






转载出处:http://blog.csdn.net/eternity1118_。
在学习之前,先说一些题外话,由于博主学习模式识别没多久,所以可能对许多问题还没有深入的认识和正确的理解,如有不妥,还望海涵,另请各路前辈不吝赐教。
好啦,我们开始学习吧。。
同样假设有样本集:
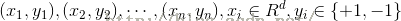
由于线性不可分,所以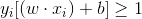
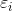
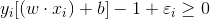
当样本出现错分时,则该样本对应的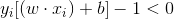
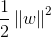
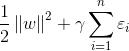
在上述目标函数中,我们的目的有两个:(1)使分类间隔尽可能大;(2)使错分程度尽可能小;gamma表示在上述两个目的之间的平衡参数,这个参数比较重要,值的选择很关键,值太大时,说明我们对样本错分的容忍小,值太小,说明对错分容忍稍大,而比较重视大间隔分类。
基于上面两个期望,同样使用拉格朗日乘法来求解:
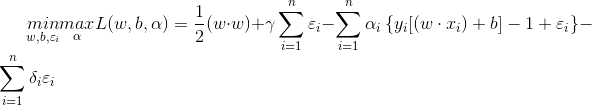
较可分情况而言,这是一个广义的最优分类面问题,具体求解方法同可分情况类似,这里不再赘述,详细过程请见http://blog.csdn.net/eternity1118_/article/details/51474693。
对上式泛函求导,得到下面的解:
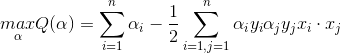
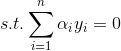
注意,这里的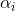
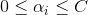
另外得到w的解:
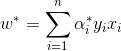
于是广义问题的判别函数为:
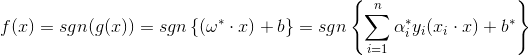
到这里,你会发现上面几个式子和线性可分下的完全一模一样,唯一的不同是
下面,来看一看这种情况下的支持向量都有哪些样本组成。
根据库恩-塔克条件,泛函的鞍点出满足以下式子:
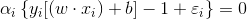
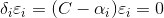
对右边式子来说,
对左边式子来说,与之前分析的一样,{}中的那一项等于0时,才有可能使得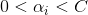
至此,可以发现,线性不可分的情况包含了可分的情况的,所以我们通常所说的SVM其实就是广义的最优分类面形式,即无需考虑样本可分不可分。















 6649
6649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









