







10.Spark调优策略

一:资源设置
core memory executor-num
executor driver

1)--executor-memory MEM 1G 每个executor的内存大小
Cache
shuffle
task
2)--executor-cores NUM 1 每个executor的cpu core数量
4exe * 2core = 8个
4exe * 4core = 16个
3)--num-executors 2 executor的数量
4exe * 2core = 8个
8exe * 2core = 16个
100task ? * 2 ?
4)--queue root.用户名 运行的队列
${SPARK_HOME}/bin/spark-submit --class xxxx \
master yarn \
--deploy-mode cluster \
--executor-cores ? \
--num-executors ? \
--executor-memory ? \
application.jar xxx yyy zzz
二:广播变量在Spark中的使用
50exe 1000task
val params = … // 10M
val rdd = …
rdd.foreach(x=>{…params…})
1000task * 10M = 10G
50exe * 10M = 500M
作业题: ETL处理中日志 join ip这个功能结合我们讲解的广播变量的原理及实现 重构我们的ETL实现逻辑
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object JoinApp02 {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "D:\\hadoop-2.7.1")
val spark = SparkSession.builder().master("local[*]").appName("JoinApp02").getOrCreate()
val peopleInfo: collection.Map[String, String] = spark.sparkContext
.parallelize(Array(("100", "pk"), ("101", "jepson"))).collectAsMap()
// 广播变量是把小表的数据通过sc广播出去
val peopleBroadcast: Broadcast[collection.Map[String, String]] = spark.sparkContext.broadcast(peopleInfo)
val peopleDetail: RDD[(String, (String, String, String))] = spark.sparkContext
.parallelize(Array(("100", "ustc", "beijing"), ("103", "xxx", "shanghai")))
.map(x => (x._1, x))
// TODO... 是Spark以及广播变量实现join
// mapPartitions做的事情: 遍历大表的每一行数据 和 广播变量的数据对比 有就取出来,没有就拉倒
peopleDetail.mapPartitions(x => {
val broadcastPeople: collection.Map[String, String] = peopleBroadcast.value
for((key,value) <- x if broadcastPeople.contains(key))
yield (key, broadcastPeople.get(key).getOrElse(""), value._2)
}).foreach(println)
Thread.sleep(2000000)
spark.stop()
}
}
三:Shuffle调优
map端缓冲区大小 : spark.shuffle.file.buffer 默认32k
如果过小 ==> 数据频繁写入磁盘文件
reduce端拉取数据缓冲区大小: spark.reducer.maxSizeInFlight
reduce端拉取数据重试次数:spark.shuffle.io.maxRetries 默认3次
reduce端拉取数据等待间隔:spark.shuffle.io.retryWait 默认5s
实际生产中这些参数调成可以以乘以2的叠加调整
四:JVM相关
对象==>eden 和其中一个survivor0区 此时另外一个survivor1是空
eden + survivor0 满 ==> minor gc
==> survivor1
8:1:1
old enough or Survivor2 is full ==> old ==> full gc
stop the world
个人建议在生产上优先使用CMS G1 JDK8
young gc/full gc 导致 stop the time 可能会导致出现 file not found/ file lost / timeout 等异常错误
调节连接等待时长 避免gc 导致的超时
spark.core.connection.ack.wait.timeout
调节executor堆外内存 spark.yarn.executor.memoryOverhead 1~2G之间
executor lost、oom、shuffle output file cannot find
300M
spark-submit时通过–conf 把我们讲解的这些参数一一设置进去即可
内存 统一内存管理方式(可以借的) 静态管理方式(固定)
其他调优
官方saprk的性能调优
官方提供的调优文档:
http://spark.apache.org/docs/latest/tuning.html
打开页面直接翻译看
官方Spark Sql 的性能调优
http://spark.apache.org/docs/latest/sql-performance-tuning.html

