




 本文详细介绍了PyTorch深度学习框架,涵盖基本数据Tensor的创建与运算,如torch.FloatTensor、torch.abs等;介绍了神经网络工具箱torch.nn,以及如何用torch实现完整神经网络,包括自动求导、自定义传播等;还阐述了torchvision库及搭建神经网络的实现,如模型搭建、参数优化等。
本文详细介绍了PyTorch深度学习框架,涵盖基本数据Tensor的创建与运算,如torch.FloatTensor、torch.abs等;介绍了神经网络工具箱torch.nn,以及如何用torch实现完整神经网络,包括自动求导、自定义传播等;还阐述了torchvision库及搭建神经网络的实现,如模型搭建、参数优化等。
目录
4.3.6 torch.nn.CrossEntropyLoss
5.1.3.1 torchvision.transforms.Resize
5.1.3.2 torchvision.transforms.Scale
5.1.3.3 torchvision.transforms.CenterCrop
5.1.3.4 torchvision.transforms.RandomCrop
5.1.3.5 torchvision.transforms.RandomHorizontalFlip
5.1.3.6 torchvision.transforms.RandomVerticalFlip
5.1.3.7 torchvision.transforms.ToTensor
5.1.3.8 torchvision.transforms.ToPILImage:
5.1.3.9 torchvision.transforms.Compose(transforms)
前言
学习深度学习一个好的框架十分的重要,现在主流的就是PyTorch和TensorFlow,今天我们一起来学习PyTorch,PyTorch是使用GPU和CPU优化的深度学习张量库。本文通过详细且实践性的方式介绍了 PyTorch 的基础知识、张量操作、自动求导机制、神经网络创建、数据处理、模型训练、测试以及模型的保存和加载。
一、基本数据:Tensor
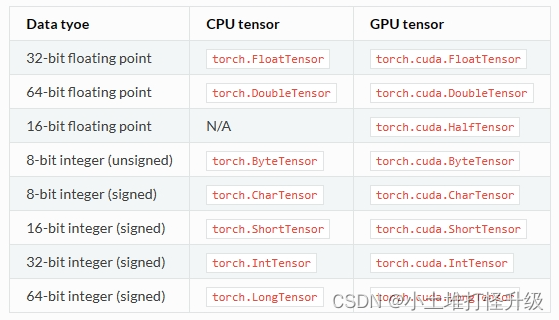
Torch定义了七种CPU tensor类型和八种GPU tensor类型:
Tensor,即张量,是PyTorch中的基本操作对象,可以看做是包含单一数据类型元素的多维矩阵。从使用角度来看,Tensor与NumPy的ndarrays非常类似,相互之间也可以自由转换,不过Tensor还支持GPU的加速。
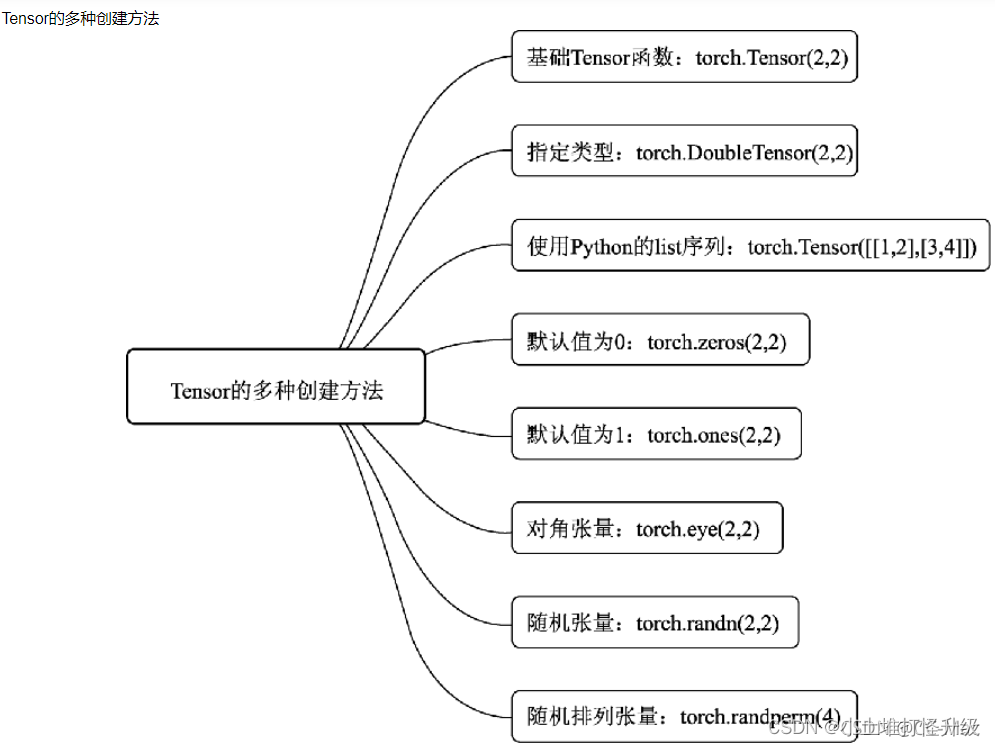
1.1 Tensor的创建
1.2 torch.FloatTensor
torch.FloatTensor用于生成数据类型为浮点型的Tensor,传递给torch.FloatTensor的参数可以是维度值,也可以是一个列表。torch.Tensor是默认的tensor类型(torch.FlaotTensor)的简称。
import torch
a = torch.FloatTensor(2,3)
b = torch.FloatTensor([2,3,4,5])
a,b
得到的结果是:
(tensor([[1.0561e-38, 1.0102e-38, 9.6429e-39],
[8.4490e-39, 9.6429e-39, 9.1837e-39]]),
tensor([2., 3., 4., 5.]))
