









CDH简介
1、Apache Hadoop 不足之处
• 版本管理混乱
• 部署过程繁琐、升级过程复杂
• 兼容性差
• 安全性低
2、Hadoop 发行版
• Apache Hadoop (原生版)
• Cloudera’s Distribution Including Apache Hadoop(CDH)国内用的比较多。
• Hortonworks Data Platform (HDP)
• MapR
• EMR
• …
--无论用哪个版本,对于开发人员来说,书写后端代码并不影响。
3、CDH能解决哪些问题
• 1000台服务器的集群,最少要花费多长时间来搭建好Hadoop集群,包括Hive、Hbase、Flume、Kafka、Spark等等
• 只给你一天时间,完成以上工作?
• 对于以上集群进行hadoop版本升级,你会选择什么升级方案,最少要花费多长时间?
• 新版本的Hadoop,与Hive、Hbase、Flume、Kafka、Spark等等兼容?
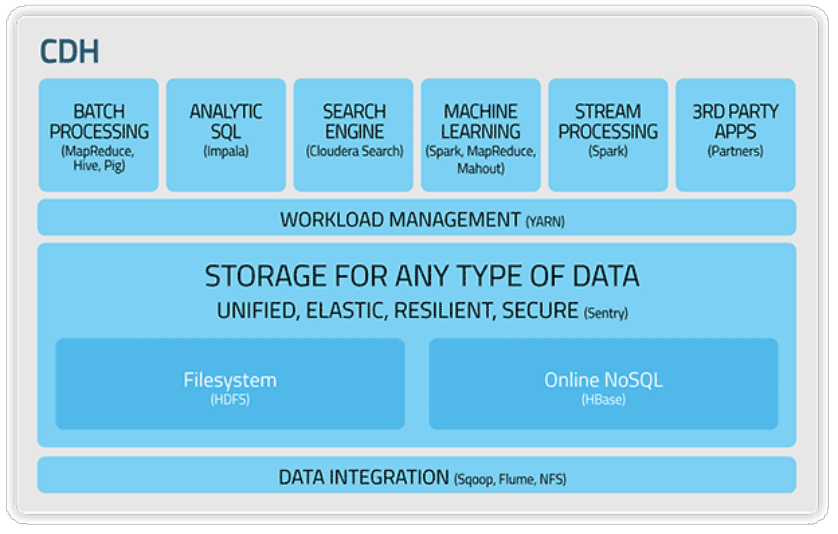
4、CDH简介
• Cloudera's Distribution, including Apache Hadoop
• 是Hadoop众多分支中的一种,由Cloudera维护,基于稳定版本的Apache Hadoop构建
• 提供了Hadoop的核心
– 可扩展存储
– 分布式计算
• 基于Web的用户界面
5、CDH的优点
• 版本划分清晰
• 版本更新速度快
• 支持Kerberos安全认证
• 文档清晰
• 支持多种安装方式(Cloudera Manager方式)
6、CDH安装方式
• Cloudera Manager
• Yum
• Rpm
• Tarball
7、CDH下载地址 https://www.bbsmax.com/A/B0zqV0w2Jv/
• CDH5.9
http://archive.cloudera.com/cdh5/
•Cloudera Manager5.9.0:
https://archive.cloudera.com/cm5/cm/5/
ClouderaManager简介
Cloudera Manager是一个管理CDH的端到端的应用。
作用:
--管理
--监控
--诊断
--集成
CDH架构
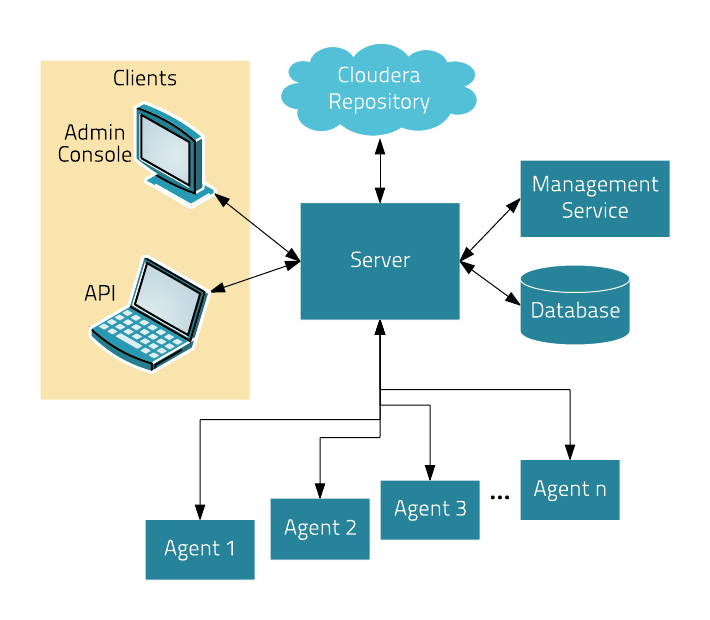
Server
管理控制台服务器和应用程序逻辑
负责软件安装、配置
启动和停止服务
管理服务运行的群集
Agent
安装在每台主机上
负责启动和停止进程,配置,监控主机
Management Service
由一组角色组成的服务,执行各种监视、报警和报告功能
Database
Cloudera Repository
Clients
Admin Console
API
ClouderaManager部署
--系统环境准备
--ClouderaManager安装
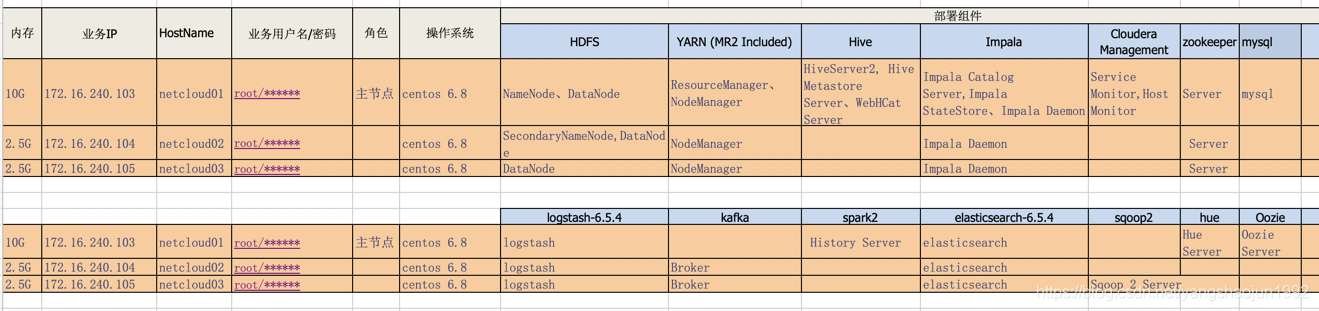
这里我们需要安装三个节点。分别为netcloud01、netcloud02、netcloud03。其中netcloud01为Server节点同时也是agent节点、安装mysql在此节点上。 netcloud02、netcloud03安装agent。
下面的系统环境配置除了mysql安装在netcloud01节点上,其他的所有配置都需要在节点上安装。
免登陆时需要两两设置。

一、系统环境准备
1、网络配置 (netcloud01、netcloud02、netcloud03)
vi /etc/sysconfig/network-scripts/ifcfg-eth0
vi /etc/sysconfig/network
vi /etc/hosts
2、SSH免密钥登录 (netcloud01、netcloud02、netcloud03)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id hotname
note:三个节点两两进行免秘钥。
3、防火墙关闭 (netcloud01、netcloud02、netcloud03)
service iptables stop (临时关闭)
chkconfig iptables off (永久关闭)
chkconfig --level 35 iptables off (永久关闭)
4、SELINUX关闭 (node01,node02,node03)
setenforce 0 :临时关闭
vi /etc/selinux/config (SELINUX=disabled) :永久关闭
查看防火墙状态: chkconfig iptables --list
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
5、安装JDK配置环境变量 (netcloud01、netcloud02、netcloud03)
jdk1.8.0_211版本
export JAVA_HOME=/opt/java
export PATH=.:$PATH:$JAVA_HOME/bin:$PATH
6、安装NTP(netcloud01、netcloud02、netcloud03)
yum -y install ntp
设置开机启动 chkconfig ntpd on
设置时间同步
ntpdate cn.pool.ntp.org
将系统时间和硬件时间同步
hwclock --systohc
主节点: netcloud01
vi /etc/ntp.conf
# Hosts on local network are less restricted.
restrict 172.16.240.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
#broadcast 192.168.1.255 autokey # broadcast server
#broadcastclient # broadcast client
#broadcast 224.0.1.1 autokey # multicast server
#multicastclient 224.0.1.1 # multicast client
#manycastserver 239.255.254.254 # manycast server
#manycastclient 239.255.254.254 autokey # manycast client
# Enable public key cryptography.
#crypto
includefile /etc/ntp/crypto/pw
# Key file containing the keys and key identifiers used when operating
# with symmetric key cryptography.
keys /etc/ntp/keys
# Specify the key identifiers which are trusted.
#trustedkey 4 8 42
# Specify the key identifier to use with the ntpdc utility.
#requestkey 8
# Specify the key identifier to use with the ntpq utility.
#controlkey 8
# Enable writing of statistics records.
#statistics clockstats cryptostats loopstats peerstats
netcloud02、netcloud03 节点
vi /etc/ntp.conf
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#broadcast 192.168.1.255 autokey # broadcast server
#broadcastclient # broadcast client
#broadcast 224.0.1.1 autokey # multicast server
#multicastclient 224.0.1.1 # multicast client
#manycastserver 239.255.254.254 # manycast server
#manycastclient 239.255.254.254 autokey # manycast client
# Enable public key cryptography.
#crypto
includefile /etc/ntp/crypto/pw
# Key file containing the keys and key identifiers used when operating
# with symmetric key cryptography.
keys /etc/ntp/keys
# Specify the key identifiers which are trusted.
#trustedkey 4 8 42
# Specify the key identifier to use with the ntpdc utility.
#requestkey 8
# Specify the key identifier to use with the ntpq utility.
#controlkey 8
# Enable writing of statistics records.
#statistics clockstats cryptostats loopstats peerstats
restrict 172.16.240.0 mask 255.255.255.0 nomodify notrap
server 172.16.240.100
Fudge 172.16.240.100 stratum 8
启动ntp服务
【命令】service ntpd start
查看ntpd进程的状态
【命令】watch "ntpq -p"
7、安装配置mysql(netcloud01)
1) 检查MySQL及相关rpm包,是否安装,如有安装,则移除(RPM -e 名称)
rpm -qa | grep mysql
rpm -qa | grep mariadb
rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64
yum -y remove mysql-libs*

2) 删除mysql相关包:
rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64
rpm -e --nodeps qt-mysql-4.6.2-28.el6_5.x86_64
3) 下载并解压缩MySQL包
tar -xvf mysql-5.7.17-1.el6.x86_64.rpm-bundle.tar
安装MySQL,必需安装common,libs,client,server,libs-compat
rpm -ivh mysql-community-common-5.7.17-1.el6.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.17-1.el6.x86_64.rpm
rpm -ivh mysql-community-client-5.7.17-1.el6.x86_64.rpm
rpm -ivh mysql-community-server-5.7.17-1.el6.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.17-1.el6.x86_64.rpm
Note:
可能出现缺少依赖包如下,按照报错选择安装依赖包。
libc.so.6(GLIBC_2.14)(64bit) is needed by XXX
解决依赖包冲突
yum install libaio
yum install perl
yum install numactl
把mysql的jdbc驱动在所有节点的/usr/share/java下放置,名称mysql-connector-java.jar
mv mysql-connector-java.jar /usr/share/java
把orcale的jdbc驱动在所有节点的/usr/share/java下放置,名称orcale-connector-java.jar
4) 修改配置文件
配置文件位置
vi /etc/my.cnf
修改配置文件中标红的位置
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir = /sunmnet/mysql/data
port = 3306
socket = /sunmnet/mysql/data/mysql.sock
explicit_defaults_for_timestamp=true
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/sunmnet/mysql/logs/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[client]
socket=/sunmnet/mysql/data/mysql.sock
5) 建立MySQL目录
mkdir -p /sunmnet/mysql/
mkdir -p /sunmnet/mysql/data/
mkdir -p /sunmnet/mysql/logs/
chown -R mysql:mysql /sunmnet/mysql/
5.7以上用这个
mysqld --initialize --user=mysql --datadir=/sunmnet/mysql/data/
6)启动方式
service mysqld start
或
/etc/init.d/mysqld start
7)初始化MySQL及设置密码
#查看root账号密码 直接执行:
$ cat /sunmnet/mysql/logs/mysqld.log |grep password