预估对象占用内存


12.云平台建设的思考
大数据项目和平台的差异性对比
Hadoop、Hive、Spark、Flink、Storm、Scala 其实都是大数据开发必备的技术/框架
项目(项目):以功能为主 中小公司/大公司
平台:大公司 提供给用户通用/定制化的解决方案
数据采集
离线计算
实时计算
机器学习
图计算
......
认知云平台能为我们提供的能力
为什么要构建大数据云平台
1)统一管控
数据分散、异构 ==> 信息孤岛
数据的存储、资源 ==> 统一的资源管控 造成资源浪费
2)能力
运维、支撑程度
性能、规模瓶颈
==>
数据湖:数据和资源的共享
云能力:集群、扩容、快速开发
大数据云平台功能架构
大数据云平台所涉及到的常见的功能
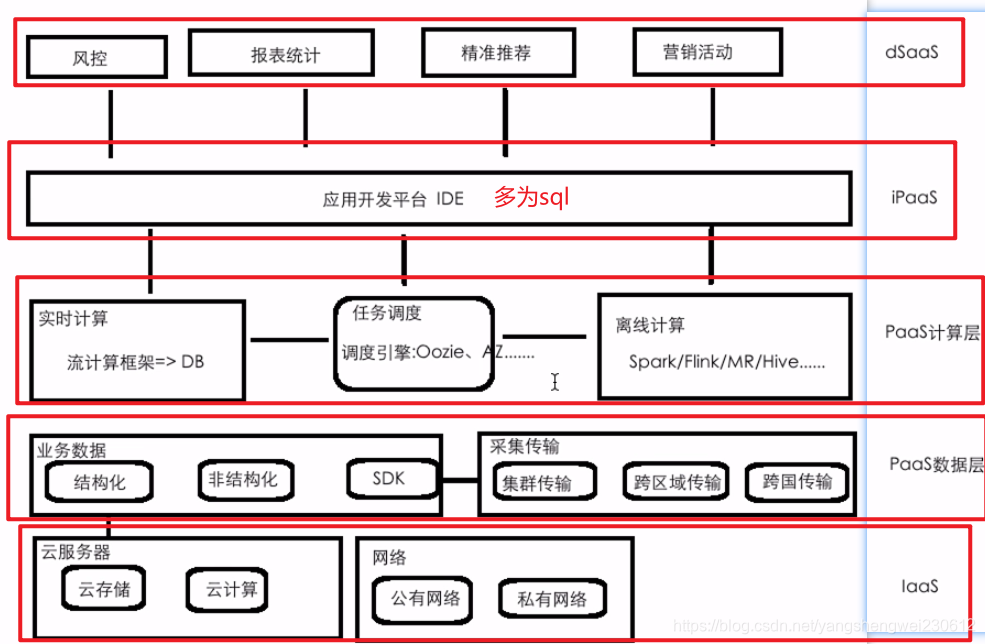
数据湖架构
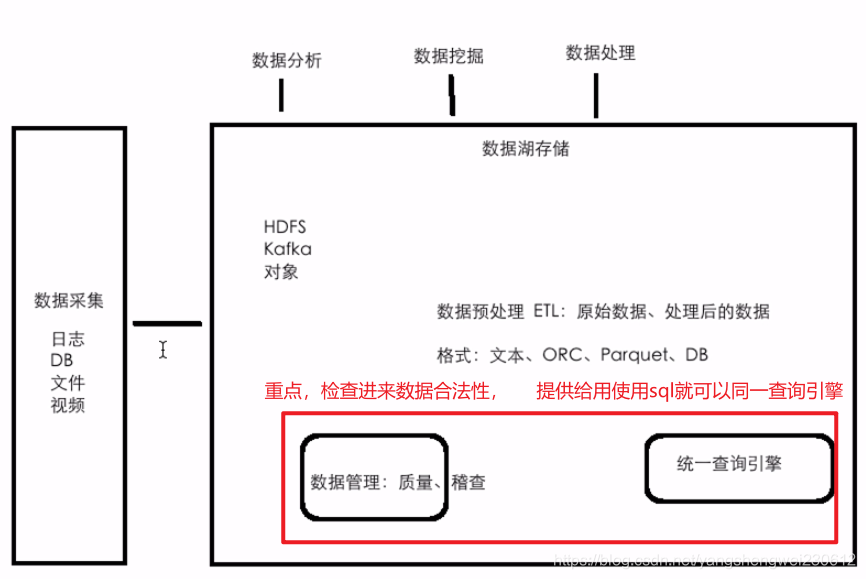
数据存储和计算角度剖析
存储和计算:大数据的思想 ==> Hadoop
公有云
多租户 多用户
==> 数据安全
==> 不同的租户或者用户登录到系统之后,能访问的数据的权限是不一样
==> Table: 行 列
==> 数据权限控制到行和列级别
==> 使用的资源也是不一样的 queue
私有云
有多个集群:热 冷 备份
数据迁移 自动、压缩
计算能力能否无缝对接 √
隔离:队列隔离、资源隔离
资源角度剖析
资源分配如何最优、资源使用率最大化
Spark/Flink
spark-submit 多少executor、每个executor多少memory、每个executor多少core?
调度框架:AZ、Oozie、crontab
一个作业涉及多个Job:workflow
多个job之间如何做资源隔离
Spark/Flink on YARN:申请资源是需要一定的时间的,调优使得申请资源的时间减少!
10分钟:2分钟+8分钟 30秒+9分30秒
兼容性角度剖析
兼容性角度
Apache Hadoop
CDH Cloudera Manager
HDP
MapR
华为:Huawei Manager FusionInsight
阿里
腾讯
百度
…
假设数据平台是基于CDH/HDP来构建的
但是:用户现在已有的数据是基于阿里、华为云来开发和运维的
务必要提前做一件事情:熟悉已有的数据平台的一些功能 vs 我们数据平台的功能
数据存储:CarbonData
调度:oozie ==> PK调度
执行引擎和运行方式适配角度剖析
引擎的适配
离线:Spark Flink
做一个功能:按照我们的产品设计文档,写一份代码,可以同时运行在不同的引擎上
√Spark
√Flink
Apache Beam 支持写一份代码,可以同时运行在不同的引擎上像spark、flink
运行方式的适配
√YARN
√K8S(Docker)
Spark和Flink的选择
Spark和Flink的选择性问题
Spark到现在社区是比较成熟、提供的功能也是比较完善的
Flink 实时部分
Spark 离线的性能优于Flink
Fllink的实时性优于SparkStreaming
13


