现网络权重参数的更新。
网络训练过程
在每轮迭代中, 网络首先获取输入数据,随后进行前向传播求loss值,随后再进行一轮反向传播,求得损失函数对网络权重的偏导数,再利用SGD或其它优化算法对网络权重进行更新。
六、实验:基于YangNet完成手写数字识别任务(MNIST数据集)
6.1. MNIST数据集介绍
MNIST数据集下载地址:http://yann.lecun.com/exdb/mnist/
本次实验通过MNIST数据集来测试本文提出深度学习框架的有效性,MNIST数据集由250个人的手写数字图片组成,其中二分之一来自高中生群体,二分之一来自人口普查局工作人员。它由NIST(美国国家标准与技术研究所)发起整理。该数据集收集的目的是人们希望计算机能够通过某种算法实现对手写数字的自动识别,有很高的研究价值和社会应用需求。自MNIST数据集被发布以来,它被广泛地用于学术研究,测试算法的性能。MINST数据集的主要应用领域是机器学习和深度学习,很多机器学习和深度学习算法都可以使用MNIST数据集进行测试,比如支持向量机、神经网络、K-近邻算法等等。
MNIST数据集中有6万张训练图片和1万张测试图片,对应的正确解标签是数字0到9,每张图像都是单通道灰度图像,图像大小都标准化为28像素×28像素的矩阵形式,像素的取值范围是[0,255]中的整数。
MNIST的读取程序:(这里要把数据集放在程序同一目录下)
头文件mnist.h
#pragma once
#include<vector>
#include<string>
#include <ios>
#include <fstream>
#include"matrix.h"
#include<iostream>
using namespace std;
class Mnist
{
public:
enum flag { train = 0, test = 1 };
const int max_train_num = 60000;
const int max_test_num = 10000;
Mnist(int data_norm = 1);
vector<double>train_labels;
vector<vector<double> >train_images;//训练集
vector<double>test_labels;
vector<vector<double> >test_images;//测试集
void load_data(Matrix& Network_input, Matrix& label, int n_th_image, flag source);//如果同时将多张图像作为输入,则n_th_image为首张图像的索引
};
源文件mnist.cpp
#include "mnist.h"
/**************************此段为读取MNIST数据集模块**************/
int ReverseInt(int i)
{
unsigned char ch1, ch2, ch3, ch4;
ch1 = i & 255;
ch2 = (i >> 8) & 255;
ch3 = (i >> 16) & 255;
ch4 = (i >> 24) & 255;
return((int)ch1 << 24) + ((int)ch2 << 16) + ((int)ch3 << 8) + ch4;
}
void read_Mnist_Label(string filename, vector<double>& labels)
{
ifstream file;
file.open("train-labels.idx1-ubyte", ios::binary);
if (file.is_open())
{
int magic_number = 0;
int number_of_images = 0;
file.read((char*)&magic_number, sizeof(magic_number));
file.read((char*)&number_of_images, sizeof(number_of_images));
magic_number = ReverseInt(magic_number);
number_of_images = ReverseInt(number_of_images);
for (int i = 0; i < number_of_images; i++)
{
unsigned char label = 0;
file.read((char*)&label, sizeof(label));
labels.push_back((double)label);
}
}
}
void read_Mnist_Images(string filename, vector<vector<double> >& images)
{
ifstream file("train-images.idx3-ubyte", ios::binary);
if (file.is_open())
{
int magic_number = 0;
int number_of_images = 0;
int n_rows = 0;
int n_cols = 0;
unsigned char label;
file.read((char*)&magic_number, sizeof(magic_number));
file.read((char*)&number_of_images, sizeof(number_of_images));
file.read((char*)&n_rows, sizeof(n_rows));
file.read((char*)&n_cols, sizeof(n_cols));
magic_number = ReverseInt(magic_number);
number_of_images = ReverseInt(number_of_images);
n_rows = ReverseInt(n_rows);
n_cols = ReverseInt(n_cols);
for (int i = 0; i < number_of_images; i++)
{
vector<double>tp;
for (int r = 0; r < n_rows; r++)
{
for (int c = 0; c < n_cols; c++)
{
unsigned char image = 0;
file.read((char*)&image, sizeof(image));
tp.push_back(image);
}
}
images.push_back(tp);
}
}
}
void read_Mnist_Label1(string filename, vector<double>& labels)
{
ifstream file;