mysql -uroot -p
mysql> SET PASSWORD = PASSWORD('Sunmnet@123');
增加权限:
mysql -uroot -pSunmnet@123
grant all on *.* to 'root'@'%' identified by 'Sunmnet@123';
flush privileges;
修改原有权限:
use mysql;
update user set host='%' where user='root' and host='localhost';
flush privileges;
select host,user,authentication_string from user;
exit
8)设置开机自动启动
chkconfig --list | grep mysqld
chkconfig mysqld on
chkconfig --list | grep mysqld
mysql5.6 版本安装 : https://blog.csdn.net/yangshaojun1992/article/details/103780980
8、下载第三方依赖包(netcloud01、netcloud02、netcloud03) 搭建ClouderaManager必须安装的依赖
yum install chkconfig python bind-utils psmisc libxslt zlib sqlite cyrus-sasl-plain cyrus-sasl-gssapi fuse fuse-libs redhat-lsb -y
二、ClouderaManager安装
1、安装Cloudera Manager Server、Agent(netcloud01、netcloud02、netcloud03)
mkdir /opt/cloudera-manager
tar xvzf cloudera-manager-el6-cm5.9.0_x86_64.tar.gz -C /opt/cloudera-manager
2、创建用户cloudera-scm【资源用户和权限】(netcloud01、netcloud02、netcloud03每台节点都要创建)相当于clouderaManager管理员
执行命令: useradd --system --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
详解:system 系统管理 no-create-home 没有家目录 --shell=/bin/false 禁止用户登陆 也就是进程用户
3、配置CM Agent (netcloud01、netcloud02、netcloud03)
修改文件/opt/cloudera-manager/cm-5.9.0/etc/cloudera-scm-agent/config.ini中server_host
# Hostname of the CM server.
server_host=netcloud01
在这里三个节点的server_host的值都是netcloud01
4、配置CM Server数据库(server节点 netcloud01)
拷贝文件mysql-connector-java-5.1.30-bin.jar到目录 /usr/share/java/
注意jar包名称要修改为mysql-connector-java.jar
登录mysql mysql -u root -p 输入密码后,然后执行下面的命令:
use mysql;
grant all on *.* to 'temp'@'%' identified by 'temp' with grant option;
cd /opt/cloudera-manager/cm-5.9.0/share/cmf/schema/
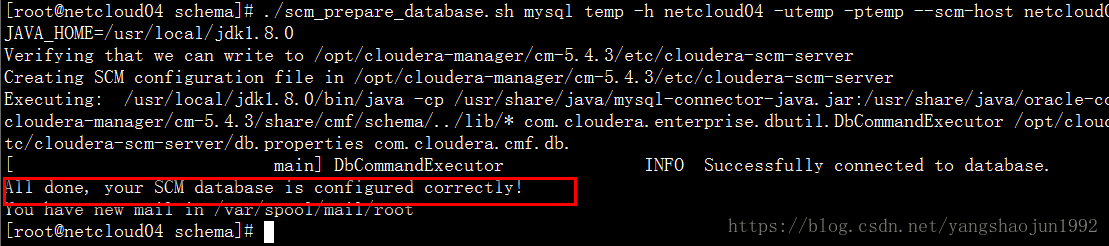
./scm_prepare_database.sh mysql temp -h netcloud01 -utemp -ptemp --scm-host netcloud01 scm scm scm
格式:数据库类型、数据库、数据库服务器、用户名、密码、cm server服务器
5、创建Parcel目录
Server节点(netcloud01)
mkdir -p /opt/cloudera/parcel-repo
chown cloudera-scm:cloudera-scm /opt/cloudera/parcel-repo
Agent节点(netcloud01、netcloud02、netcloud03)
mkdir -p /opt/cloudera/parcels
chown cloudera-scm:cloudera-scm /opt/cloudera/parcels
6、制作CDH本地源(netcloud01 server节点)
下载好文件CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel以及manifest.json,将这两个文件放到server节点的/opt/cloudera/parcel-repo下。
打开manifest.json文件,里面是json格式的配置,找到与下载版本相对应的hash码,新建文件,文件名与你的parel包名一致,并加上.sha后缀,将hash码复制到文件中保存。然后将此文件一同放在/opt/cloudera/parcel-repo下。
7、启动CM Server、Agent
cd /opt/cloudera-manager/cm-5.9.0/etc/init.d/
./cloudera-scm-server start (netcloud01上执行)
注:当/opt/cloudera-manager/cm-5.9.0/log/cloudera-scm-server中的日志全部输出完后server才算真正的启动。
Sever首次启动会自动创建表以及数据,不要立即关闭或重启,否则需要删除所有表及数据重新安装
./cloudera-scm-agent start (netcloud01、netcloud02、netcloud03 3台节点都有启动)

