







文章目录

总体方案
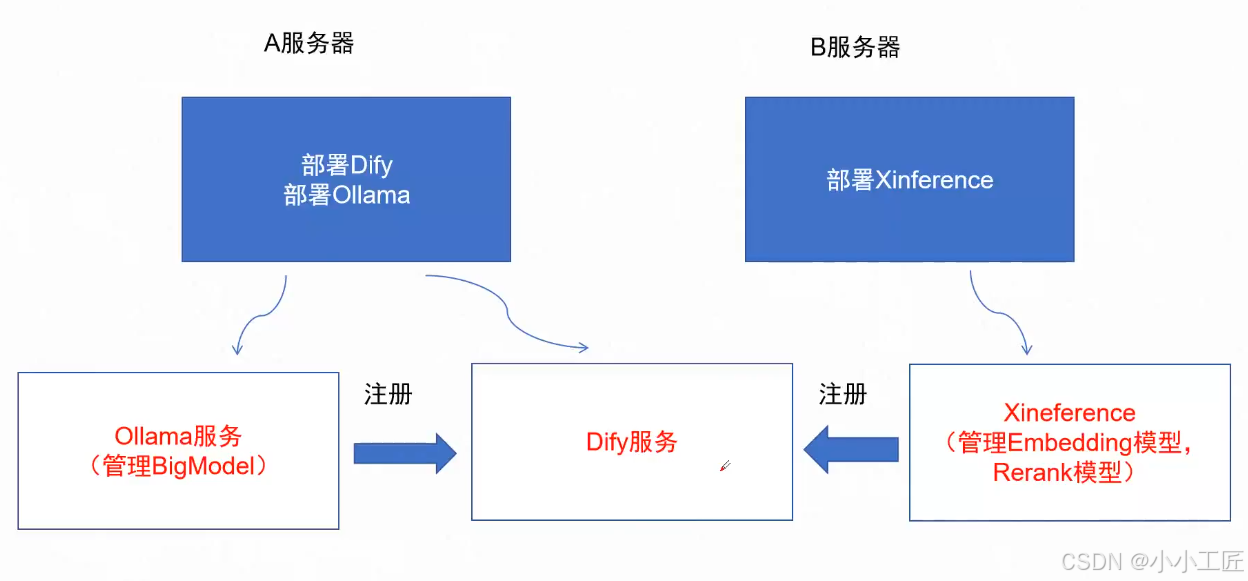
-
ollama 和 Xinference 管理模型,需要充分利用GPU, 故这里不选择使用Docker安装。
-
Dify 使用Docker安装
服务器
幕僚云按需租几台服务器

选择合适的镜像:机器学习框架镜像
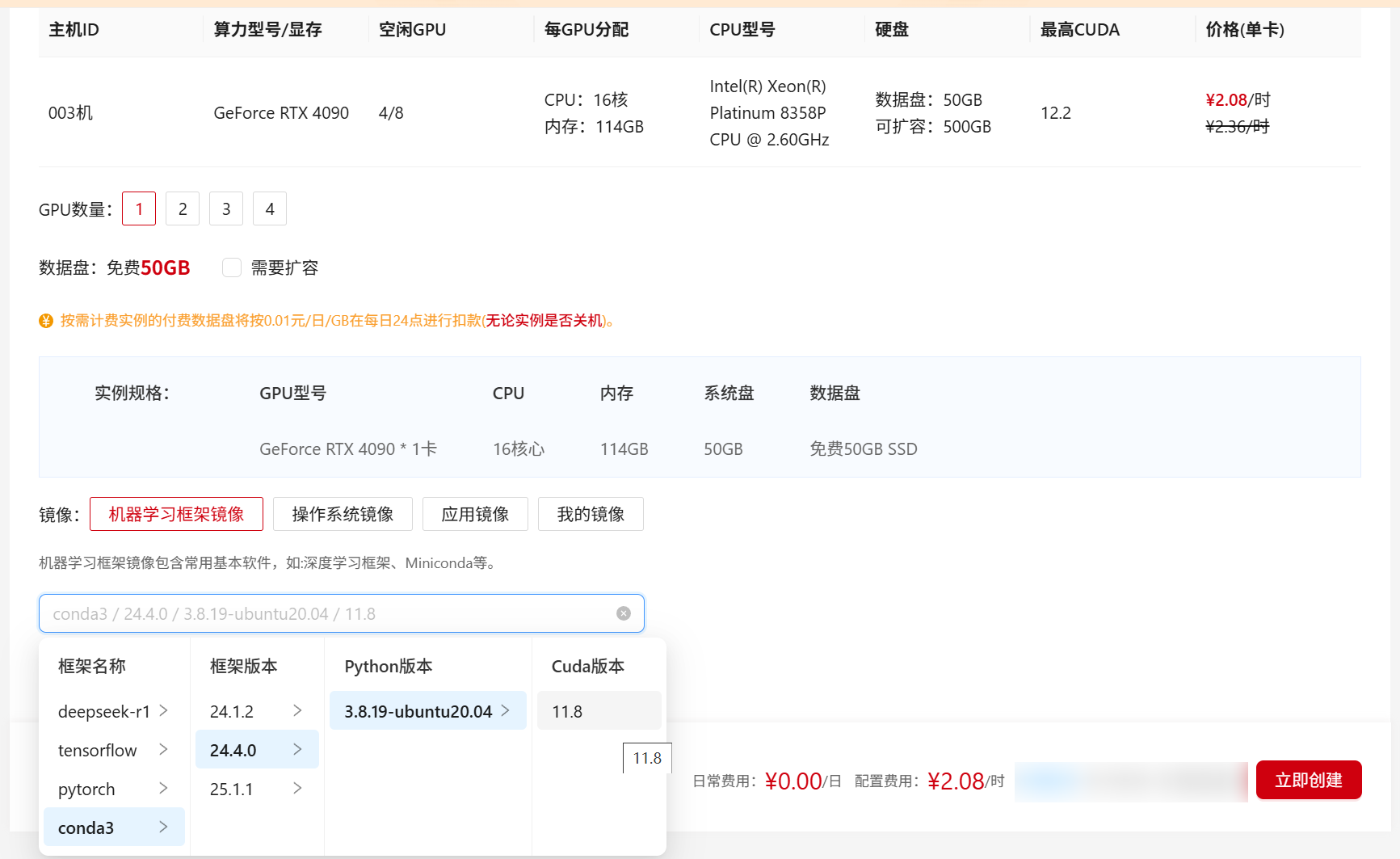
开启学术加速代理
目前机器学习框架镜像默认集成学术加速,需要手动开启学术加速代理
请在终端中使用以下命令开启学术加速。
source /etc/network_turbo
备注:如果network_turbo文件不存在,北京一区、北京二区、北京三区等使用此命令设置相关代理
export http_proxy=http://10.132.19.35:7890
export https_proxy=http://10.132.19.35:7890
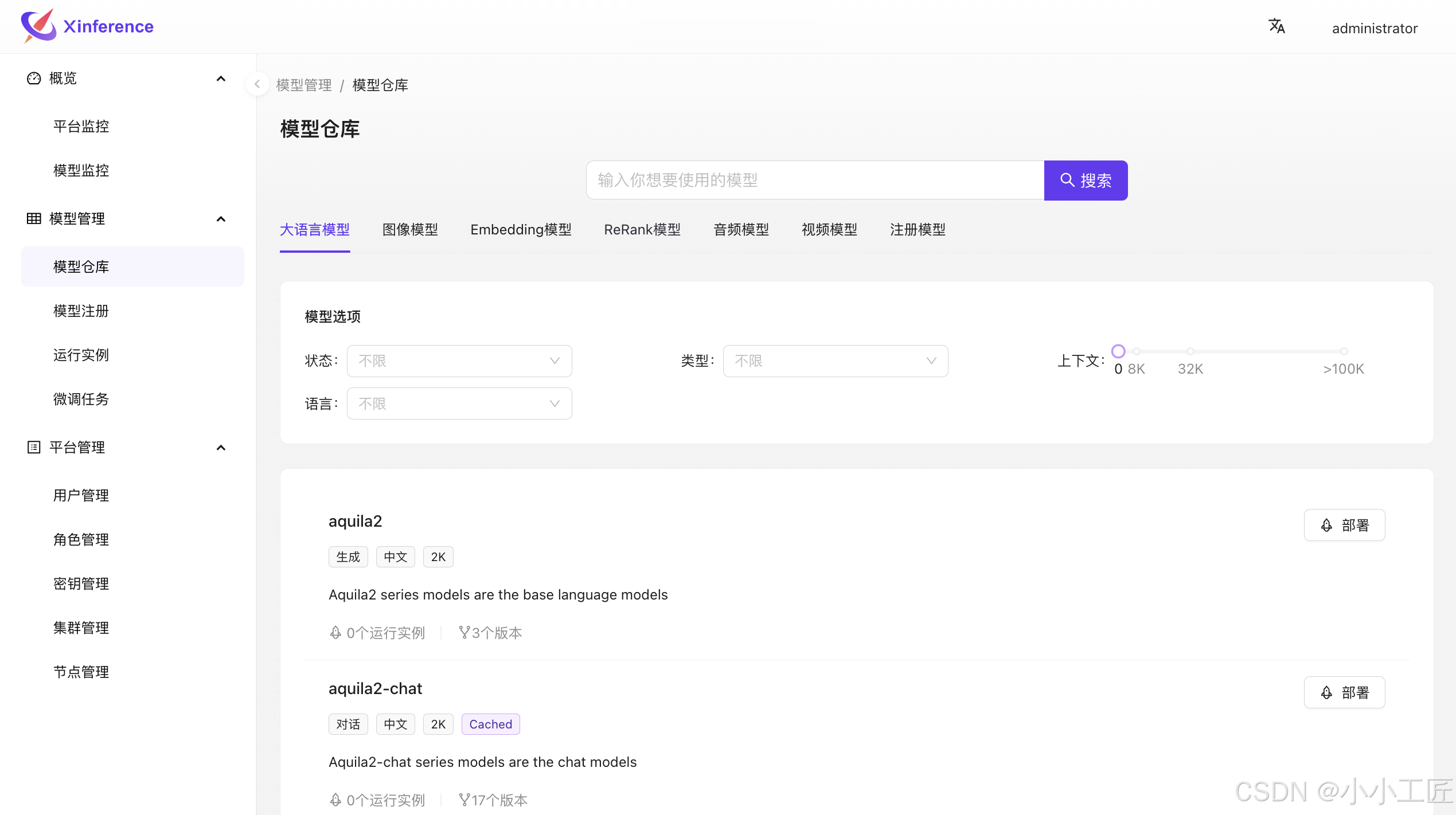
Xinference介绍

Xinference(Xorbits Inference)是一个功能全面且性能强大的分布式推理框架,专门用于各种AI模型的推理。无论是研究者、开发者还是数据科学家,都可以通过Xinference轻松部署自己的模型或内置的前沿开源模型。它支持多种形式的开源模型,并提供了WebGUI界面和API接口,极大地简化了模型部署和推理过程。