动态分区裁剪
执行计划优化


自适应查询执行


开启自使用分区配置:

spark.sql.adaptive.enabled true

放开注释即可

根据数据量评估出来只需要一个分区


14 saprk sql 窗口函数
官网关于窗口函数的介绍
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html



mysql中的concat函数,concat_ws函数,concat_group函数之间的区别
mysql中的concat函数,concat_ws函数,concat_group函数之间的区别
列转行功能需求分析
源数据
id name dept sex
1,PK,RD,1
2,XIAOAI,RD,1
3,XIAOHONG,RD,2
4,XIAOZHANG,QA,1
5,XIAOLI,QA,2
6,XIAOFANG,QA,2
转换要求
按照部门和性别进行分组,名字之间使用|进行拼接
dept sex name
RD,1 PK|XIAOAI
RD,2 XIAOHONG
QA,1 XIAOZHANG
QA,2 XIAOLI|XIAOFANG
分析:
- 把dept和sex进行拼接
- group by
- 分组后的名字要采用什么函数使用|拼到一起
create table emp_info(
id string,
name string,
dept string,
sex string
) row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/data/imooc/emp_info.txt' overwrite into table emp_info;
select
t.dept_sex, concat_ws("|", collect_list(t.name))
from
(
select name, concat_ws(",",dept,sex) dept_sex from emp_info
) t group by t.dept_sex;
collect_set
collect_list
行转列功能需求分析
源数据
teacher courses
PK MapReduce,Hive,Spark,Flink
XIAOAI Hadoop,HBase,Kafka
转换后的数据格式
teacher courses
PK MapReduce
PK Hive
PK Spark
PK Flink
XIAOAI Hadoop
XIAOAI HBase
XIAOAI Kafka
分析:
- 借助于某一个函数能够把一列的数据按照某个分隔符进行拆分
create table column2row(
name string,
courses string
) row format delimited fields terminated by '\t';
load data local inpath ‘/home/hadoop/data/imooc/column2row.txt’ overwrite into table column2row;
select *, split(courses, “,”) from column2row;
UDTF
UDF: UDF UDAF UDTF
select
name, course
from
column2row
lateral view
explode(split(courses, ",")) course_tmp as course;