访问:http://ManagerHost:7180,
用户名、密码:admin
若可以访问,则CM安装成功。

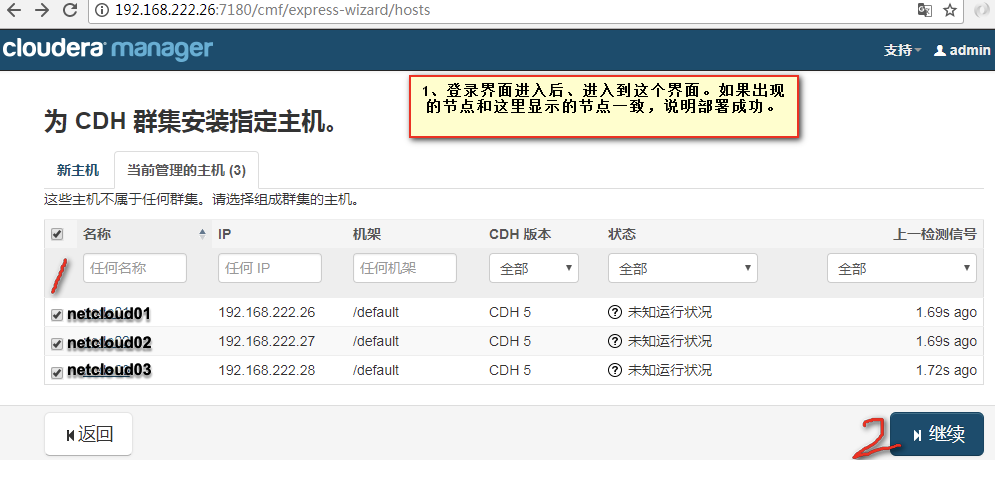
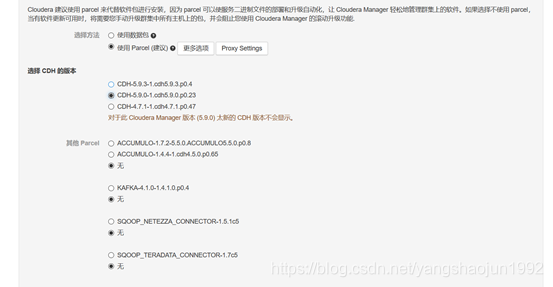
在这里我们选择 免费的版本>>点击继续>>为CDH群集安装指定的主机(两个页签分别为新主机、当前管理的主机(安装的节点选中))>>继续>>群集安装选择CDH版本(选择我们自己本地安装的CDH版本;其余的两个版本是外网版本)
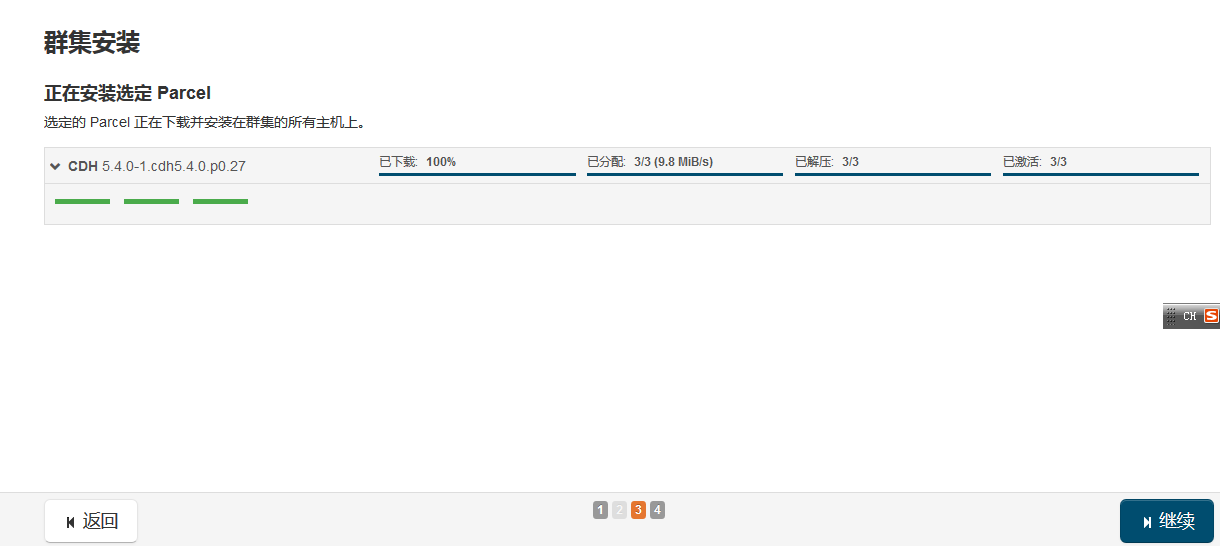
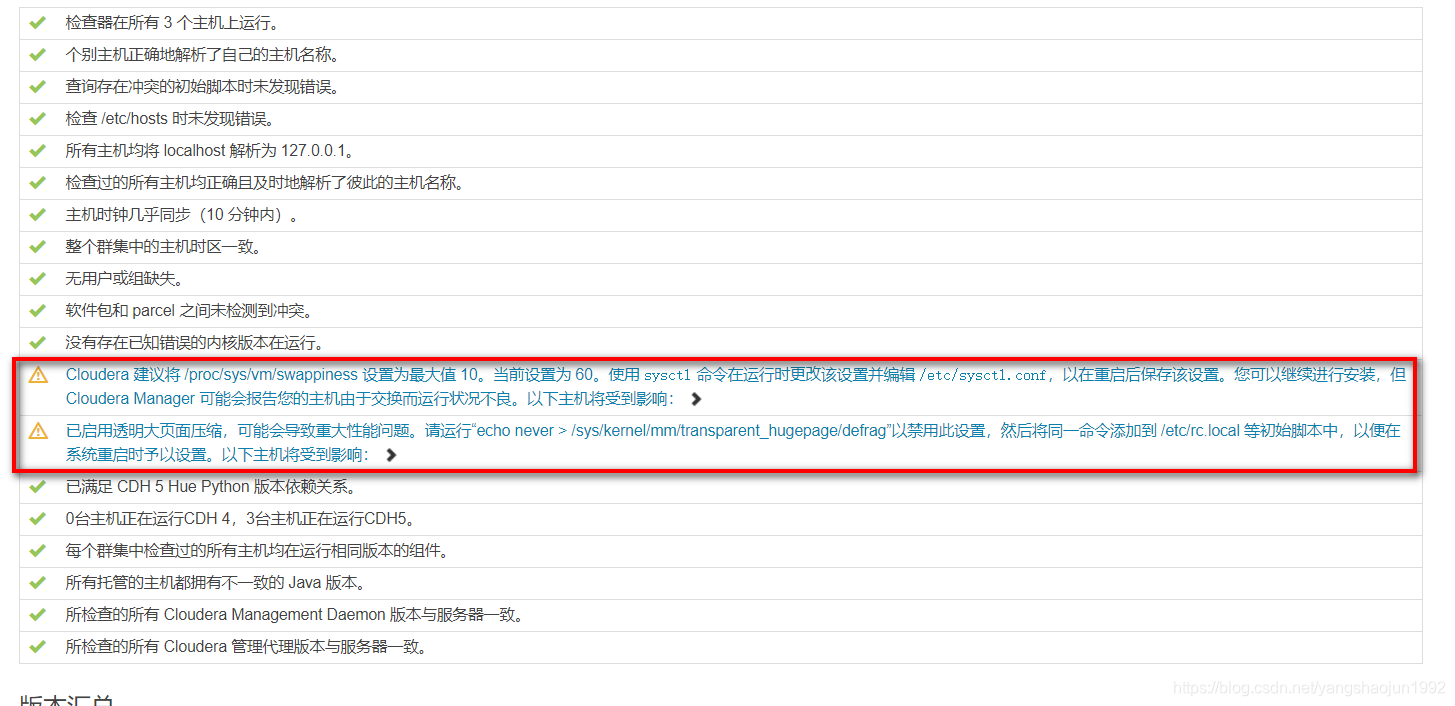
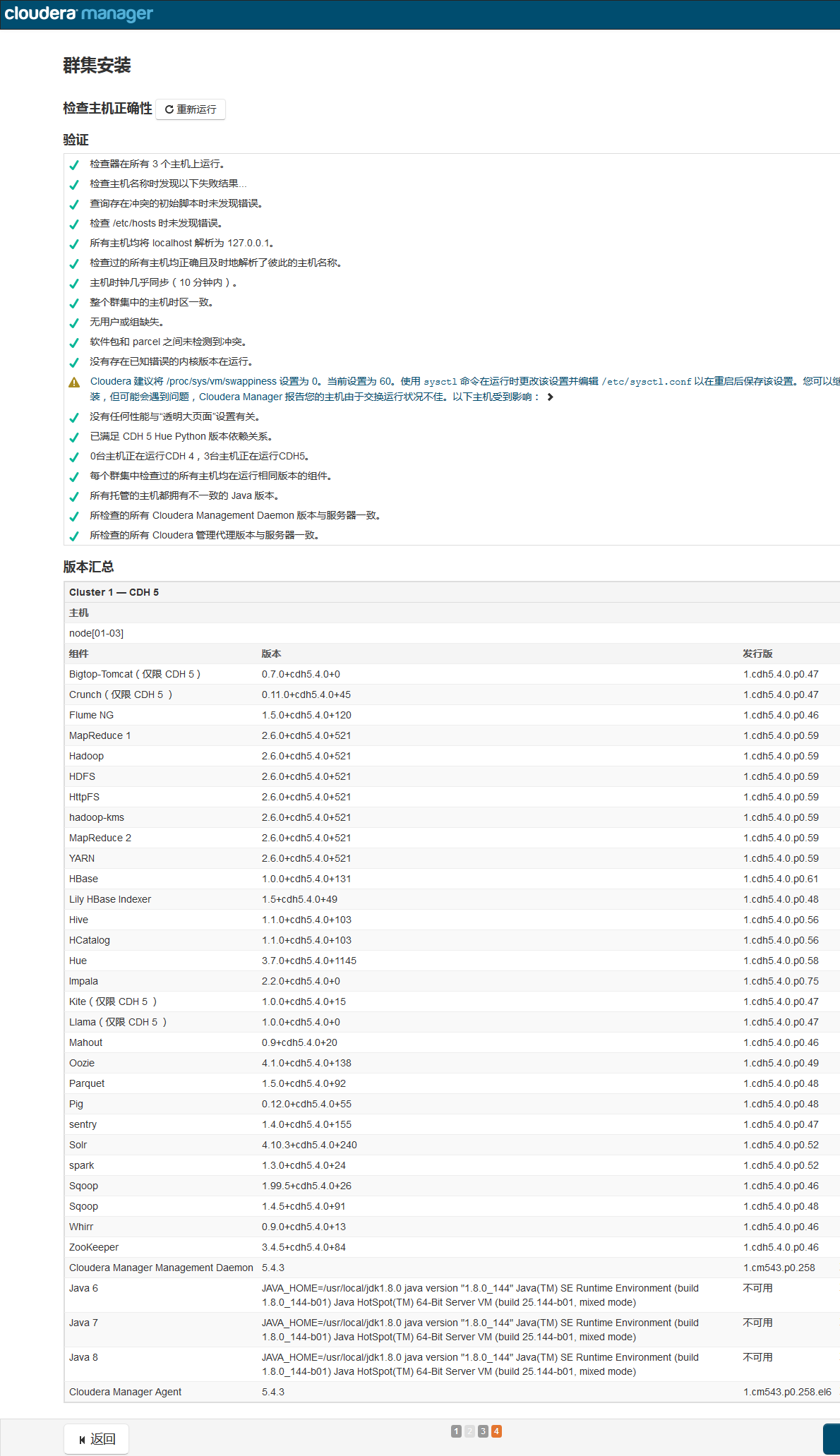
这里验证如果出现问题,会有相应的原因和解决方案。如(全部节点执行)
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.local
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo 'echo never > echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
sysctl -w vm.swappiness=0
echo "vm.swappiness = 0" >> /etc/sysctl.conf
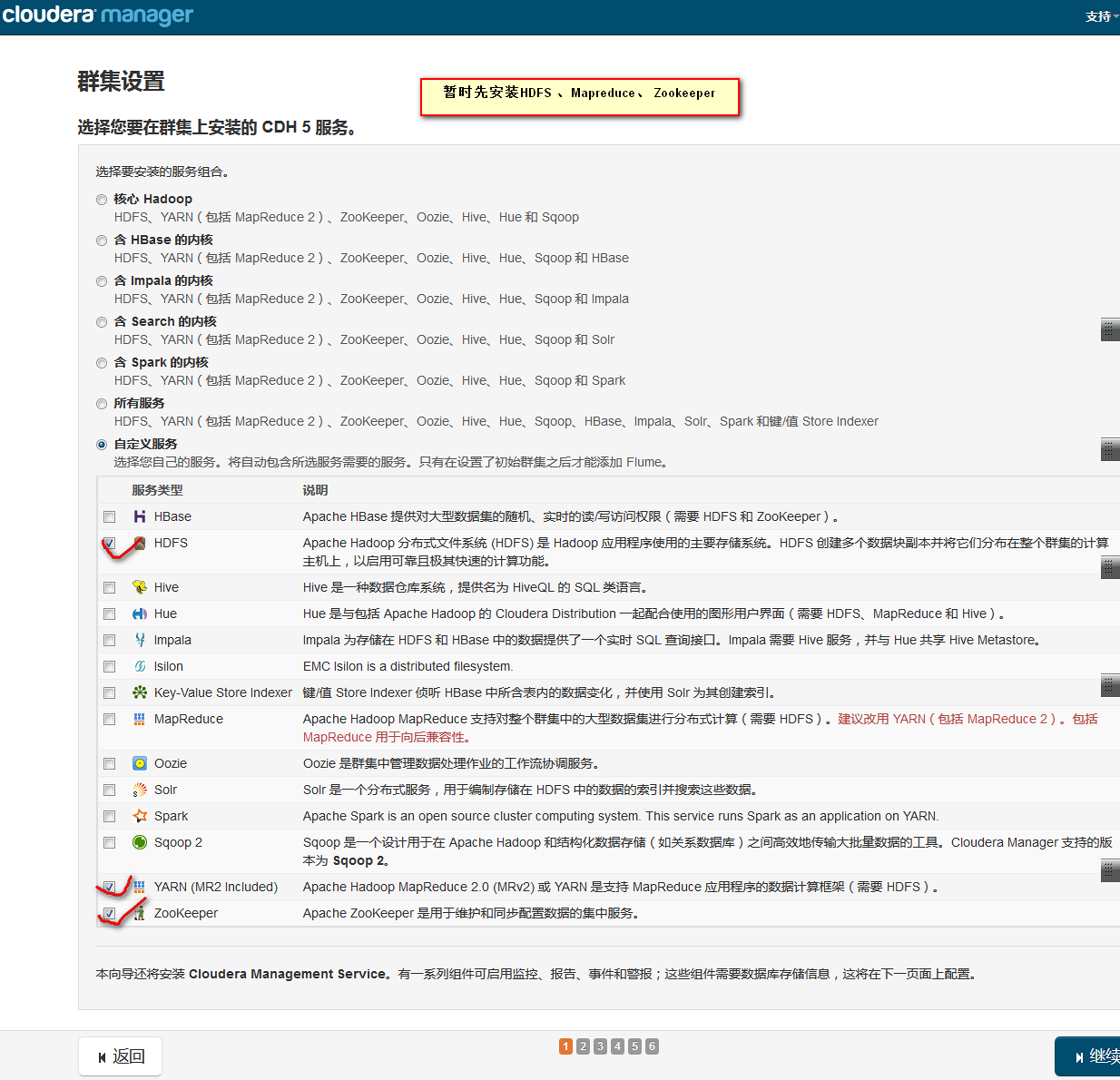
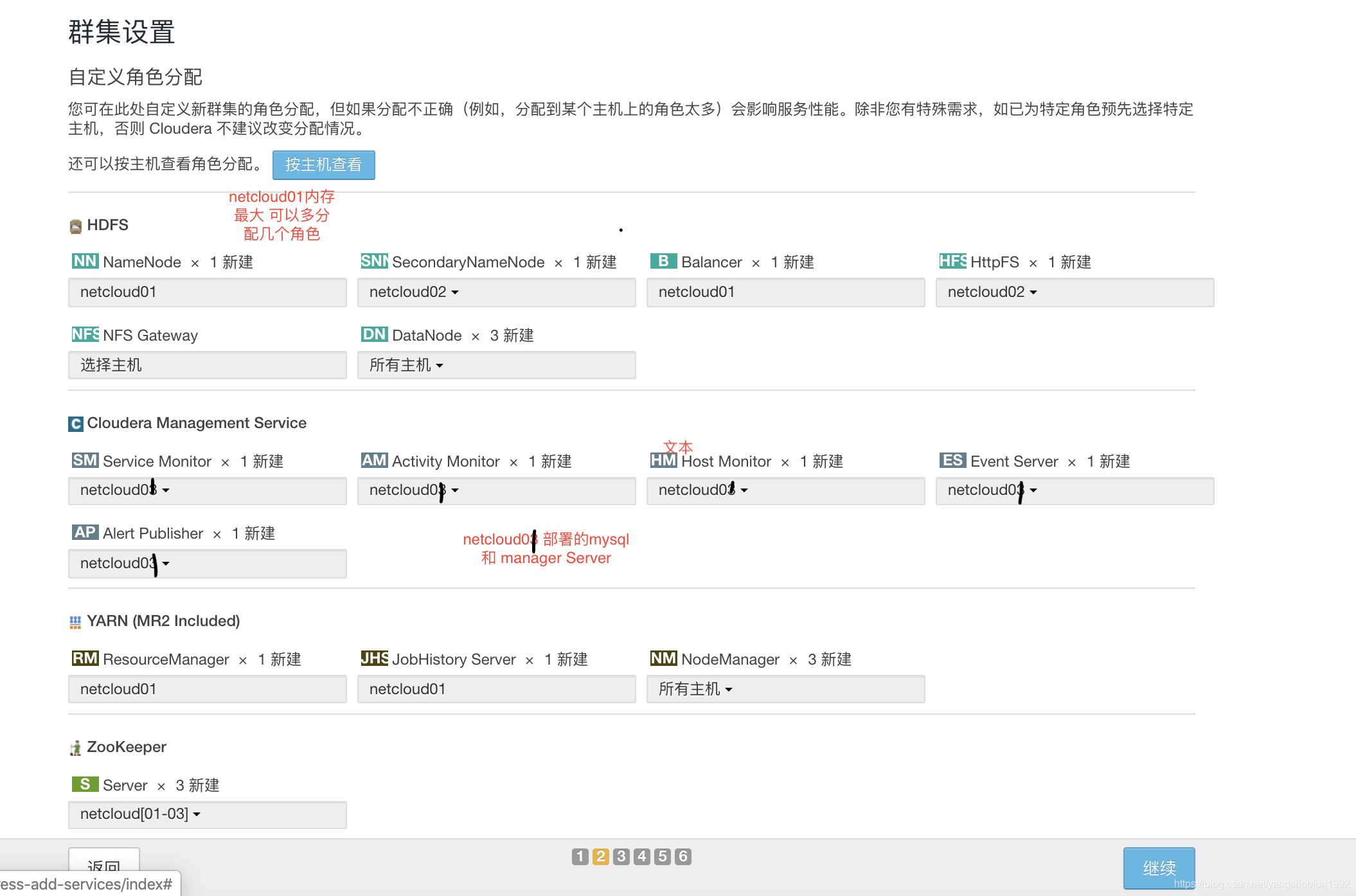
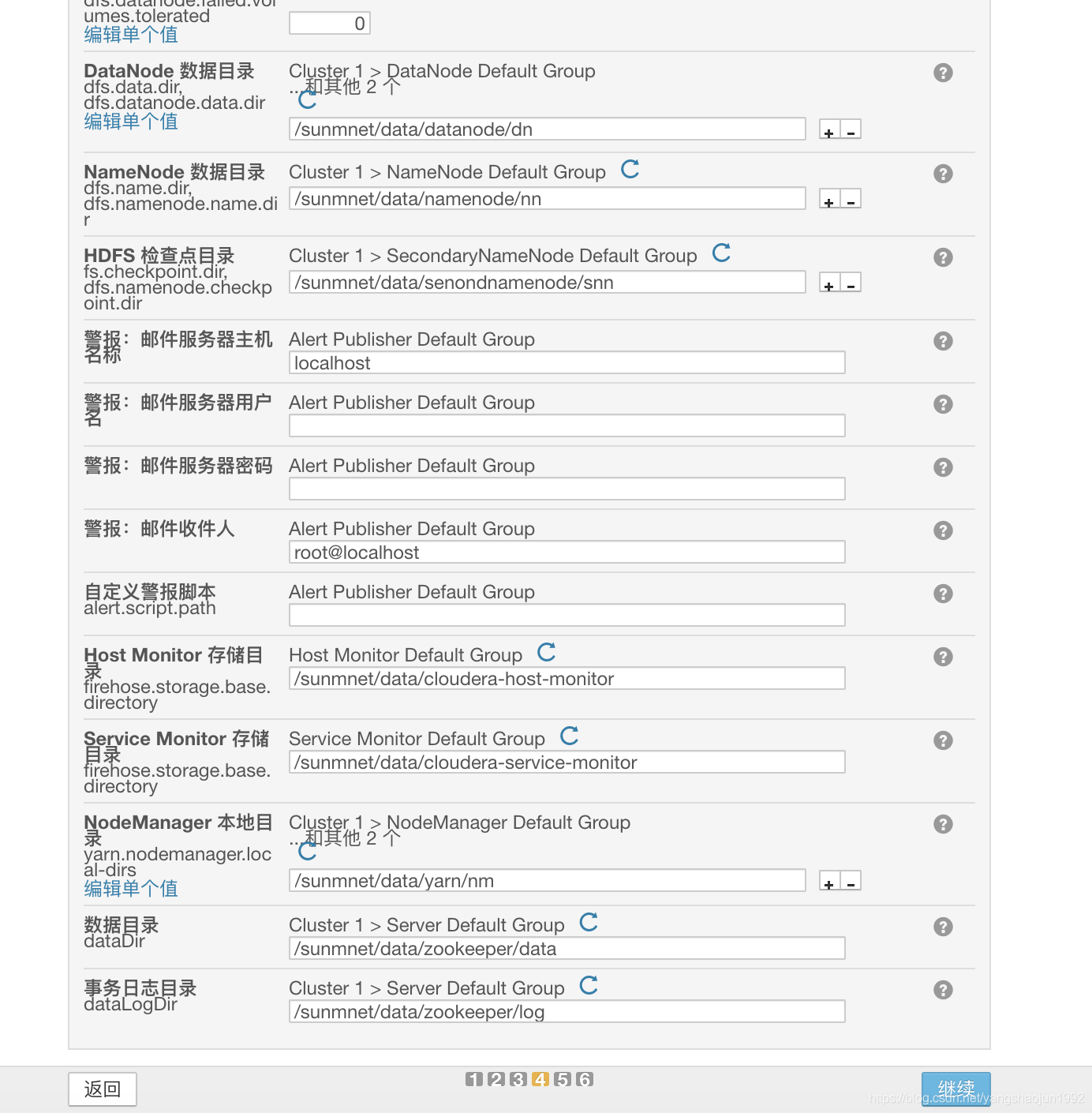
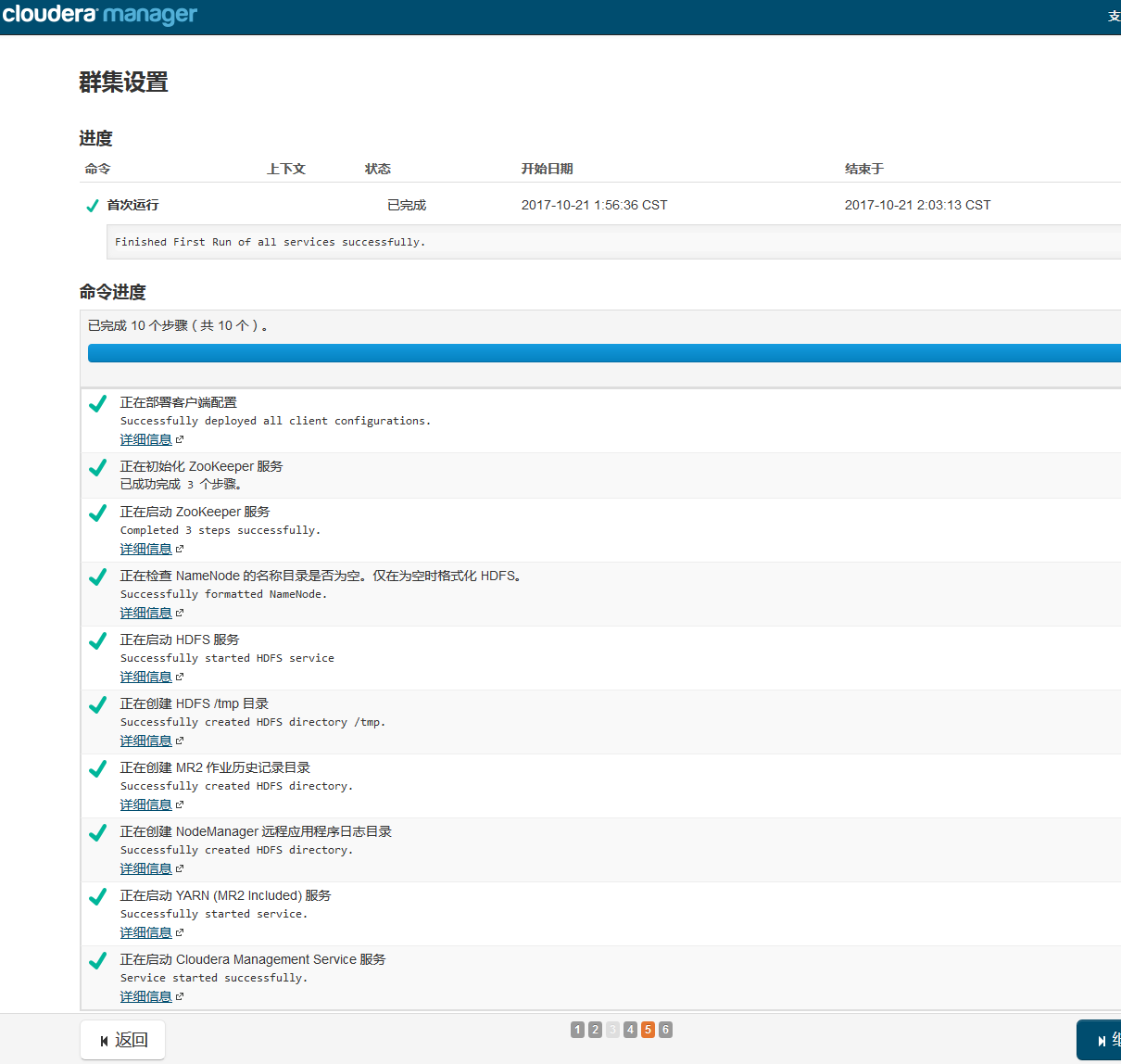
集群设置
step10:
添加服务
hive、impala服务
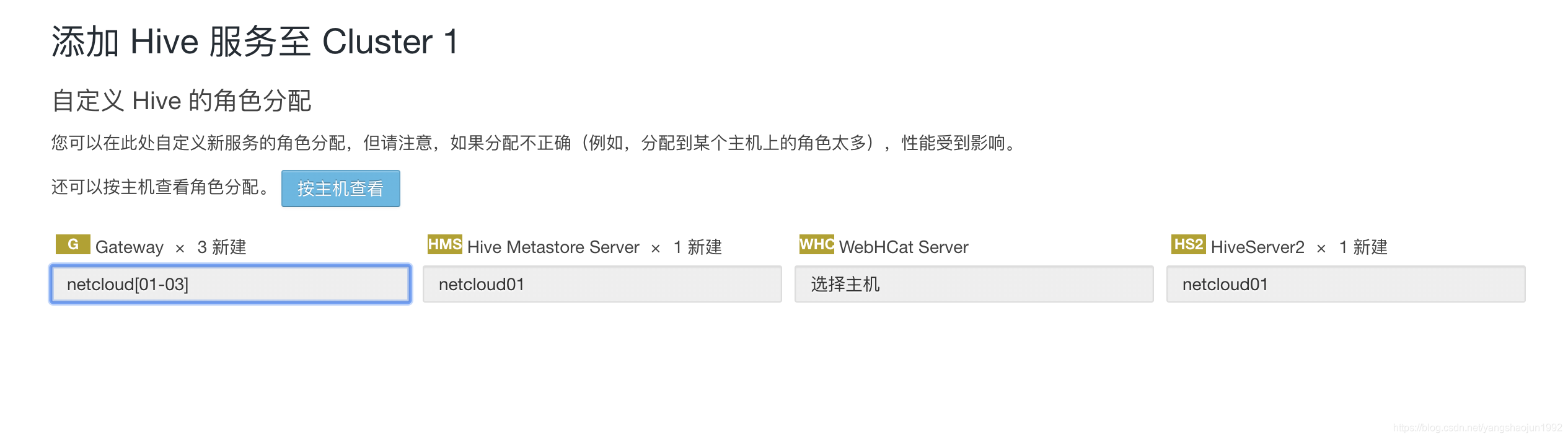
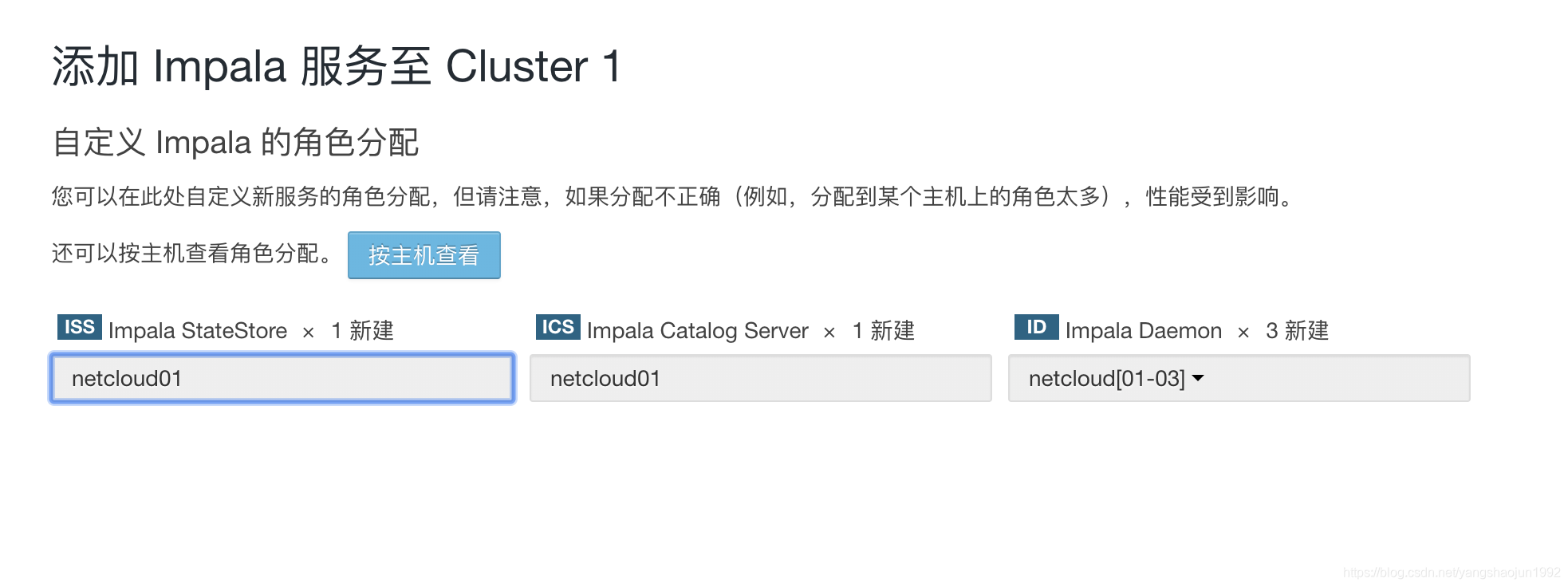
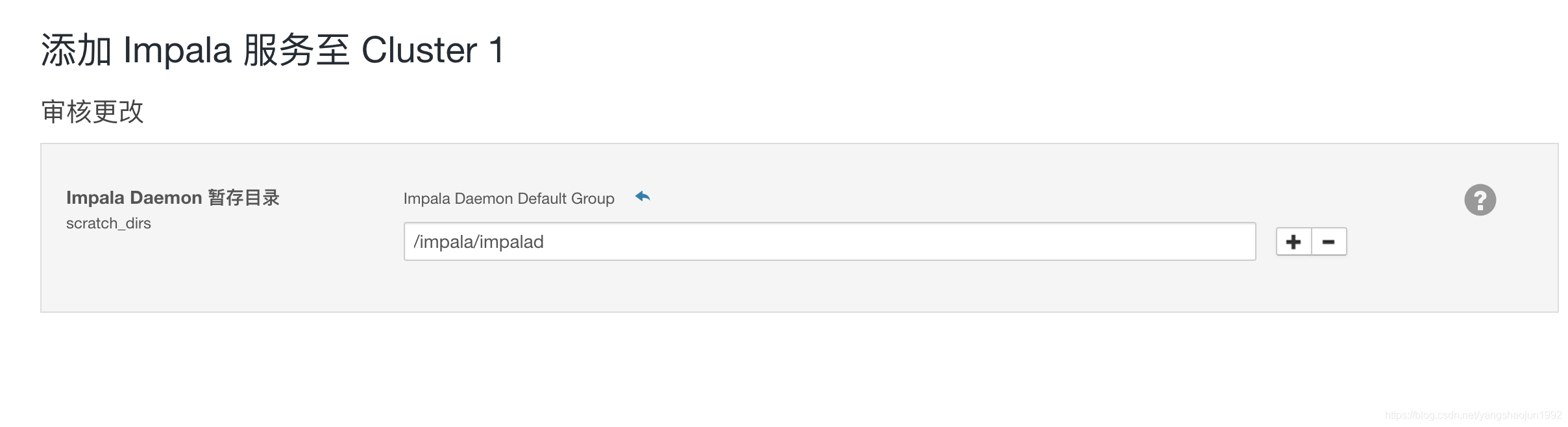
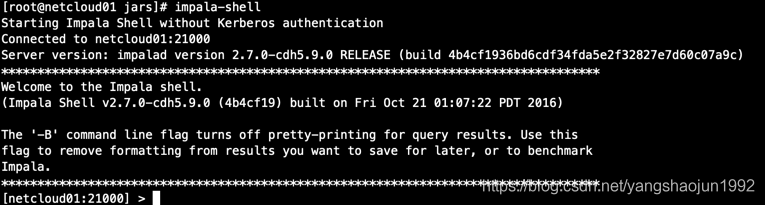
启动hive和impala
使用 impala-shell命令进入 impala
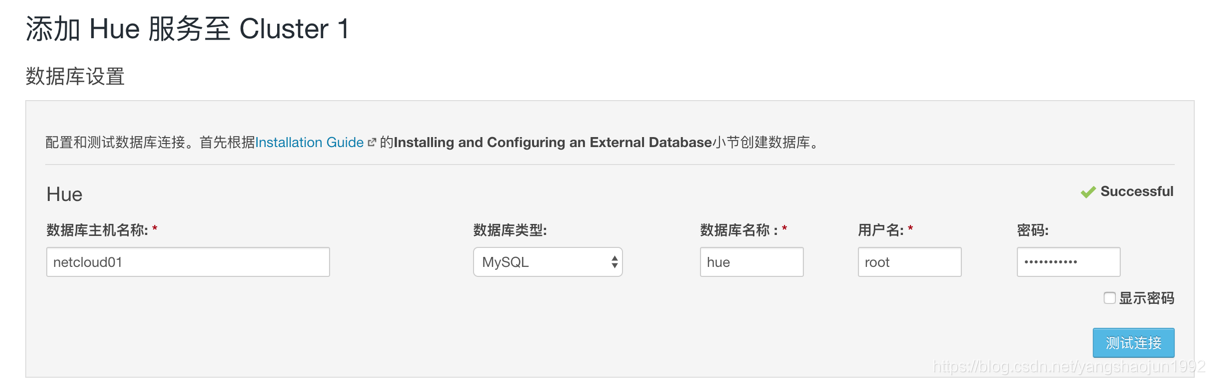
添加 hue服务
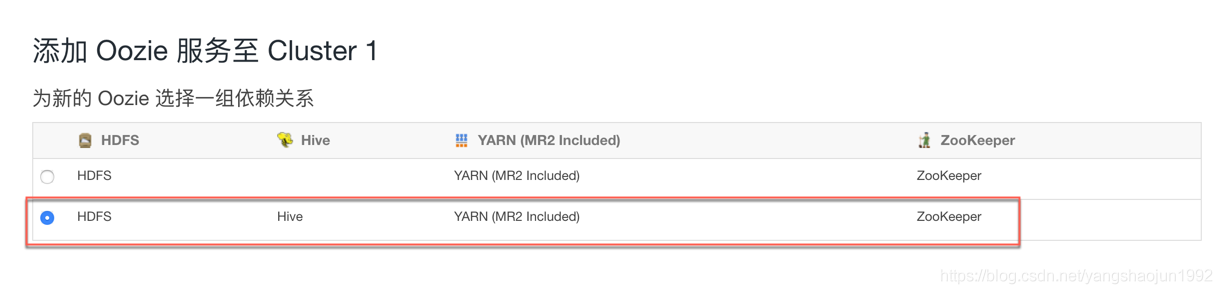
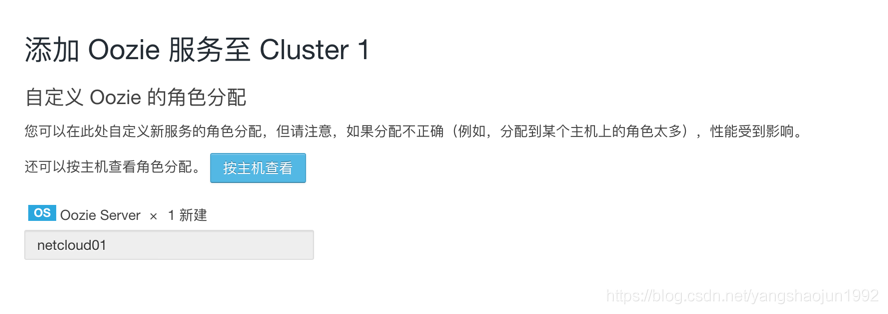
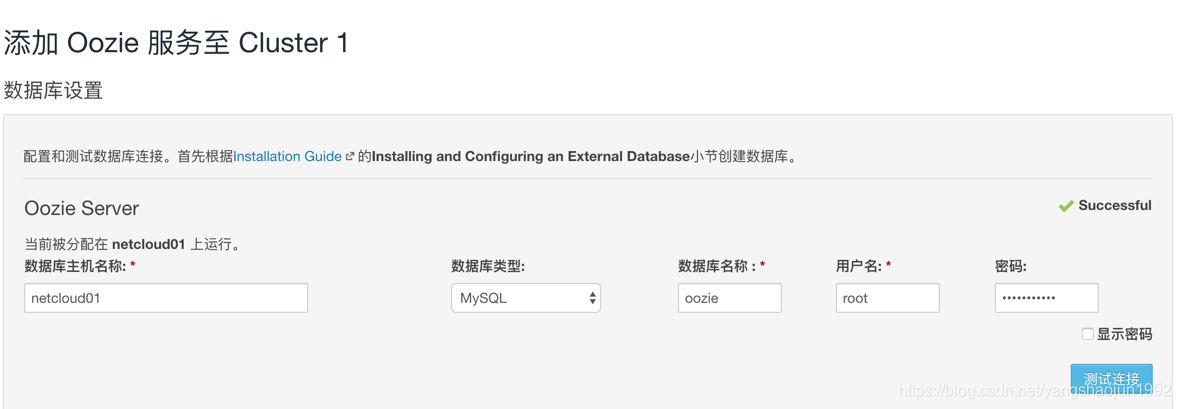
安装hue之前需要安装Oozie服务
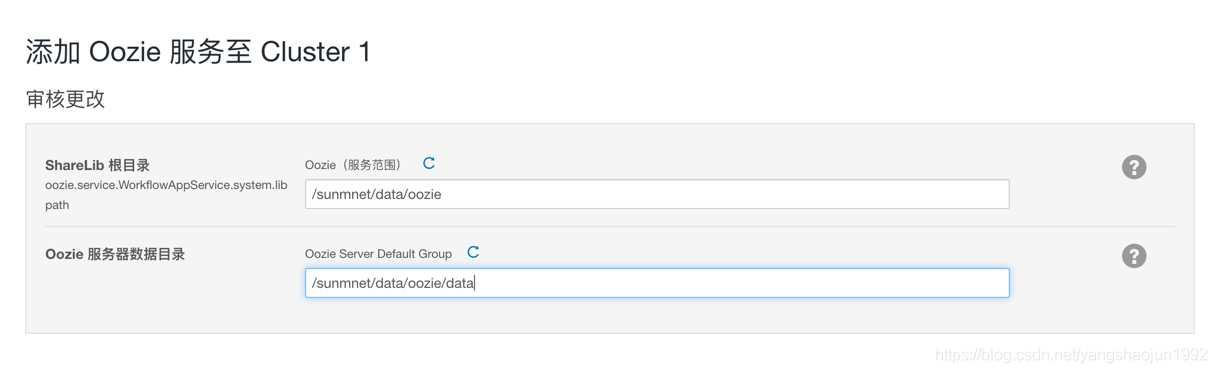
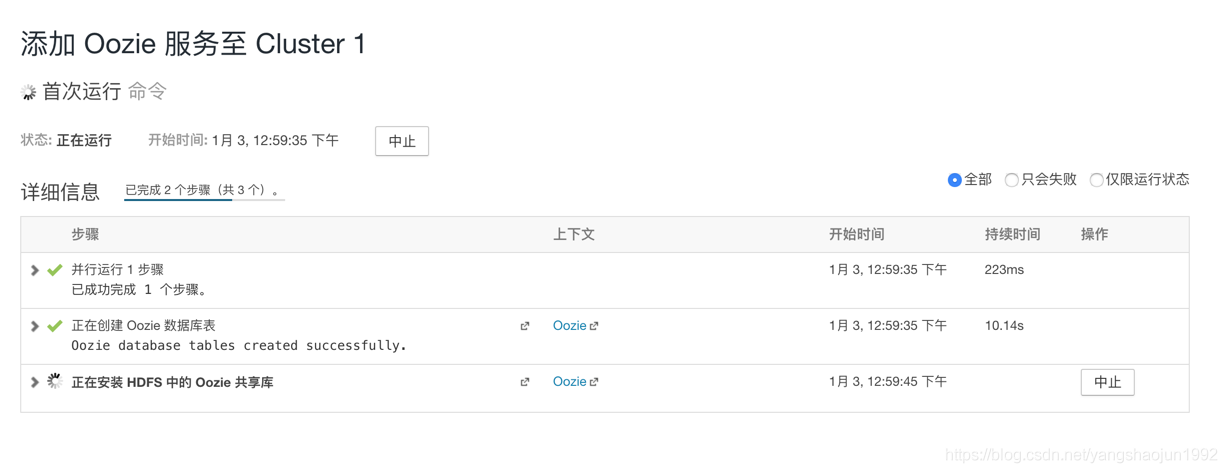
安装Hue服务
登录Hue ip:8888
首次登录 用户名密码任意
通常设置:hue、hue
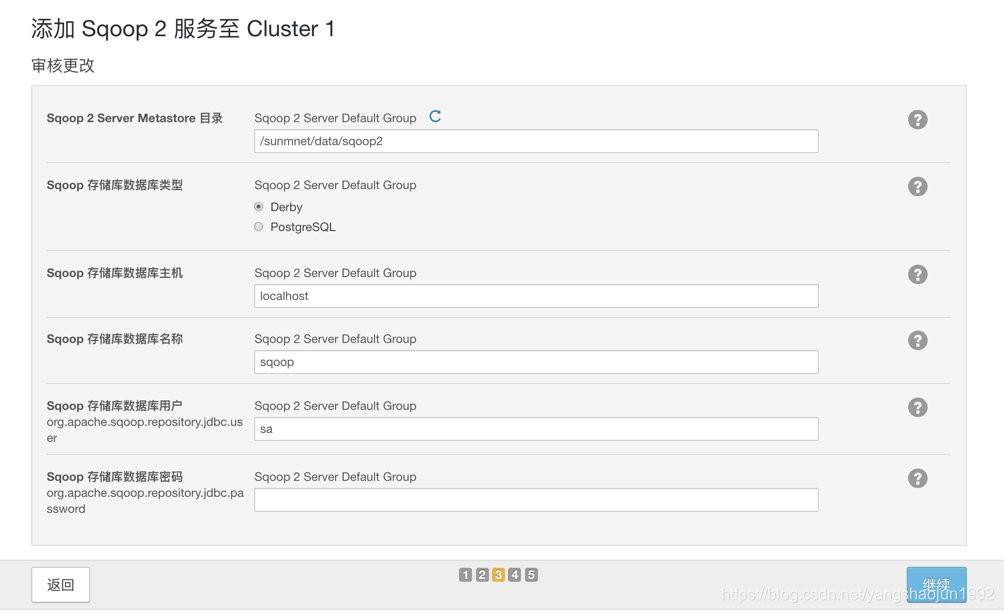
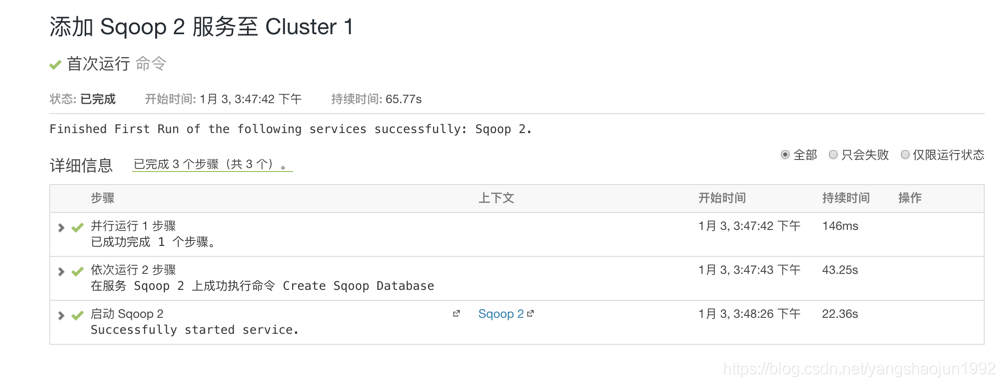
添加Sqoop服务