官网
https://github.com/xorbitsai/inference
框架增强
- Xllamacpp: 全新llama.cpp Python binding,由 Xinference 团队维护,支持持续并行且更生产可用: #2997
- 分布式推理:在多个 worker 上运行大尺寸模型:#2877
- VLLM 引擎增强: 跨副本共享KV Cache: #2732
- 支持 Transformers 引擎的持续批处理: #1724
- 支持针对苹果芯片优化的MLX后端: #1765
- 支持加载模型时指定 worker 和 GPU 索引: #1195
- 支持 SGLang 后端: #1161
- 支持LLM和图像模型的LoRA: #1080
新模型
- 内置 QwQ-32B: #3005
- 内置 DeepSeek V3 and R1: #2864
- 内置 InternVL2.5: #2776
- 内置 DeepSeek-R1-Distill-Llama: #2811
- 内置 DeepSeek-R1-Distill-Qwen: #2781
- 内置 Kokoro-82M: #2790
- 内置 qwen2.5-vl: #2788
- 内置 internlm3-instruct: #2789
- 内置 MeloTTS: #2760
集成
- FastGPT:一个基于 LLM 大模型的开源 AI 知识库构建平台。提供了开箱即用的数据处理、模型调用、RAG 检索、可视化 AI 工作流编排等能力,帮助您轻松实现复杂的问答场景。
