







 在关系抽取任务中,SVM分类常遇到正负样本不均衡问题,导致分类器将所有测试样本分类为负例。解决办法是通过设置不同的惩罚因子,如在LibSVM中使用-C和-W选项。例如,对于1:9的正负样本比例,可以设置-w1 9 -w-1 1,使分类器倾向于识别更多正样本。此外,SVM中的松弛变量用于允许部分样本点不满足分类间隔,通过惩罚因子C平衡离群点的损失和分类间隔的增大,从而解决线性不可分问题。对于数据集偏斜问题,可以通过调整不同类别的惩罚因子来改善分类效果。
在关系抽取任务中,SVM分类常遇到正负样本不均衡问题,导致分类器将所有测试样本分类为负例。解决办法是通过设置不同的惩罚因子,如在LibSVM中使用-C和-W选项。例如,对于1:9的正负样本比例,可以设置-w1 9 -w-1 1,使分类器倾向于识别更多正样本。此外,SVM中的松弛变量用于允许部分样本点不满足分类间隔,通过惩罚因子C平衡离群点的损失和分类间隔的增大,从而解决线性不可分问题。对于数据集偏斜问题,可以通过调整不同类别的惩罚因子来改善分类效果。
1、问题描述
做关系抽取就是要从产品评论中抽取出描述产品特征项的target短语以及修饰该target的opinion短语,在opinion mining里面属于很重要的task,很多DM、NLP相关的paper在做这方面的工作。基本的思路是:
(1)从sentence的parse tree(比如stanford parser)中选取候选target结点和候选opinion结点,然后对所有的候选target和opinion组合选取features,用SVM进行训练分类。
(2)给定种子opinion words,借助parse tree中的path rules,多次迭代抽取新的target和opinion,称为Double Propagation (Qiu et al, IJCAI'09)
(3) 采用Tree kernel 的方法进行关系抽取(Wu et al, EMNLP'09)
如果采用第一种思路,在用SVM分类时就会遇到正负样例不均衡的问题。原因是,即便候选target和opinion抽取的recall和presicion可以达到100%,其不同的组合中也是负样例居多,正样例比例很少。我做实验时,遇到正负样例的比例为1:9,用SVM分类时,所有测试样例均被分类道来负样例中,这样的问题称为Unbalanced Data分类。
2、解决办法
对不同类别设置不同的惩罚因子。要用到LibSVM 的–C及-W选项。详细解释见《LIBSVM: A Library for Support Vector Machines》论文第6部分Unbalanced Data and Solving the Two-variable Sub-problem。C是惩罚因子,可以针对正负样本使用不同的惩罚值。 可以认为这个惩罚值 是指 对要训练的分类器 发生误判的惩罚程度。
比如:对于unbalanced的数据集,假设正样本+1占10%,负样本-1占90%, 正负样本比例为1:9. 按道理来说,我们训练svm分类器时,如果将+1样本误判为-1样本,我们需要加大惩罚力度。结合Libsvm FAQ中所说的例子,“svm-train -s 0 -c 10 -w1 1 -w-15 data_file 。 the penalty for class"-1" is larger. Note that this -w option is for C-SVC only”。
那么要解决关系抽取中unbalance data问题,命令应该是:svm-train -s 0 -c 10 -w1 9-w-1 1 data_file ,相当于采用C-SVC模式,对+1误判惩罚为10*9=90, 对-1误判为10*1=10,这样的设置会让分类器倾向分出更多的正样例来,这样分类结果就不再是全为-1了。并且,我们还可以进一步实验不同惩罚因子设置的情况下分类的准确率和召回率。
3、SVM中的松弛变量与惩罚因子
这一部分转自 http://blog.csdn.net/qll125596718/article/details/6910921,对松弛变量和惩罚因子的介绍非常通俗易懂。3.1 松弛变量
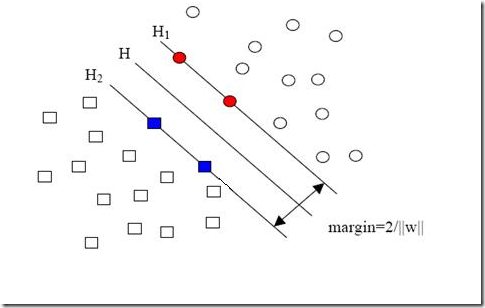
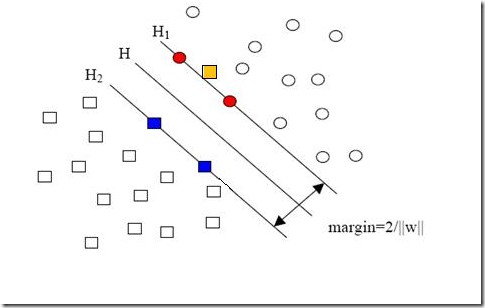
现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而变成了线性可分的。就像下图这样:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