添加Spark服务
参考链接:https://www.cnblogs.com/yinzhengjie/p/9882293.html
SPARK2-2.2.0.cloudera1-1.cdh5.12.0.p0.142354-el6.parcel
SPARK2-2.2.0.cloudera1-1.cdh5.12.0.p0.142354-el6.parcel.sha
manifest.json
KAFKA-3.0.0-1.3.0.0.p0.40-el6.parcel
KAFKA-3.0.0-1.3.0.0.p0.40-el6.parcel.sha
将上面下载的文件放到 server节点的 /opt/cloudera/parcel-repo 目录下
KAFKA-1.2.0.jar
SPARK2_ON_YARN-2.2.0.cloudera1.jar
将 上面的两个jar包 放置到 server节点的 /opt/cloudera/csd
修改文件权限:
chown -R cloudera-scm:cloudera-scm /opt/cloudera
重启主节点cloudera-scm-server
cd /opt/cloudera-manager/cm-5.9.0/etc/init.d
./cloudera-scm-server start
查看启动日志:
cd /opt/cloudera-manager/cm-5.9.0/log/cloudera-scm-server
tailf cloudera-scm-server.log
#重启所有节点cloudera-scm-agent
cd /opt/cloudera-manager/cm-5.9.0/etc/init.d
./cloudera-scm-agent start
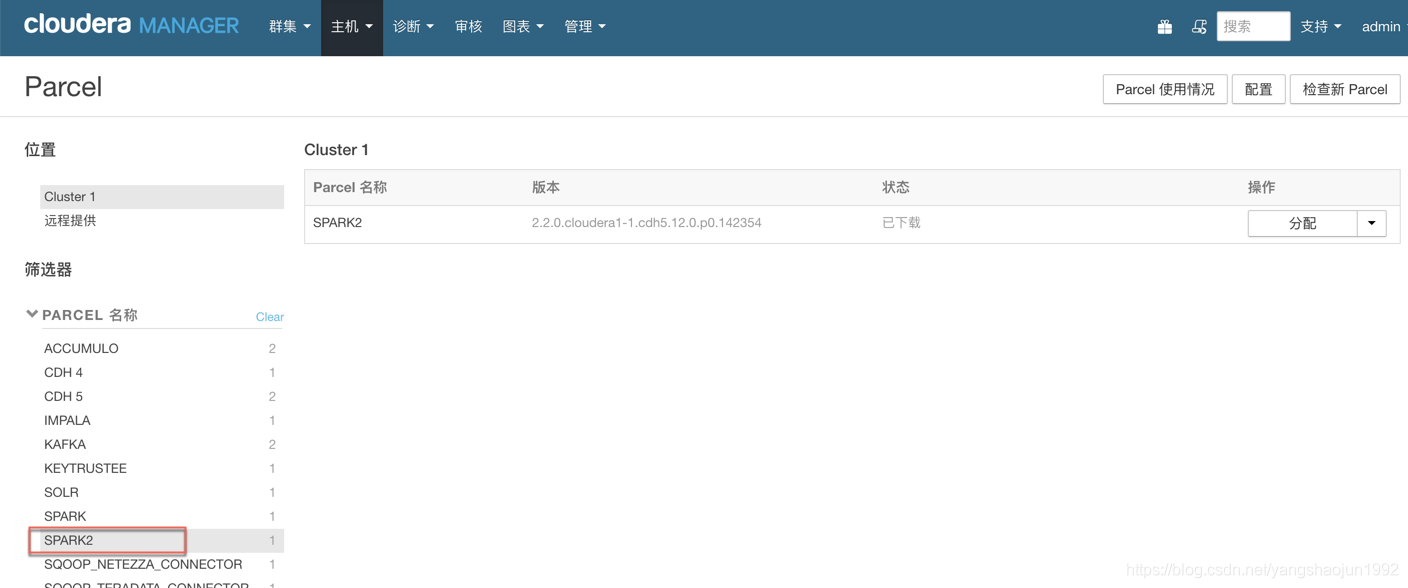
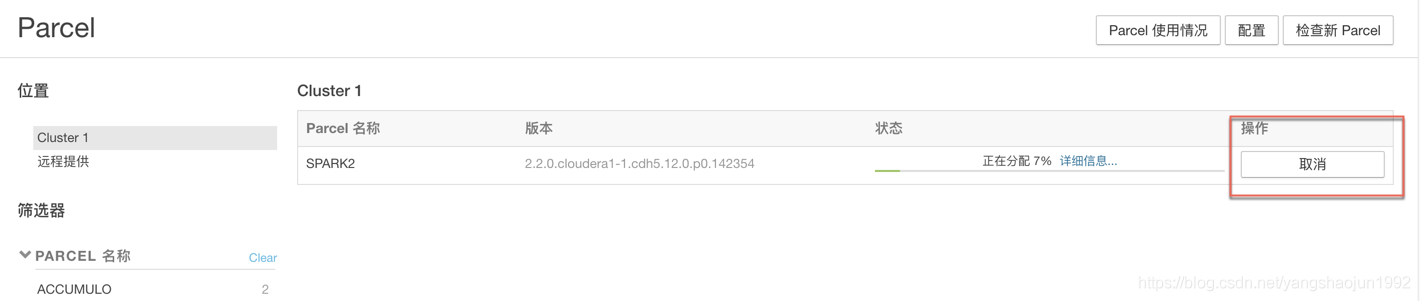
分配并激活parcel
进入到主机->Parcel
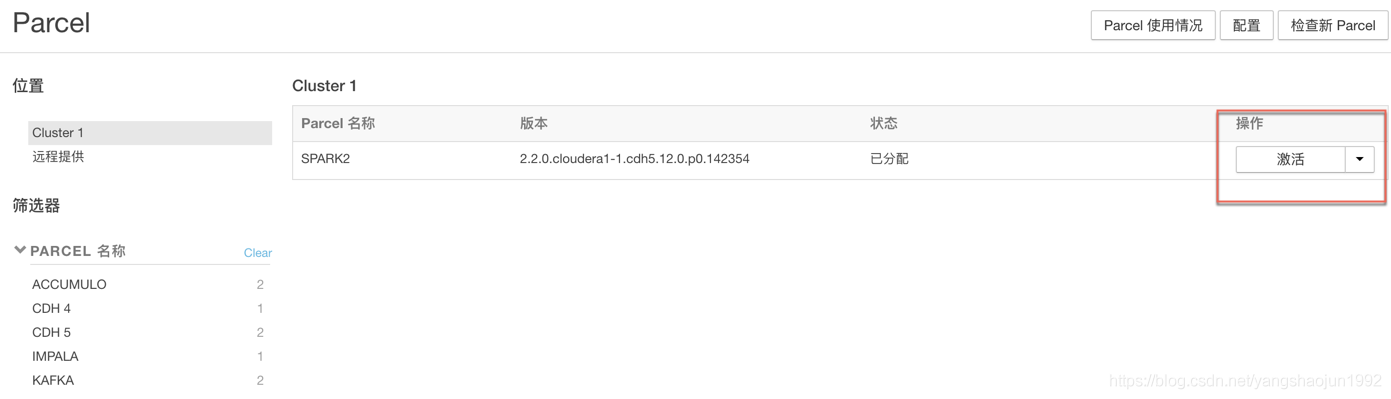
激活成功!!!