file.open("t10k-labels.idx1-ubyte", ios::binary);
if (file.is_open())
{
int magic_number = 0;
int number_of_images = 0;
file.read((char*)&magic_number, sizeof(magic_number));
file.read((char*)&number_of_images, sizeof(number_of_images));
magic_number = ReverseInt(magic_number);
number_of_images = ReverseInt(number_of_images);
for (int i = 0; i < number_of_images; i++)
{
unsigned char label = 0;
file.read((char*)&label, sizeof(label));
labels.push_back((double)label);
}
}
}
void read_Mnist_Images1(string filename, vector<vector<double> >& images)
{
ifstream file("t10k-images.idx3-ubyte", ios::binary);
if (file.is_open())
{
int magic_number = 0;
int number_of_images = 0;
int n_rows = 0;
int n_cols = 0;
unsigned char label;
file.read((char*)&magic_number, sizeof(magic_number));
file.read((char*)&number_of_images, sizeof(number_of_images));
file.read((char*)&n_rows, sizeof(n_rows));
file.read((char*)&n_cols, sizeof(n_cols));
magic_number = ReverseInt(magic_number);
number_of_images = ReverseInt(number_of_images);
n_rows = ReverseInt(n_rows);
n_cols = ReverseInt(n_cols);
for (int i = 0; i < number_of_images; i++)
{
vector<double>tp;
for (int r = 0; r < n_rows; r++)
{
for (int c = 0; c < n_cols; c++)
{
unsigned char image = 0;
file.read((char*)&image, sizeof(image));
tp.push_back(image);
}
}
images.push_back(tp);
}
}
}
/**************************************************************/
Mnist::Mnist(int data_norm)
{
read_Mnist_Label("t10k-labels.idx1-ubyte", train_labels);
read_Mnist_Images("t10k-images.idx3-ubyte", train_images);
read_Mnist_Label1("t10k-labels.idx1-ubyte", test_labels);
read_Mnist_Images1("t10k-images.idx3-ubyte", test_images);//读取mnist数据集
if (data_norm == 1)
{
for (int i = 0; i < train_images.size(); i++)
for (int j = 0; j < train_images[0].size(); j++)
{
train_images[i][j] /= 255.0;
}
for (int i = 0; i < test_images.size(); i++)
for (int j = 0; j < test_images[0].size(); j++)
{
test_images[i][j] /= 255.0;
}
}
}
void Mnist::load_data(Matrix& x, Matrix& label, int n, flag source)
{
int idx;
if (source == train)
{
for (int k = 0; k < x.chan; k++)
{
idx = 0;
label.reweight(train_labels[n + k], k);
for (int i = 0; i < x.row; i++)
for (int j = 0; j < x.col; j++)
{
x.weight[i][j][k] = train_images[n + k][idx];
idx++;
}
}
}
else if (source == test)
{
for (int k = 0; k < x.chan; k++)
{
idx = 0;
label.reweight(test_labels[n + k], k);
for (int i = 0; i < x.row; i++)
for (int j = 0; j < x.col; j++)
{
x.weight[i][j][k] = test_images[n + k][idx];
idx++;
}
}
}
else
{
cout << "load dataset failed\n";
exit(-1);
}
}
6.2. 实验方法和结果
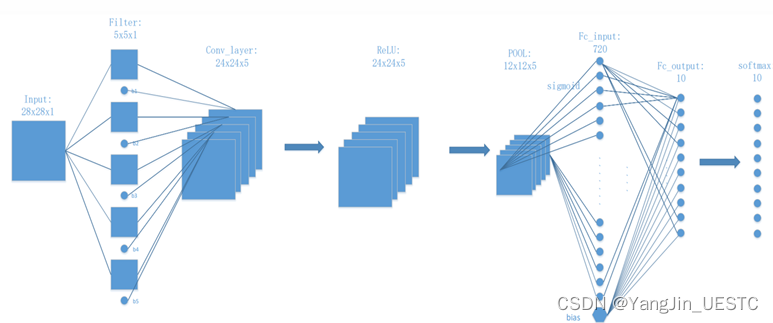
下图是一个7层的卷积神经网络,网络组成为:输入层-卷积层-ReLU激活函数层-最大池化层-Sigmoid激活函数层-全连接层-Softmax层。
网络的程序实现:
头文件simple_convnet.h:
#pragma once
#include"layers.h"
#include"mnist.h"
#include"network.h"
using namespace std;
class Simple_convnet: public Network
{
private:
const int out_size = 10;
const double learning_rate = 0.01;
const int train_num =20000;
const int test_num = 5000;
Mnist mnist;
int m_batch_size;