窗口函数概述
spark官网对窗口的介绍不多,hive官网对窗口的用法介绍比较全面,也都是可以在spark中使用的
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics




窗口函数之累计求和操作
原始数据 window01.txt

创建表


对traffic求和操作

partition by:相同的domain会划分到一起

窗口函数之窗口划分原则
规则
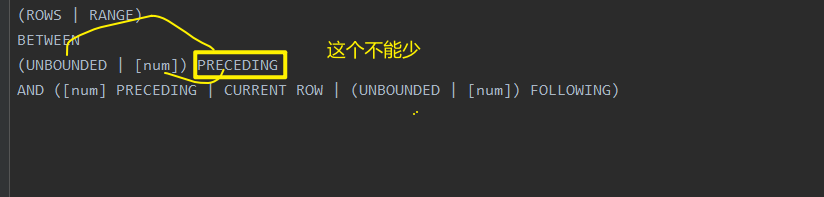
(ROWS | RANGE)
BETWEEN
(UNBOUNDED | [num]) PRECEDING
AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
select
domain, time, traffic,
sum(traffic) over(partition by domain order by time) pv1,
sum(traffic) over(partition by domain order by time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) pv2,
from
w1;
以上两句的效果一样都是统计从第一行(UNBOUNDED PRECEDING) 开始 到 当前行结束(CURRENT ROW)的结果

select
domain, time, traffic,
sum(traffic) over(partition by domain order by time) pv1,
sum(traffic) over(partition by domain order by time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) pv2,
sum(traffic) over(partition by domain order by time ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) pv3
from
w1;
pv3为分组后组内从当前行取到最后一行的和

select
domain, time, traffic,
sum(traffic) over(partition by domain order by time) pv1,
sum(traffic) over(partition by domain order by time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) pv2,
sum(traffic) over(partition by domain ) pv3,
from
w1;

select
domain, time, traffic,
sum(traffic) over(partition by domain order by time) pv1,
sum(traffic) over(partition by domain order by time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) pv2,
sum(traffic) over(partition by domain order by time ROWS BETWEEN 3 PRECEDING AND CURRENT ROW ) pv3
from
w1;
pv3 为计算分组后组内数据的当行和当前行的前三行的值

select
domain, time, traffic,
sum(traffic) over(partition by domain order by time) pv1,
sum(traffic) over(partition by domain order by time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) pv2,
sum(traffic) over(partition by domain order by time ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING ) pv3
from
w1;
pv3为分组后计算当行 + 当前行的前三行 + 当前行的后一行


窗口函数之ntile的使用
原始数据

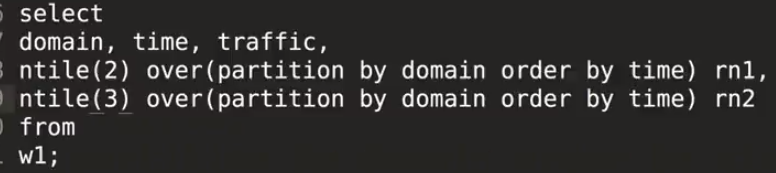


非常重要窗口函数之row_number()&rank()&dense_rank()
row_number()
row_number(): 对组内数据根据排序编号


rank()

select
domain,time,traffic,
row_number() over(partition by domain order by traffic desc) rn1,
rank() over(partition by domain order by traffic desc) rn2,
from
w1;

dense_rank()
select
domain,time,traffic,
row_number() over(partition by domain order by traffic desc) rn1,
rank() over(partition by domain order by traffic desc) rn2,
dense_rank() over(partition by domain order by traffic desc) rn2,
from
w1;