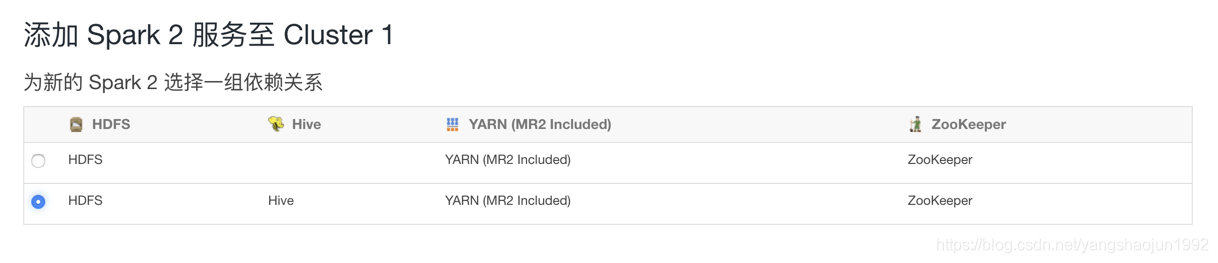
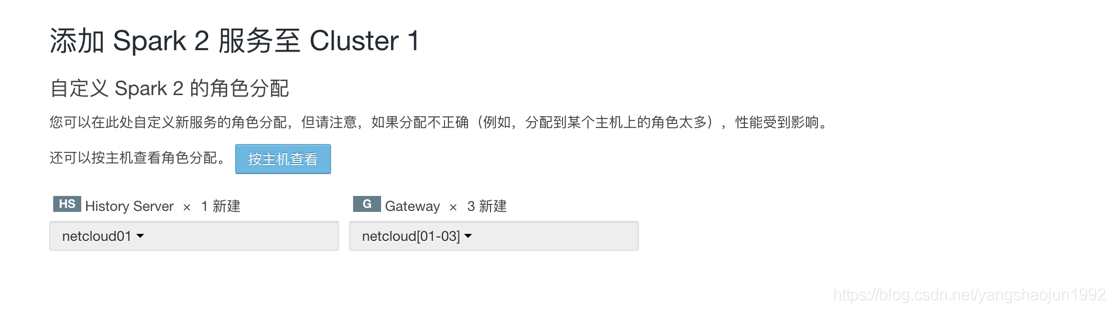
添加spark2服务
进入到进群页面集群->操作->添加服务