1.3 torch.IntTensor
torch.IntTensor用于生成数据类型为整型的Tensor,传递给传递给torch.IntTensor的参数可以是维度值,也可以是一个列表。
import torch
a = torch.IntTensor(2,3)
b = torch.IntTensor([2,3,4,5])
print(f"""{a}
{b}""")
得到的结果是:
tensor([[0, 0, 0],
[0, 0, 0]], dtype=torch.int32)
tensor([2, 3, 4, 5], dtype=torch.int32)
1.4 torch.randn
用于生成数据类型为浮点数且维度指定的随机Tensor,和在numpy中使用的numpy.randn生成的随机数的方法类似,随机生成的浮点数的取值满足均值为0,方差为1的正态分布。
import torch
a = torch.randn(2,3)
print(a)
得到的结果是:
tensor([[-0.4916, -0.5392, 1.4072],
[ 0.5161, 1.4514, -0.3777]])
1.5 torch.range
torch.range用于生成数据类型为浮点型且起始范围和结束范围的Tensor,所以传递给torch.range的参数有三个,分别为起始值,结束值,步长,左右都是闭区间,即1到20都可取。其中步长用于指定从起始值到结束值得每步的数据间隔。
import torch
a = torch.range(1,20,2)
print(a)
得到的结果是:
tensor([ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.])
1.6 torch.zeros/ones/empty
torch.zeros用于生成数据类型为浮点型且维度指定的Tensor,这个浮点型的Tensor中的元素值全部为0。也可以是torch.Tensor(2, 3).zero_()
import torch
a = torch.zeros(2,3)
print(a)得到的结果是:
tensor([[0., 0., 0.],
[0., 0., 0.]])
torch.ones生成全1的数组。
import torch
a = torch.ones(2,3)
print(a)得到的结果是:
tensor([[1., 1., 1.],
[1., 1., 1.]])
torch.empty创建一个未被初始化数值的tensor,tensor的大小是由size确定。
size: 定义tensor的shape ,这里可以是一个list 也可以是一个tuple
import torch
a = torch.empty(2,3)
print(a)得到的结果是:
tensor([[7.5338e+28, 5.9288e+11, 6.1186e-04],
[4.3988e+21, 7.5631e+28, 5.2839e-11]])
二、Tensor的运算
2.1 torch.abs()
将参数传递到torch.abs后返回输入参数的绝对值作为输出,输入参数必须是一个Tensor数据类型的变量,如:
import torch
a = torch.randn(2,3)
print(a)得到的a是:
tensor([[-0.2852, 1.0085, -1.0338],
[-0.1877, -1.6604, -1.0330]])
对a进行abs处理:
b = torch.abs(a)
print(b)得到的b是:
tensor([[0.2852, 1.0085, 1.0338],
[0.1877, 1.6604, 1.0330]])
2.2 torch.add()
将参数传递到torch.add后返回输入参数的求和结果作为输出,输入参数既可以全部是Tensor数据类型的变量,也可以一个是Tensor数据类型的变量,另一个是标量。
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(2,3)
print(b)
c = torch.add(a,b)
print(c)得到的结果:
tensor([[0.0408, 1.1193, 1.2028],
[0.6015, 0.4013, 2.1503]])
tensor([[-0.1892, -0.9570, -1.3704],
[ 0.8400, -1.9080, 0.9387]])
tensor([[-0.1484, 0.1623, -0.1676],
[ 1.4416, -1.5067, 3.0890]])
再看tensor和标量的情况:
import torch
a = torch.randn(2,3)
print(a)
b = 10
print(b)
c = torch.add(a,b)
print(c)tensor([[ 0.8901, 0.0094, 0.7158],
[ 0.4988, -0.2313, 0.0321]])
10
tensor([[10.8901, 10.0094, 10.7158],
[10.4988, 9.7687, 10.0321]])
2.3 torch.clamp()
torch.clamp是对输入参数按照自定义的范围进行裁剪,最后将参数裁剪的结果作为输出,所以输入参数一共有三个,分别是需要进行裁剪的Tensor数据类型的变量、裁剪的下边界和裁剪的上边界,裁剪过程:使用变量中的每个元素分别与下边界和上边界的值进行比较,如果元素的值小于裁剪的下边界的值,该元素被重写成下边界的值;如果元素的值大于上边界的值,该元素就被重写成上边界的值。如果元素的值在下边界和上边界之间就不变。