- Dify: 一个涵盖了大型语言模型开发、部署、维护和优化的 LLMOps 平台。
- RAGFlow: 是一款基于深度文档理解构建的开源 RAG 引擎。
- MaxKB: MaxKB = Max Knowledge Base,是一款基于大语言模型和 RAG 的开源知识库问答系统,广泛应用于智能客服、企业内部知识库、学术研究与教育等场景。
- Chatbox: 一个支持前沿大语言模型的桌面客户端,支持 Windows,Mac,以及 Linux。
主要功能
🌟 模型推理,轻而易举:大语言模型,语音识别模型,多模态模型的部署流程被大大简化。一个命令即可完成模型的部署工作。
⚡️ 前沿模型,应有尽有:框架内置众多中英文的前沿大语言模型,包括 baichuan,chatglm2 等,一键即可体验!内置模型列表还在快速更新中!
🖥 异构硬件,快如闪电:通过 ggml,同时使用你的 GPU 与 CPU 进行推理,降低延迟,提高吞吐!
⚙️ 接口调用,灵活多样:提供多种使用模型的接口,包括 OpenAI 兼容的 RESTful API(包括 Function Calling),RPC,命令行,web UI 等等。方便模型的管理与交互。
🌐 集群计算,分布协同: 支持分布式部署,通过内置的资源调度器,让不同大小的模型按需调度到不同机器,充分使用集群资源。
🔌 开放生态,无缝对接: 与流行的三方库无缝对接,包括 LangChain,LlamaIndex,Dify,以及 Chatbox。