注意:如果没有出现spark2服务 可能jar包 没有存放到 /opt/cloudera/csd 目录下
措施:将jar 包放到/opt/cloudera/csd 目录 重启服务
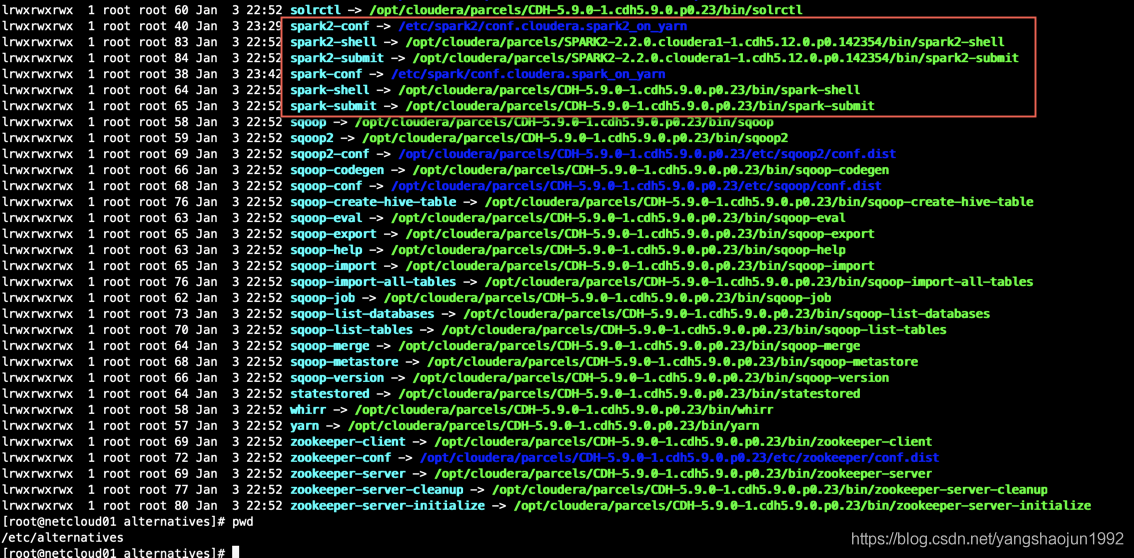
给JDK建立软连接 netcloud01、netcloud02、netcloud03 (mkdir /usr/java) 否则下面的部署Spark2 报错
ln -s /opt/jdk1.8.0_211 /usr/java/default
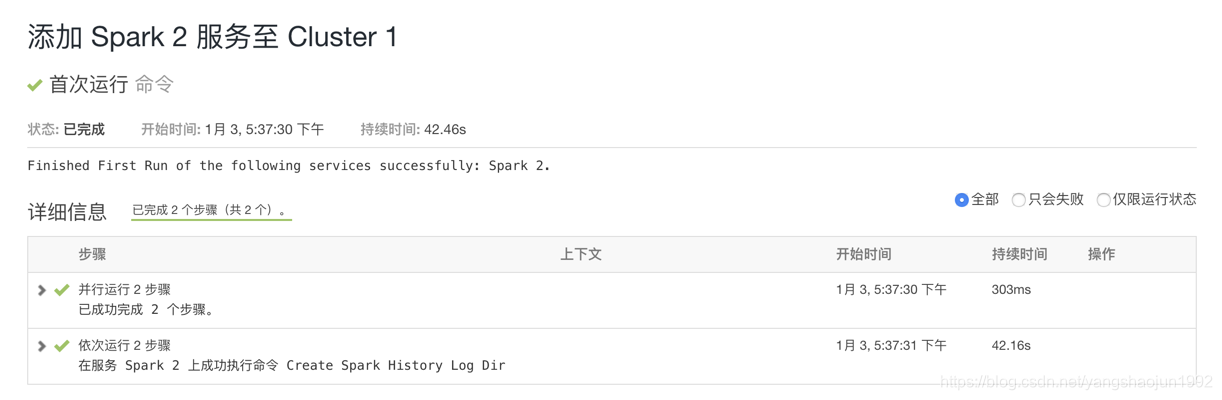
spark2.2安装成功
如果没有将jdk1.7修改成jdk1.8则上述步骤中安装时会提示,jdk的问题。
安装成功后:
在cloudera manager中能看到spark2安装成功
我们到集群中用hdfs用户查看 spark2-shell

解决办法:
- 将报错的2个参数增大到2G

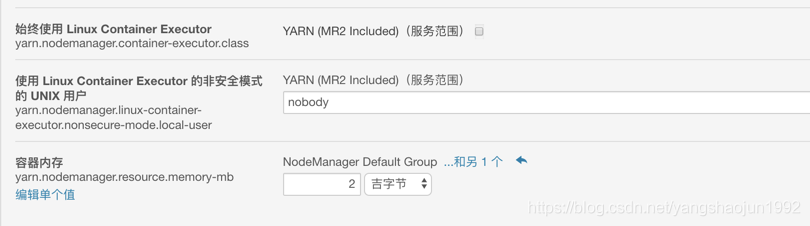


修改的参数:https://blog.csdn.net/weixin_33766168/article/details/93405662
容器内存
yarn.nodemanager.resource.memory-mb = 2G
最小容器内存
yarn.scheduler.minimum-allocation-mb = 1G
容器内存增量
yarn.scheduler.increment-allocation-mb =512M
最大容器内存
yarn.scheduler.maximum-allocation-mb = 2G
最小容器虚拟 CPU 内核数量
yarn.scheduler.minimum-allocation-vcores =1
容器虚拟 CPU 内核增量
yarn.scheduler.increment-allocation-vcores =1
最大容器虚拟 CPU 内核数量
yarn.scheduler.maximum-allocation-vcores =8
Map 任务内存
mapreduce.map.memory.mb =1G
Reduce 任务内存
mapreduce.reduce.memory.mb=1G
然后重启Yarn服务
启动完毕后,重新运行Spark,报新的错误:
19/01/07 22:07:33 ERROR spark.SparkContext: Error initializing SparkContext.
org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
4、于是切换成hdfs用户运行spark,这次没有任何错误,启动成功。
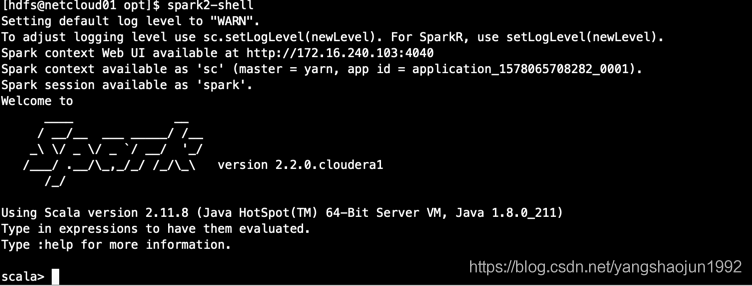
添加Spark服务(默认版本是 1.6.0)
前提是给jdk建立软连接
ln -s /opt/jdk1.8.0_211 /usr/java/default
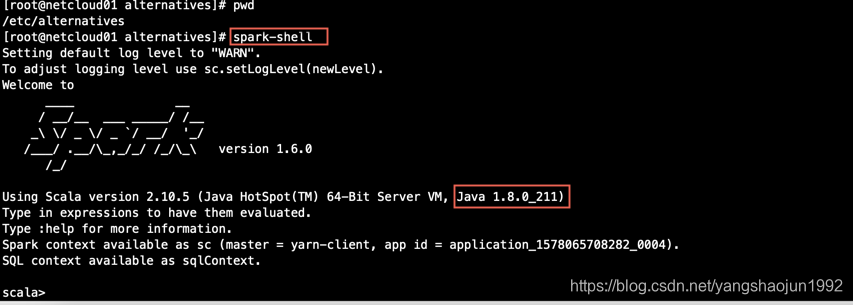
CDH 添加 Flume服务
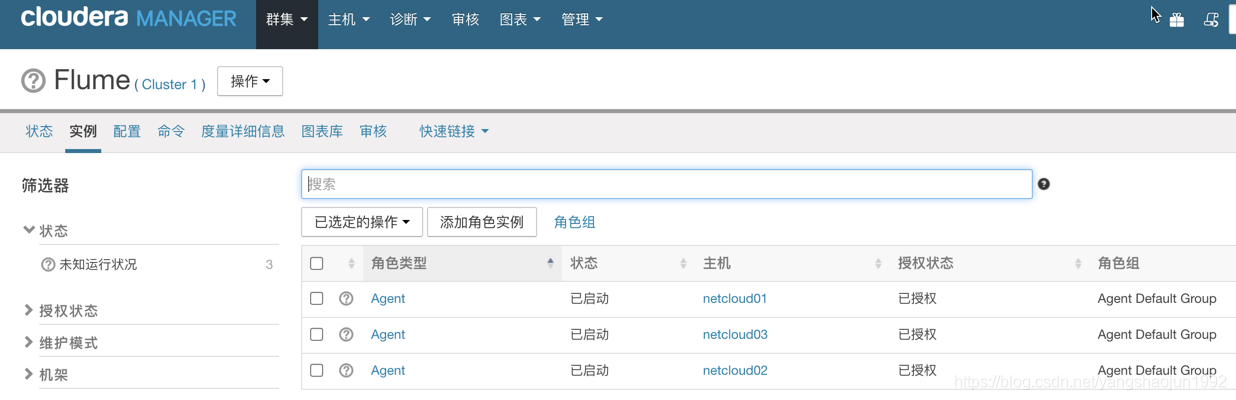
1. 在这里启动一下flume

修改配置文件
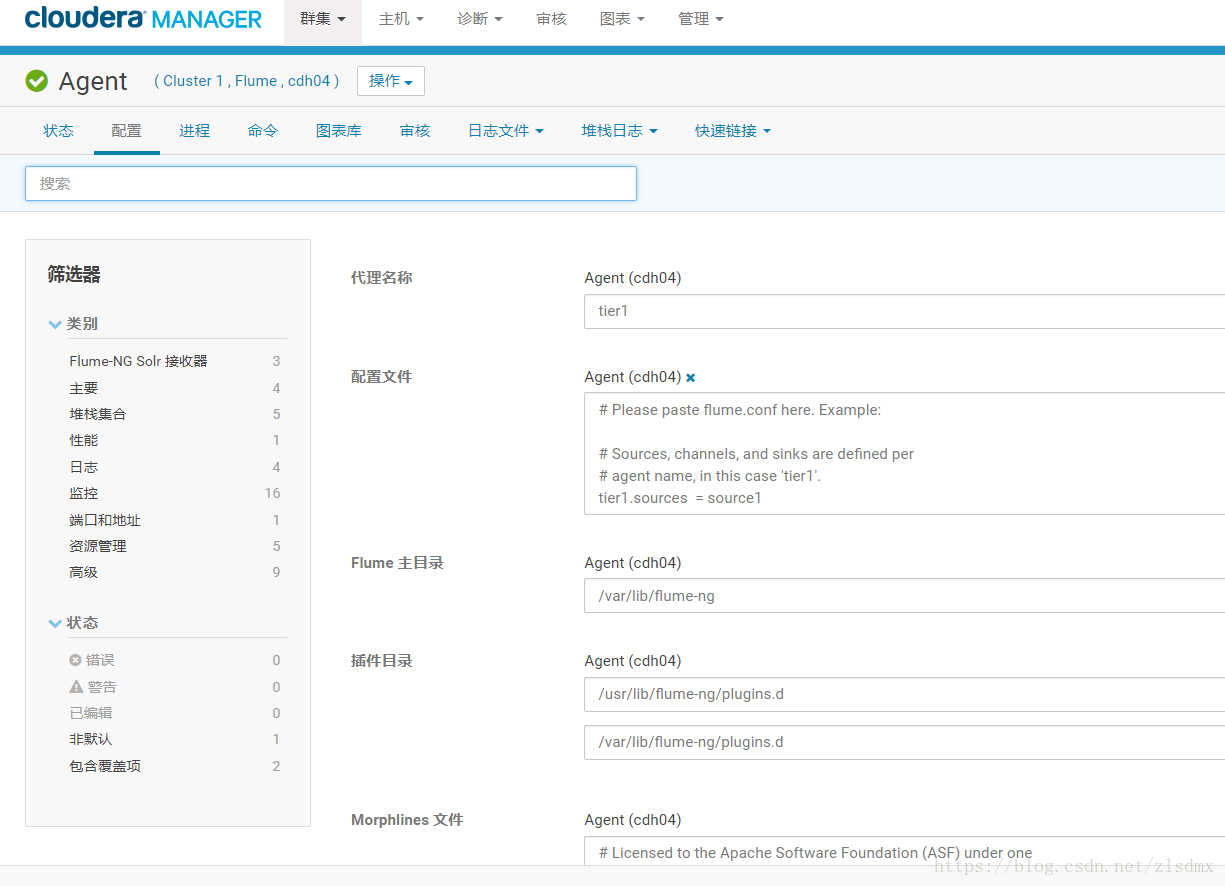
2.使用默认配置测试flume正常运行
默认配置文件配置了以netcat(网络打印输出)作为source,以内存memery作为channel,以logger作为sink输出到日志文件中的一个简单样例配置。
配置如下(如果是做flume的安装测试,无需改动该配置)
# Please paste flume.conf here. Example:
# Sources, channels, and sinks are defined per
# agent name, in this case 'tier1'.
tier1.sources = source1
tier1.channels = channel1
tier1.sinks = sink1
# For each source, channel, and sink, set
# standard properties.
tier1.sources.source1.type = netcat
tier1.sources.source1.bind = 127.0.0.1
tier1.sources.source1.port = 9999
tier1.sources.source1.channels = channel1
tier1.channels.channel1.type = memory
tier1.sinks.sink1.type = logger
tier1.sinks.sink1.channel = channel1
# Other properties are specific to each type of
# source, channel, or sink. In this case, we
# specify the capacity of the memory channel.
tier1.channels.channel1.capacity = 100agent的名字是tier1
source是source1
channel是channel1
sink是sink1
source的类型是netcat(来自网络的屏幕输出)
监听的网络地址是127.0.0.1本地
监听端口是 9999
source输出给channel1
使用memory作为channel1
channel1输出给sink1
sink1的类型是logger(日志)
最后一行是规定channel1每次的缓存能力是100
到这里,一切准备就绪了
3. 开始测试:
在netcloud01机器中,(也是上述安装了flume,和作了配置的机器),使用telnet工具连接到127.0.0.1(或则localhost) 9999端口(上述配置中source绑定的监听端口)【如果没有安装telnet,参考后面的telnet安装说明】
telnet localhost 9999
使用telnet连接到localhost本主机
出现Escape character is ‘^]’.后说明连接就绪
我们随意发送一些东西:
HELLO------------------
回车
如下:
telnet localhost 9999
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
HELLO------------------
OK4. 查看经过flume采集到日志中的情况:
日志位置:

找到此位置,tail -100 flume-cmf-flume-AGENT-netcloud01.log
找到
至此说明flume安装没问题了,可以使用了。
sudo yum -y install telnet-0.17-64.el7.x86_64
6. 将netcat数据通过flume采集到hdfs

按照如下配置修改flume的配置文件即可
# Please paste flume.conf here. Example:
# Sources, channels, and sinks are defined per
# agent name, in this case 'tier1'.
tier1.sources = source1
#tier1.sources = avro-source1
tier1.channels = channel1
tier1.sinks = sink1
# For each source, channel, and sink, set
# standard properties.
tier1.sources.source1.type = netcat
tier1.sources.source1.bind = 127.0.0.1
tier1.sources.source1.port = 9999
tier1.sources.source1.channels = channel1
tier1.channels.channel1.type = memory
# Define an Avro source called avro-source1 on agent1 and tell it
# to bind to 0.0.0.0:41414. Connect it to channel ch1.
#tier1.sources.avro-source1.channels = ch1
#tier1.sources.avro-source1.type = avro
#tier1.sources.avro-source1.bind = 0.0.0.0
#tier1.sources.avro-source1.port = 41414
#tier1.sources.avro-source1.threads = 5
#define source monitor a file
#tier1.sources.avro-source1.type = exec
#tier1.sources.avro-source1.shell = /bin/bash -c
#tier1.sources.avro-source1.command = tail -n +0 -F cdh03:/home/d2
#tier1.sources.avro-source1.channels = channel1
#tier1.sources.avro-source1.threads = 5
# tier1.sinks.sink1.type = hdfs
tier1.sinks.sink1.channel = channel1
# Describe the sink
tier1.sinks.sink1.type = hdfs
tier1.sinks.sink1.hdfs.path = /flume/
tier1.sinks.sink1.hdfs.fileType = DataStream
tier1.sinks.sink1.hdfs.filePrefix=test_flume
tier1.sinks.sink1.hdfs.rollCount=0
tier1.sinks.sink1.hdfs.rollInterval=0
# Other properties are specific to each type of
# source, channel, or sink. In this case, we
# specify the capacity of the memory channel.
tier1.channels.channel1.capacity = 100提示:tier1.sinks.sink1.hdfs.path = /flume/这句指定了数据存放到hdfs中的位置,但这里并没有带’hdfs://'这个schame,是因为,在cdh中配置的flume会自动识别配置hdfs的这个schame。当然你加上也不会错。
CDH 添加 Kafka服务
简介:
CDH的parcel包中是没有kafka的,kafka被剥离了出来,需要从新下载parcel包安装。或者在线安装,但是在线安装都很慢,这里使用下载parcel包离线安装的方式。
PS:kafka有很多版本,CDH也有很多版本,那也许你会疑问如何知道你的CDH应该安装什么kafka版本。这个官方有介绍,文档地址:https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolidated_pcm.html#pcm_kafka ,这里截图:

一。安装准备:
所需软件:
①kafka csd包,下载地址:http://archive.cloudera.com/csds/kafka/

②kafka parcel包:
csd包:http://archive.cloudera.com/csds/kafka/
parcel包: http://archive.cloudera.com/kafka/parcels/latest/ ( 根据自己的集群的系统版本下载 )
我用的是centos6.8 x64的系统,所以我下载的parcel包为 KAFKA-3.0.0-1.3.0.0.p0.40-el6.parcel 与KAFKA-3.0.0-1.3.0.0.p0.40-el6.parcel.sha
集成实现
1.关闭集群,关闭cm服务( 假如不关闭cm服务,会出现在添加kafka服务时找不到相关的服务描述 )
2. 将csd包放到cm安装节点下的 /opt/cloudera/csd目录下,如图 :
![]()
3. 将parcel包放到cm安装节点下的 /opt/cloudera/parcel-repo目录下,如图:

4. 启动cm服务,分配并激活percel包

添加kafka服务:

如果报内存的错误,再调整内存的大小比例。
启动kafka时会报内存溢出类的错误,需要调整kafka的堆栈大小,修改Java Heap Size of Broker的大小为512M以上
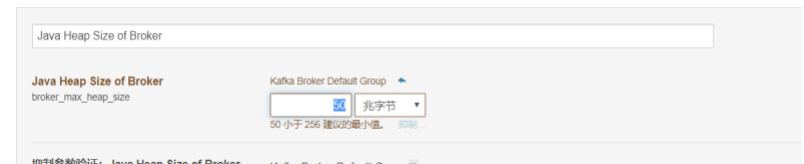
1)查看 Kafka Topic 列表
cd /usr/bin
./kafka-topics --list --zookeeper netcloud01:2181,netcloud02:2181,netcloud03:2181
./kafka-topics (真实目录 /opt/cloudera/parcels/KAFKA-3.0.0-1.3.0.0.p0.40/bin/kafka-topics)
2)创建 Kafka Topic
cd /usr/bin
./kafka-topics --create --zookeeper netcloud01:2181,netcloud02:2181,netcloud03:2181 --replication-factor 1 --partitions 1 --topic topic_log
3)删除 Kafka Topic
cd /usr/bin
./kafka-topics --delete --zookeeper netcloud01:2181,netcloud02:2181,netcloud03:2181 --topic topic_log
4)Kafka 生产消息
./kafka-console-producer --broker-list netcloud01:9092,netcloud02:9092,netcloud03:9092 --topic topic_log
5)Kafka 消费消息
./kafka-console-consumer --bootstrap-server netcloud01:9092,netcloud02:9092,netcloud03:9092 --from-beginning --topic topic_log
6)查看 Kafka Topic 详情
./kafka-topics --zookeeper netcloud01:2181 --describe --topic topic_log
项目经验之 Kafka 机器数量计算:
Kafka 机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署 Kafka 的数量。
比如我们的峰值生产速度是 50M/s。副本数为 2。 Kafka 机器数量=2*(50*2/100)+ 1=3 台
项目经验值 Kafka 分区数计算
项目经验值 Kafka 分区数计算:
增加Kafka分区数可以提高并行度及数据的消费能力;
Kafka分区数越多,并发度越高。到底设置多少个分区呢?
1)创建一个只有 1 个分区的 topic
2)测试这个 topic 的 producer 吞吐量和 consumer 吞吐量。
3)假设他们的值分别是 Tp 和 Tc,单位可以是 MB/s。
4)然后假设总的目标吞吐量是 Tt,那么分区数=Tt / min(Tp,Tc)
例如:producer 吞吐量=20m/s;consumer 吞吐量=50m/s,期望吞吐量 100m/s;
分区数=100 / 20 =5 分区
https://blog.csdn.net/weixin_42641909/article/details/89294698
分区数一般设置为:3-10 个
错误总结:
1)CDH spark 部署客户端报错-生成客户端配置报错deploy client configuration fail
https://blog.csdn.net/u013168566/article/details/84876435
2)Uncaught exception: org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException: Invalid resource request, requested virtual cores < 0, or requested virtual cores > max configured, requestedVirtualCores=4, maxVirtualCores=2
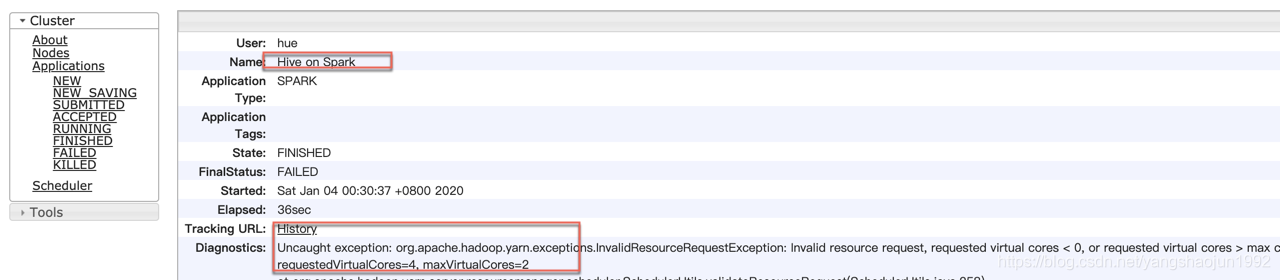
解决方法(调整yarn内存大小):http://blog.sina.com.cn/s/blog_e699b42b0102xg2k.html
3) hive 提交作业 :Requested user hue is not whitelisted and has id 480,which is below the minimum allowed 1000
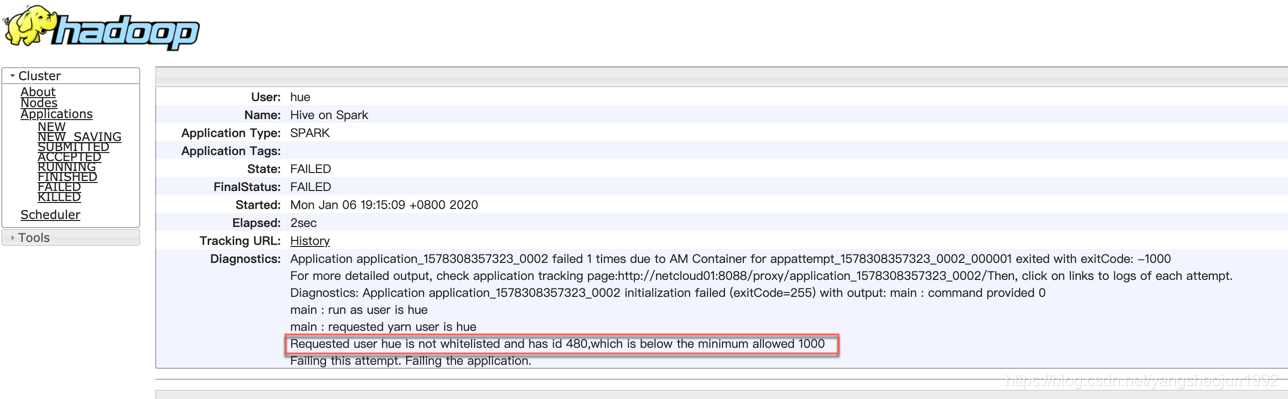
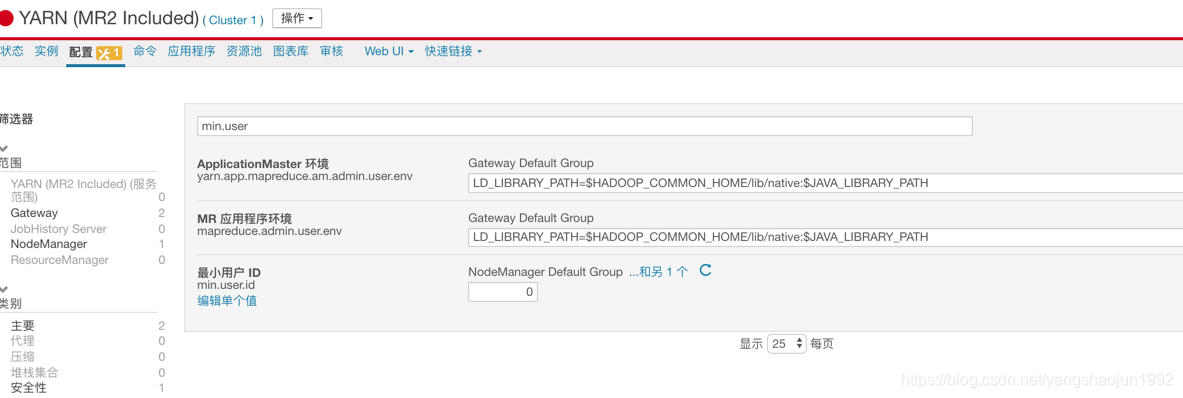
优化措施
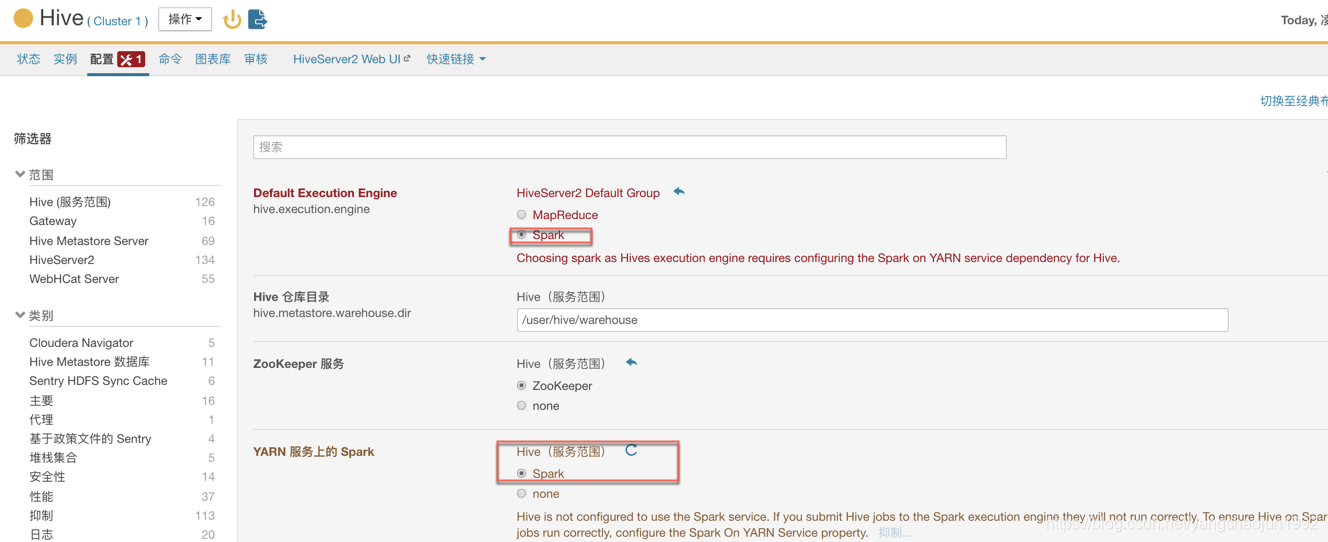
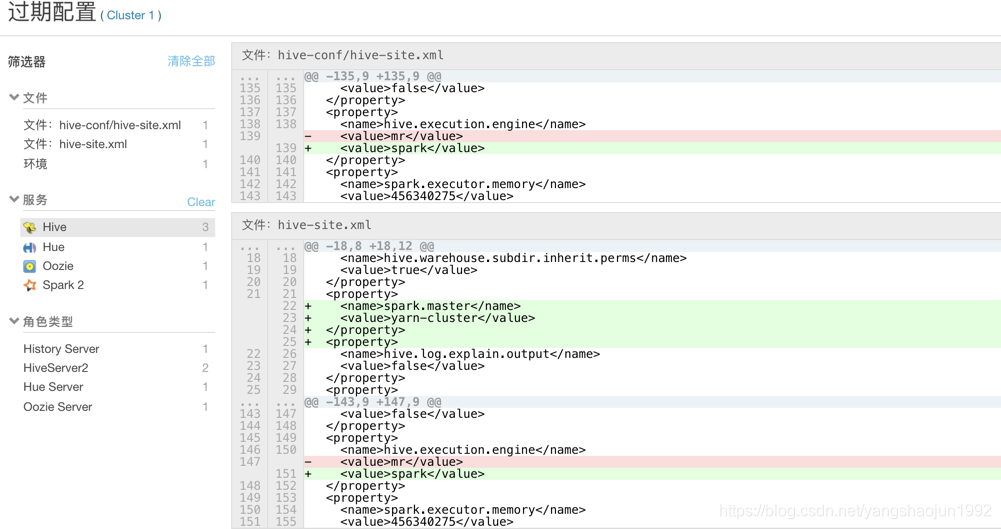
1)修改hive的执行引擎为spark
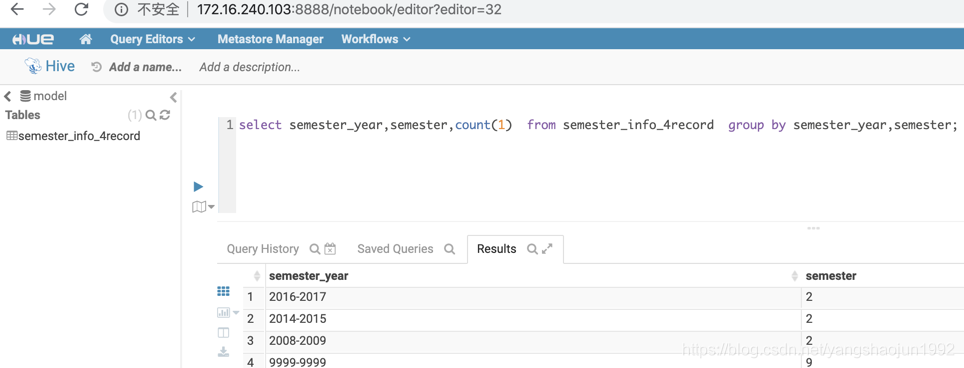
测试使用
查看执行的任务
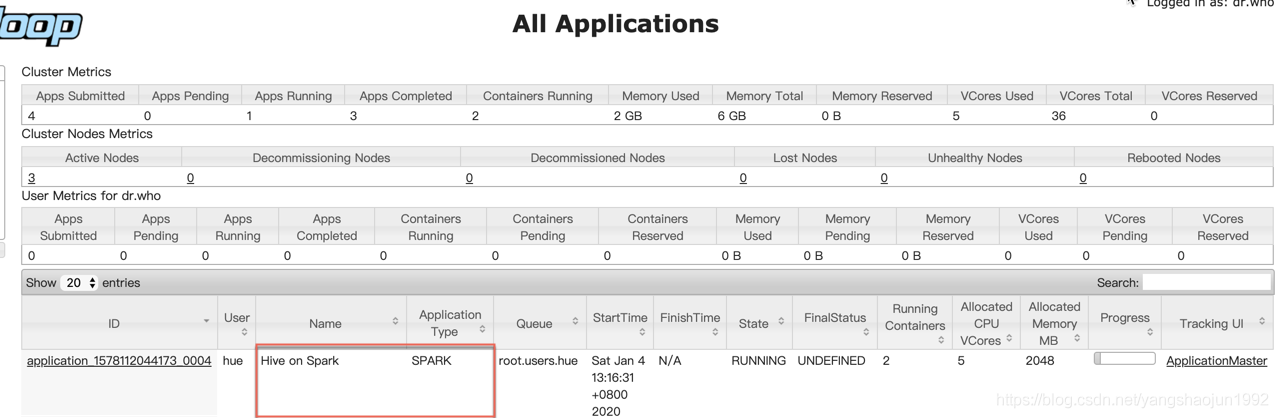
杀死任务命令:
yarn application -kill job id
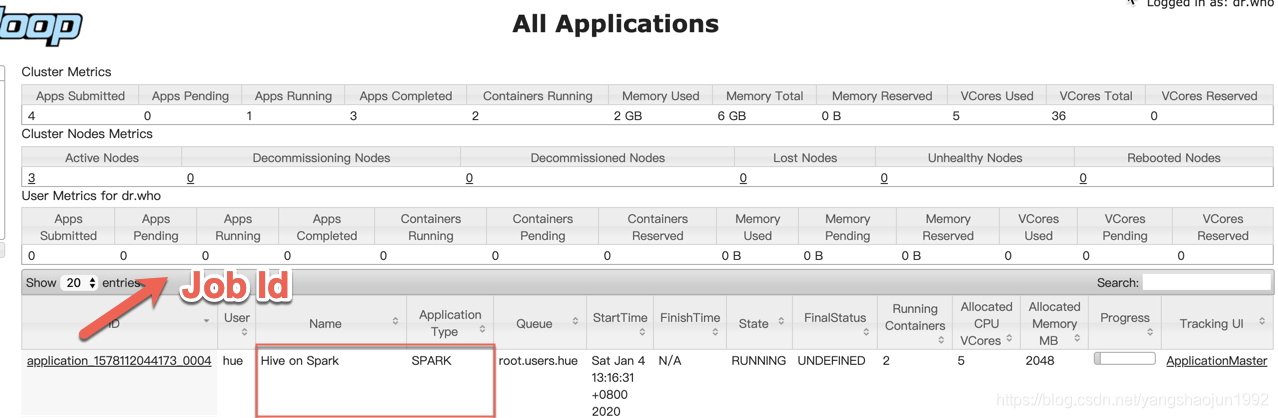
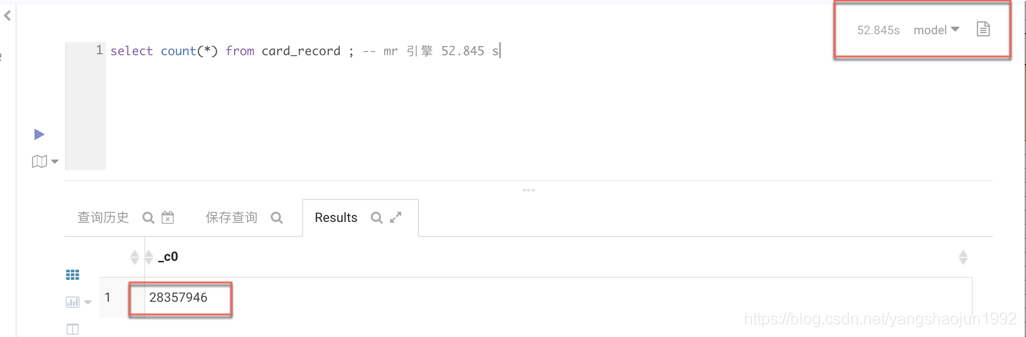
2)比较
MR引擎