import torch
a = torch.randn(2,3)
print(a)
b = torch.clamp(a,-1,1)
print(b)得到的结果:
tensor([[ 1.8599, -1.3503, 0.2013],
[ 0.5805, -1.9710, 0.2958]])
tensor([[ 1.0000, -1.0000, 0.2013],
[ 0.5805, -1.0000, 0.2958]])
2.4 torch.div()
torch.div是将参数传递到torch.div后返回输入参数的求商结果作为输出,同样,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(2,3)
print(b)
c = torch.div(a,b)
print(c)tensor([[ 1.1057, 0.3762, 0.2585],
[-0.6597, 0.2669, 0.5578]])
tensor([[ 0.0687, 0.6306, -0.4086],
[ 0.7401, 0.6681, -0.6704]])
tensor([[16.1001, 0.5966, -0.6326],
[-0.8914, 0.3995, -0.8320]])
2.5 torch.pow()
torch.pow:将参数传递到torch.pow后返回输入参数的求幂结果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
import torch
a = torch.randn(2,3)
print(a)
b = torch.pow(a,2)
print(b)tensor([[-0.1936, 0.9489, 0.4453],
[-0.9187, -1.0279, 0.3552]])
tensor([[0.0375, 0.9004, 0.1983],
[0.8440, 1.0565, 0.1262]])
2.6 torch.mm()
torch.mm(a,b):正常矩阵相乘,要求a的列数与b的行数相同。torch.mm(a,b)等价于a@b.T
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(2,3)
print(b)
c = torch.mm(a,b.T)
print(c)
d = a@b.T
print(c == d)tensor([[-0.0761, -2.0854, 0.4789],
[-1.5470, -0.2247, -0.1333]])
tensor([[-1.2039, -0.3026, -0.3079],
[ 0.4885, -0.0547, -0.4160]])
tensor([[ 0.5752, -0.1224],
[ 1.9715, -0.6879]])
tensor([[ 0.5752, -0.1224],
[ 1.9715, -0.6879]])
tensor([[True, True],
[True, True]])
2.7torch.mul()
torch.mul(a,b)表示相同shape矩阵点乘,即对应位置相乘,得到矩阵有相同的shape。torch.mul(a,b)等同于a*b
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(2,3)
print(b)
c = torch.mul(a,b)
print(c)
d = a*b
print(c == d)tensor([[-0.4312, -0.0642, -0.7170],
[ 1.3519, 0.4870, -0.0252]])
tensor([[-0.1908, -0.7178, -0.5137],
[ 1.7802, 0.6434, -0.7291]])
tensor([[0.0823, 0.0461, 0.3683],
[2.4067, 0.3133, 0.0184]])
tensor([[True, True, True],
[True, True, True]])
2.8 torch.mv()
torch.mv(a,b):是矩阵和向量相乘.第一个参数是矩阵,第二个参数只能是一维向量,等价于a乘于b的转置
import torch
a = torch.randn(2,3)
print(a)
b = torch.randn(3)
print(b)
c = torch.mv(a,b)
print(c)tensor([[ 0.7834, 0.4062, -0.2497],
[-0.0176, 1.7290, 0.8626]])
tensor([1.7972, 0.5609, 0.9367])
tensor([1.4018, 1.7461])
小技巧:torch.mm丶torch.mul和torch.mv如何快速分别,matrix矩阵,vector向量,multiply相乘,
torch.mm:后面两个m表示matrix
torch.mul:mul是multiply的缩写
touch.mv:m是matr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