const int epochs = 100;
public:
Matrix labels;
Simple_convnet();
void train_net();
void test_net();
};
源文件simple_convnet.cpp
#include "simple_convnet.h"
Simple_convnet::Simple_convnet() :Network(layer_num = 7)
{
cout << "Constructing Convolution Network begins\n";
/*
//深层网络,layer_num=13
params = Params(2, 2);
params.conv_params[0] = Conv_params(6, 5, 5, 1);
params.conv_params[1] = Conv_params(16, 5, 5, 6);
params.fc_params[0] = Fc_params(256, 100);
params.fc_params[1] = Fc_params(100, 10);
params.init(GAUSS);
layers[0].Input(28, 28, 1);
layers[1].Convolution(24, 24, 6, params.conv_params[0]);
layers[2].Relu(24, 24, 6);
layers[3].Maxpool(12, 12, 6);
layers[4].Convolution(8, 8, 16, params.conv_params[1]);
layers[5].Relu(8, 8, 16);
layers[6].Maxpool(4, 4, 16);
layers[7].Sigmoid(4, 4, 16);
layers[8].Affine(256, 100, params.fc_params[0]);
layers[9].Dropout(100);
layers[10].Sigmoid(100);
layers[11].Affine(100, 10, params.fc_params[1]);
layers[12].Softmax(10);
*/
//浅层网络,layer_num=7
params = Params(1, 1);
params.conv_params[0] = Conv_params(5, 5, 5, 1);
params.fc_params[0] = Fc_params(720, 10);
params.init(GAUSS);
layers[0].Input(28, 28, 1);
layers[1].Convolution(24, 24, 5, params.conv_params[0]);
layers[2].Relu(24, 24, 5);
layers[3].Maxpool(12, 12, 5);
layers[4].Sigmoid(12, 12, 5);
layers[5].Affine(720, 10, params.fc_params[0]);
layers[6].Softmax(10);
cout << "Constructing ends\n";
}
void Simple_convnet::train_net()
{
cout << "***************************Training begins!**********************************\n";
for (int epoch = 1; epoch <= 100; epoch++)
{
double err = 0.0;
for (int i = 0; i < train_num; i++)
{
mnist.load_data(layers[0].y, labels, i, Mnist::train);
loss((int)labels.value());
err += m_loss;
update(SGD);
}
printf("epoch: %d loss:%.5f\n", epoch, 1.0 * err / train_num);//每次记录一遍数据集的平均误差
test_net();
}
}
void Simple_convnet::test_net()
{
int sum = 0;
int ans;
for (int i = 0; i < test_num; i++)
{
mnist.load_data(layers[0].y, labels, i, Mnist::test);
ans = predict();
//layers[6].y.show();
// cout << ans << '\t' << (int)labels.value() << '\n';
if (ans == (int)labels.value())
sum++;
}
printf(" precision: %.5f\n", 1.0 * sum / test_num);
}
主程序:
#include"simple_convnet.h"
int main()
{
Simple_convnet nn;
nn.train_net();
}
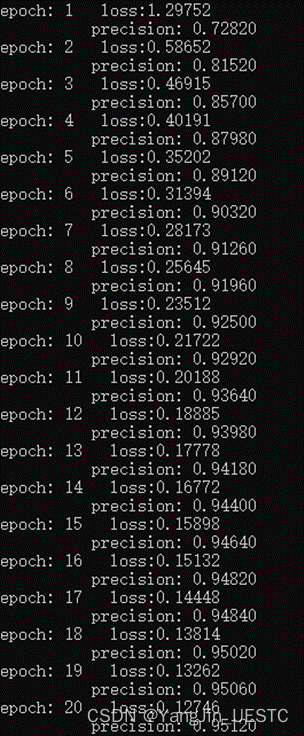
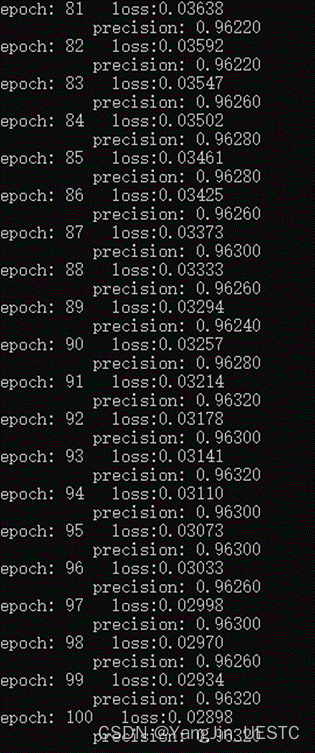
对网络权重参数使用高斯初始化方法,从MNSIT数据集的训练集中选择20000张对网络进行训练,从测试集中选择5000张进行测试,优化算法使用SGD,每次迭代数据批量设置为1,epoch=100,学习率设置为0.01。程序的部分输出如下图所示:
七、总结与展望
本文提出了一个能实现最基本卷积神经网络的深度学习框架,由于是最初版,还有许多地方亟待改进,但对初学者掌握卷积神经网络的内部原理颇有裨益。第一章部分介绍了该框架的基本数据结构:三维矩阵,其局限性很明显,便是只能存储浮点数和至多三维的数据。第二章是该框架的核心部分,对神经网络的基本组件如卷积层、全连接层等前向传播和反向传播做了数学推导并用程序对其进行了实现。第三~五章介绍了该框架中的通用函数类、权重参数类和网络基类,其主要是为了方便用户搭建神经网络,减少不必要的工作量。第六章是实验部分,主要介绍基于该框架实现简单的卷积神经网络并测试其在MNIST数据集上的性能。
未来将实现GPU版本的框架,并实现更加智能的基本数据结构,同时将基于该框架实现一些主流的神经网络模型,如GoogleNet,FCN、RNN等等。碍于该框架的局限性,目前基于该框架实现复杂神经网络尚有较大难度,同时基于该框架训练神经网络耗时太久,需要对本框架做大量修改才能方便用户快速地搭建复杂神经网络并在可接受的时间内训练网络至收敛。















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









