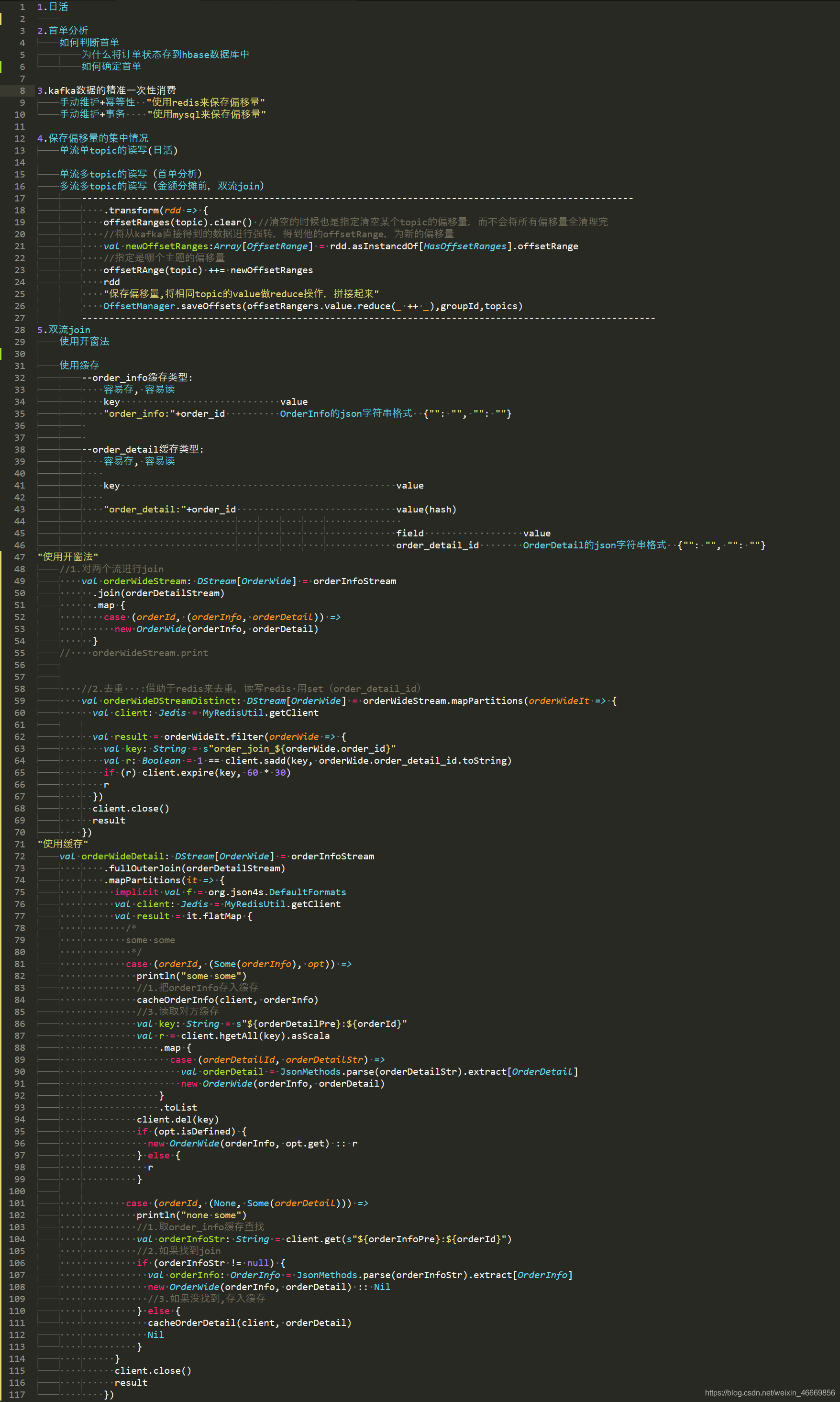
7 sparkStreaming实时数仓总结
1、SparkStreaming实时数仓用到的存储介质都干啥事了
--实时数仓中存储介质都干了些啥?
1. redis 64G
①存mid到set集合,重复的mid返回0则被过滤达到去重的目的(保留第一次启动数据)
②窗口法双流join的去重
③缓存法双流join缓存流数据
④手动保存偏移量(除了消费dws_order_wide主题)
2. hbase
①从ods层消费维度表(主题)写到hbase(维度表的dwd层,初始化维度表只做一次)
②user_status记录下了单的user_id
3. MySQL
①模拟的业务数据到MySQL
②热门品牌分析结果和手动保存偏移量(消费dws_order_wide),两者要求事务性
4. es 搜索引擎(全文检索)
①每个设备的首次启动日志数据写到es,分析日活和小时日活
②首单分析的结果写入es,每条数据标记是否首单is_first_order(dwd层),分析首单的订单数据
5. clickhouse
①存放双流join后的结果和商品分摊金额,包括销售额和小时销售额

2、SparkStreaming实时数仓要点
3 日志数据

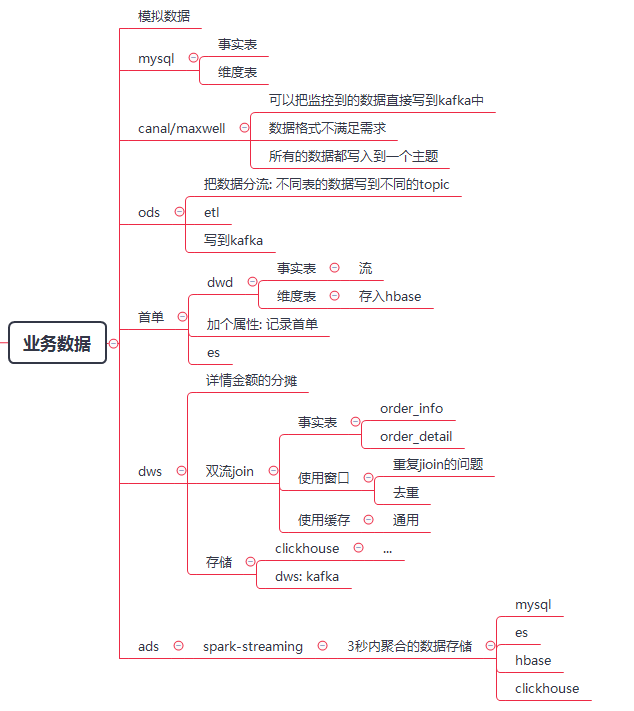
4 业务数据
























 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