为什么选择 Xinference
| 功能特点 | Xinference | FastChat | OpenLLM | RayLLM |
|---|---|---|---|---|
| 兼容 OpenAI 的 RESTful API | ✅ | ✅ | ✅ | ✅ |
| vLLM 集成 | ✅ | ✅ | ✅ | ✅ |
| 更多推理引擎(GGML、TensorRT) | ✅ | ❌ | ✅ | ✅ |
| 更多平台支持(CPU、Metal) | ✅ | ✅ | ❌ | ❌ |
| 分布式集群部署 | ✅ | ❌ | ❌ | ✅ |
| 图像模型(文生图) | ✅ | ✅ | ❌ | ❌ |
| 文本嵌入模型 | ✅ | ❌ | ❌ | ❌ |
| 多模态模型 | ✅ | ❌ | ❌ | ❌ |
| 语音识别模型 | ✅ | ❌ | ❌ | ❌ |
| 更多 OpenAI 功能 (函数调用) | ✅ | ❌ | ❌ | ❌ |
ollama vs Xinference
| 特性 | Ollama | Xinference |
|---|---|---|
| 模型类型 | 主要专注于 LLMs,embedding | 支持多种模型类型 (LLMs, embedding, reranker,图像, 音频等) |
| 硬件支持 | CPU, GPU (NVIDIA, AMD, Apple Silicon) | CPU, GPU (NVIDIA, AMD, Intel, Apple Silicon) |
