







Hadoop最新版本2.7.0的部署-学习记录01
Hadoop的部署方式有三种:本地模式、伪分布模式搭建、集群模式(现在一般使用HA的方式搭建,之后会将学习笔记上传到博客)
本文主要是伪分布式的搭建
- 1、Linux安装(EasyBCD的方式安装Ubuntu双系统,很方便)
- 2、VMWare安装(本文暂时不会使用到,但是为方便之后的HA的搭建,先进行安装)
- 3、Hadoop伪分布式环境配置
- 4、Hadoop环境测试
1、Linux安装(EasyBCD的方式安装Ubuntu双系统,很方便)
Linux系统与Window双系统安装可以参考百度经验,亲测完美双系统,相当好用,请按照百度经验中的内容操作:
http://jingyan.baidu.com/article/e4d08ffdace06e0fd2f60d39.html
2、VMWare安装(本文暂时不会使用到,但是为方便之后的HA的搭建,先进行安装)
PS:如果要学习大数据相关内容,建议工作学习全部在Linux下,而Ubuntu自然也是一个不二选择,所以之后伪分布的搭建将会本机Ubuntu系统下进行搭建,但是因为之后学习会到家HA集群模式,所以先安装VMware,之后搭建HA集群模式的时候方便使用。
VMware for Linux官方下载地址:
http://www.vmware.com/cn/products/workstation/workstation-evaluation下载成功后是一个.bundle后缀的文件,使用如下命令安装:
sudo ./VMware-Workstation-Full-12.1.0-3272444.x86_64.bundle执行安装,当然注册码可以自行百度
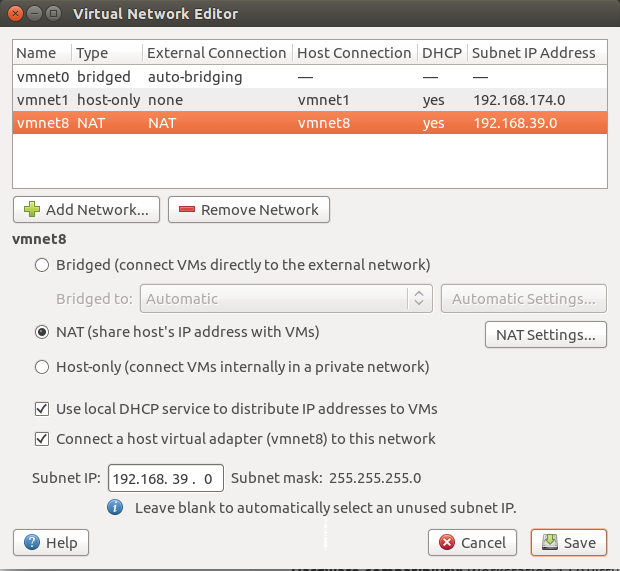
- 网络配置(VMware网络配置)
点击配置虚拟网络
Edit ==》Virtual Network Edit
3、Hadoop伪分布式环境配置
- 1、修改主机名称:
sudo vi /etc/hostname
- 2、设置Linux的机器IP地址(要根据自己的电脑实际情况操作,不要随意修改,修改前先备份,避免系统修改无法联网等问题)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
//修改文件中内容如下:
DEVICE="eth0" ###网卡硬件编号
BOOTPROTO="static" ###设置为静态网络
HWADDR="00:0C:29:3C:BF:E7" ###MAC地址
IPV6INIT="no" ###是否IPV6(建议为no避免出错)
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.39.100" ###与自己的电脑IP地址相匹配
NETMASK="255.255.255.0" ###
GATEWAY="192.168.39.2" ###网关保证和自己的IP地址在同一个网段下
- 3、修改主机名称和IP映射关系
sudo vi /etc/hosts
192.168.39.100 Ubuntu
- 4、关闭防火墙
- 查看防火墙状态
service iptables status- 关闭防火墙
service iptables stop- 查看防火墙开机启动状态
chkconfig iptables --list- 关闭防火墙开机启动
chkconfig iptables off- 重启系统
reboot
- 5、安装JDK
下载JDK7或者8均可;- 解压jdk
#创建文件夹
mkdir /usr/java
#解压
tar -zxvf jdk-7u79-linux-i586.tar.gz -C /usr/java/- 将java添加到环境变量中
vim /etc/profile
#在文件最后添加
JAVA_HOME=/usr/java/jdk1.7.0_79
- 6、修改Hadoop文件中的配置文件(以下是用的是hadoop2.7.0)
- 配置hadoop
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
第一个:hadoop-env.sh
vim hadoop-env.sh
> #第27行
> export JAVA_HOME=/usr/java/jdk1.7.0_79第二个:core-site.xml
<!--指定fs的默认名称-->
<property>
<name>fs.default.name</name>
<value>hdfs://ubuntu:9000</value>
</property>
<!-- 指定HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ubuntu:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/ubuntu/hadoop-2.7.0/tmp</value>
</property>第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>第五个:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ubuntu</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- 7、将hadoop添加到环境变量
vim /etc/profile
内容如下:
JAVA_HOME=/usr/java/jdk1.7.0_79
HADOOP_HOME=/ubuntu/hadoop-2.7.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin让配置生效:
source /etc/profile
4、Hadoop启动以及测试
1、格式化namenode(是对namenode进行初始化)
hdfs namenode -format 或者 hadoop namenode -format2、启动hadoop
- 先启动HDFS
sbin/start-dfs.sh
- 再启动YARN
sbin/start-yarn.sh
- 验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNodehttp://192.168.39.100:50070 (HDFS管理界面)
http://192.168.39.100:8088 (MR管理界面)
5、测试HDFS
- 查看帮助
hadoop fs -help <cmd>- 上传
hadoop fs -put <linux上文件> <hdfs上的路径>- 查看文件内容
hadoop fs -cat <hdfs上的路径>- 查看文件列表
hadoop fs -ls /- 下载文件
hadoop fs -get <hdfs上的路径> <linux上文件>- 上传文件到hdfs文件系统上
hadoop fs -put <linux上文件> <hdfs上的路径>
例如:hadoop fs -put /home/ubuntu/log.txt hdfs://Ubuntu:9000/- 删除hdfs系统文件
hadoop fs -rmr hdfs://ubuntu:9000/log.txt
注:如果能正常上传和删除文件说明HDFS没问题。- 测试Yarn
- 上传一个文件到HDFS
hadoop fs -put words.txt hdfs://ubuntu:9000/- 让Yarn来统计一下文件信息
cd /$HADOOP_HOME/etc/hadoop/share/hadoop/target/mapreduce/- 测试命令
hadoop jar hadoop-mapreduce-examples-2.7.0.jar wordcount /works.txt hdfs://ubuntu:9000/wc















 2828
2828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