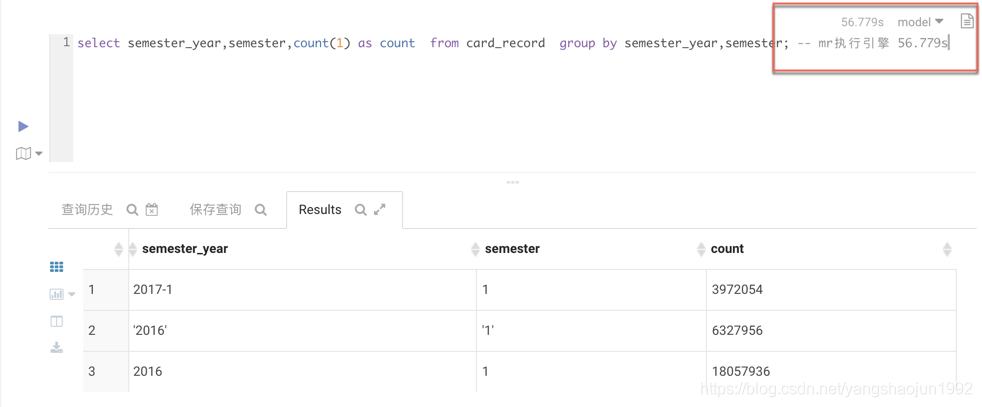
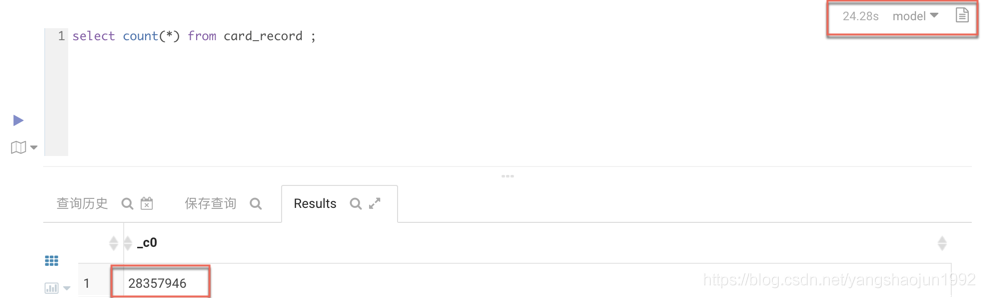
下面用的是Spark作为执行引擎

ClouderaManager使用
功能:
1、管理监控集群主机。
2、统一管理配置。
3、管理维护Hadoop平台系统。
名词解释:
主机 - host
机架 - rack
集群 - Cluster
服务 - service (hive、hdfs、zookeeper等)
服务实例 - service instance
角色 - role (nameNode、dataNode等)
角色实例 - role instance
角色组 - role group
主机模板 - host template
parcel (安装包)
静态服务池 - static service pool
动态资源池 - dynamic resource pool
1、集群管理
添加、删除集群
启动、停止、重启集群
重命名集群
全体集群配置
移动主机
2、主机管理
查看主机详细
主机检查
集群添加主机
分配机架
主机模板
维护模式
删除主机
3、服务管理
添加服务
对比不同集群上的服务配置
启动、停止、重启服务
滚动重启
终止客户端正在执行的命令
删除服务
重命名服务
配置最大进程数
rlimit_fds
4、角色管理
角色实例
添加角色实例
启动、停止、重启角色实例
解除授权
重新授权
删除角色实例
角色组
创建角色组
管理角色组
5、资源管理
动态资源池
静态服务池
6、用户管理
7、安全管理
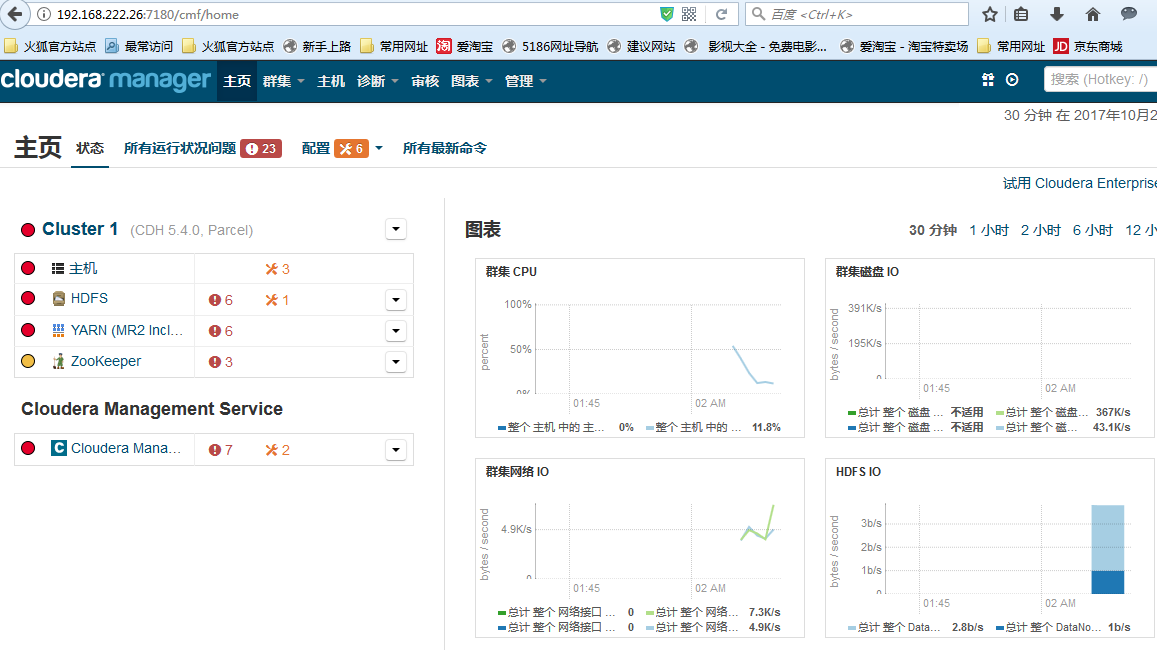
注意:到目前为止三台节点上的角色以及软件的安装情况
node01:HDFS、YARN、Zookeeper、Hive、oozie nameNode、dataNode
node02:HDFS、YARN、Zookeeper dataNode
node03:HDFS、YARN、Zookeeper dataNode
Hue
--Hue是一个开源的Apache Hadoop UI系统。
--通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据。
--例如操作HDFS上的数据、运行Hive脚本、管理Oozie任务等等。
--是基于Python Web框架Django实现的。
--支持任何版本Hadoop
基于文件浏览器(File Browser)访问HDFS
基于web编辑器来开发和运行Hive查询
支持基于Solr进行搜索的应用,并提供可视化的数据视图,报表生成
通过web调试和开发impala交互式查询
spark调试和开发
Pig开发和调试
oozie任务的开发,监控,和工作流协调调度
Hbase数据查询和修改,数据展示
Hive的元数据(metastore)查询
MapReduce任务进度查看,日志追踪
创建和提交MapReduce,Streaming,Java job任务
Sqoop2的开发和调试
Zookeeper的浏览和编辑
数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
组件配置文件目录
|
1.cloudera 的配置文件路径默认在什么位置? 2.如何通过cloudera manager web UI修改配置文件? 配置文件地址: Hadoop: /etc/hadoop/conf hbase: /etc/hadoop/conf hive: /etc/hive/conf |














 1322
1322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