| 易用性 | 非常简单易用,一键安装,模型库丰富 | 相对复杂一些,但功能更强大,可定制性更高 |
| 扩展性 | 相对较弱,主要面向单机使用 | 更强,支持分布式部署,可扩展性更好 |
| API 兼容性 | 部分兼容 OpenAI API | 完全兼容 OpenAI API |
| 适用场景 | 快速体验本地 LLMs,轻量级应用 | 多样化模型需求,企业级应用,需要更高可定制性 |
- Ollama: 更注重 简单易用,适合快速上手本地 LLM 体验,模型库丰富,但模型类型和扩展性相对有限。
- Xinference: 更注重 强大和灵活,支持更多模型类型,更强的扩展性和可定制性,API 兼容性更好,适合更复杂的应用场景和企业级部署,但上手门槛稍高。
Xinference 安装
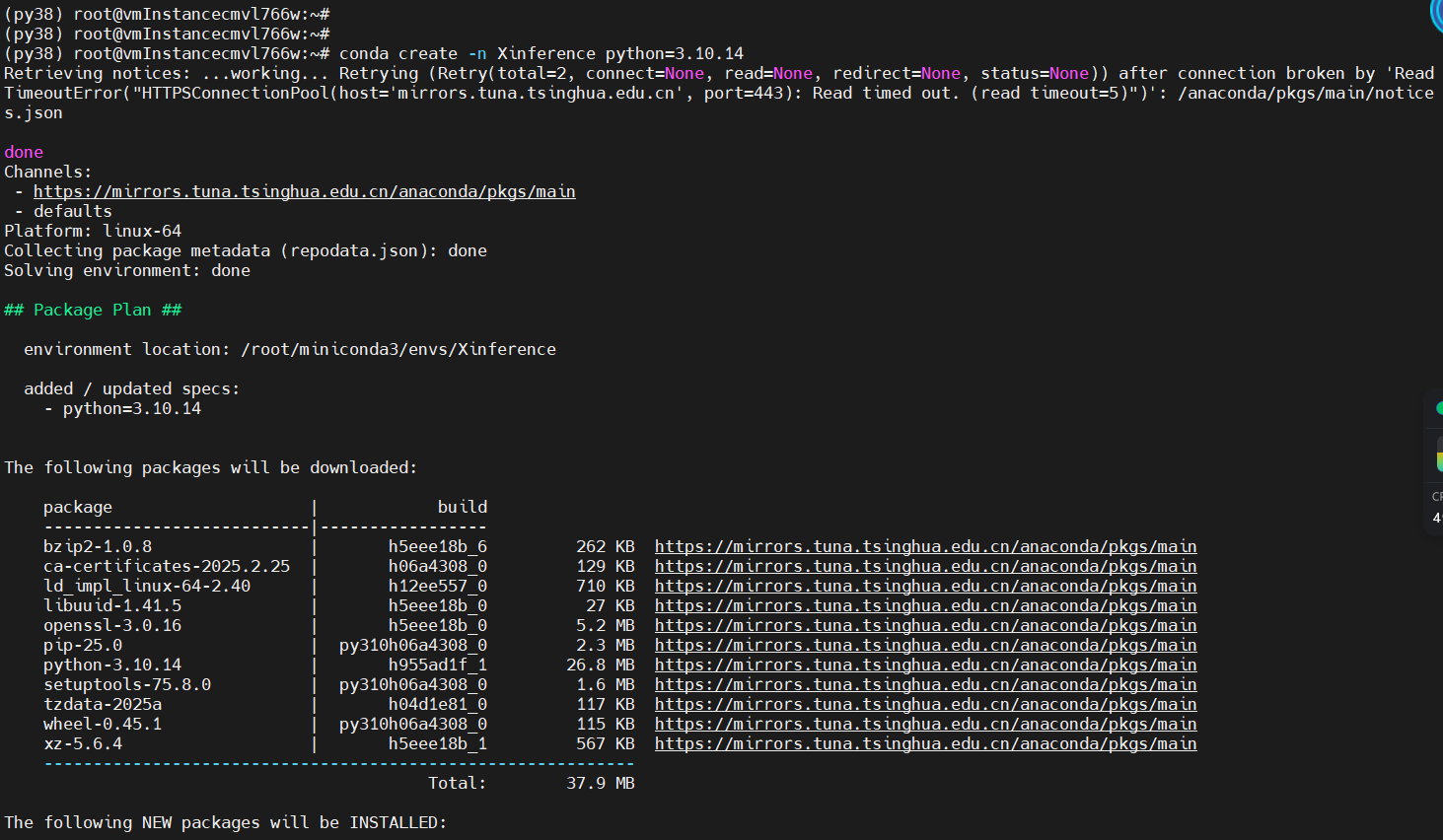
创建虚拟环境
创建一个环境
conda create -n Xinference python=3.10.14
激活环境
conda activate Xinference

配置清华源
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
使用清华源进行升级
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip

安装所有依赖
直接执行
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "xinference[all]"
等待片刻
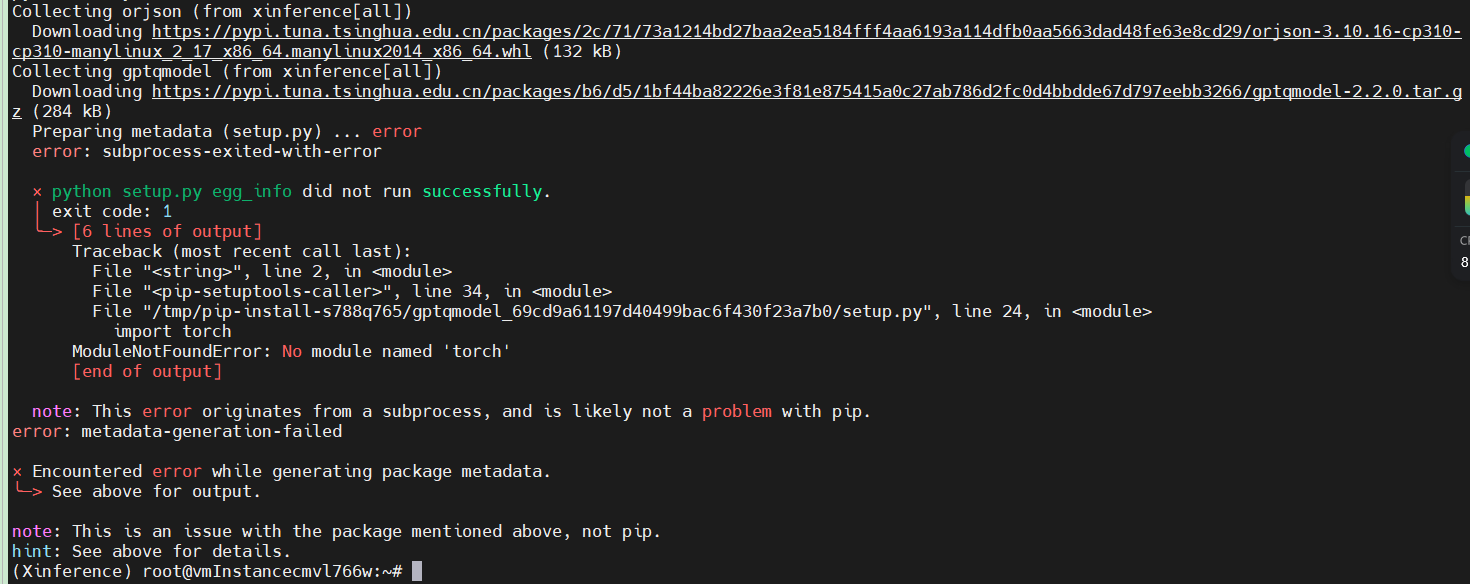
ModuleNotFoundError: No module named 'torch'看起来像 缺少了torch , 缺什么依赖就根据提示安装什么依赖即可
安装torch
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch
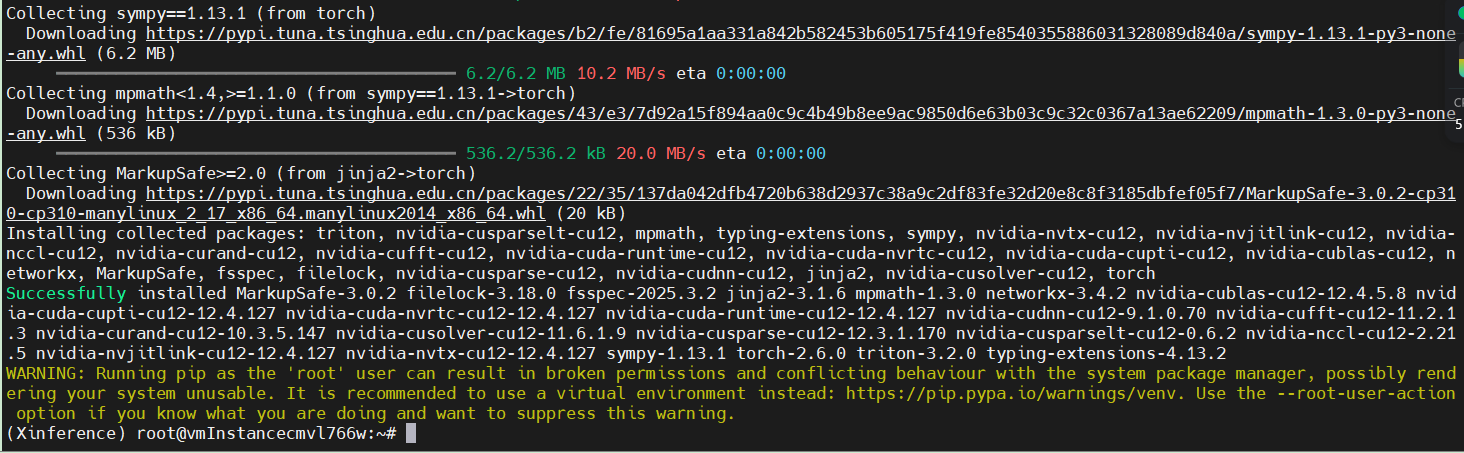
验证torch是否可以用
python -c "import torch; print(torch.cuda.is_available())"

缺少 numpy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
启动服务

nohup xinference-local --host 0.0.0.0 --port 8892 & > output.log
访问
http://ip:21995/ui/
FAQ
安装"xinference[all]"的时候出现什么Llama.cpp的包下载不下来的问题,这里你就别在折腾了,直接到官网下载whl文件,然后通过本地安装的方式就可以!
Llama.cpp地址: https://github.com/abetlen/llama-cpp-python/releases
版本有很多,看报错信息需要那个版本
cp310是python版本3.10别搞错了,这里安装的是这个:llama_cpp_python-0.2.88-cp310-cp310-linux_x86_64.whl
假设llama_cpp_python-0.2.88-cp310-cp310-linux_x86_64.whl在当前目录下
pip install llama_cpp_python-0.2.88-cp310-cp310-linux_x86_64.whl
报错:ERROR: Failed to build installable wheels for some pyproject.toml based projects (gptqmodel)
执行
wget https://github.com/ModelCloud/GPTQModel/releases/download/v2.2.0/gptqmodel-2.2.0+cu118torch2.1-cp310-cp310-linux_x86_64.whl
pip install gptqmodel-2.2.0+cu118torch2.1-cp310-cp310-linux_x86_64.whl



















 3277
3277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