窗口函数之lag&lead(取上次&下次的值)



select
cookieid,time,
lag(time, 1,'===') over(partition by cookieidorder by timedesc) lag1,
lag(time, 2,'===') over(partition by cookieidorder by timedesc) lag2,
from
w3;


窗口函数之first_value和 last_value
first_value 分组后的第一个值
select
cokieid ,time, first
first_value() over(partition by cookieid order by time) first
from w3

first_value 分组后当前位置的最后一个值
select
cokieid ,time, first
last_value() over(partition by cookieid order by time) last
from w3

cume_dist percent_rank
窗口函数之cume_dist&percent_rank
cume_dist
建表

数据

select
dept,user,sal,
cume_dist() over(order by sal) ranl,
cume_dist() over(partition by dept order by sal)ran2
from w2;

四舍五入



percent_rank
select
dept,user,sal,
round(percent_rank() over(order by sal) ,2) ranl,
round(percent_rank() over(partition by dept order by sal),2) ran2
from w2;

窗口函数实战之数据准备
原始数据

建表


需求1: 统计2021年9月份购买过的用户以及总人数
- 先过滤出2021-09
方法1:使用字符串判断
select * from w_ordrs where substr(time,1,7)='2021-09'
查询结果

方法二使用时间函数
select * from w_ordrs where year(time)=2021 and month(time)=9;
2.获取用户的名字
select
name
from w_ordrs
where year(time)=2021 and month(time)=9
group by name
3.获取总人数
先将上面两步查到结果放入一个临时表t1
create table t1 as
select
name,
count(1) over(row between unbounded preceding and unbounded following)
from w_ordrs
where year(time)=2021 and month(time)=9
group by name

2. 统计用户的购买明细信息以及月份购买总额
根据名字和年月分组,再计算每组中cost的总和
select
name,time,cost,
sum(cost) over(partition by name, substring(time,1,7) order by time) month_cost
from w_orders;


2. 统计用户的购买明细信息以及按日期份购买总额(每个人的购买总额)
select
name,time,cost,
sum(cost) over(partition by name order by time) costs
from w_orders;

2. 统计用户的购买明细信息以及改用户上次的购买时间
select
name,time,cost,
lag(time,1,'--') over(partition by name order by time) lag
from w_orders;

2. 统计用户的购买明细信息以及改用户下次的购买时间
select
name,time,cost,
lead(time,1,'--') over(partition by name order by time) lag
from w_orders;
15 自定义函数
UDF 一进一出 User Defined Function
UDAF 多进一出(聚合函数), User Defined Aggregate Function(用户自定义聚合函数)
自定义UDF自定义函数
示例一
数据
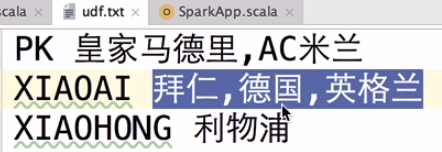

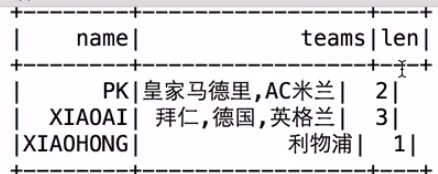
需求:自定义函数实现,统计每个人所在队的个数
SQL UDF 实现 (自定义API)
object UDFApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("UDFApp")
.getOrCreate()
udfWithSQL(spark)
spark.stop()
}
def udfWithSQL(spark: SparkSession): Unit = {
import spark.implicits._
val df: DataFrame = spark.sparkContext.textFile("data/udf.txt")
.map(_.split(" "))
.map(x => FootballTeam(x(0), x(1)))
.toDF()
df.createOrReplaceTempView("/**//")
// 注册我们自定义的Spark SQL的UDF函数
val teams_length: UserDefinedFunction = spark.udf.register("teams_length", (input: String) => {
input.split(",").length
})
spark.sql(
"""
|
|select
|name, teams, teams_length(teams) as len
|from
|teams
|
""".stripMargin)
.show()
df.select($"name", $"teams", teams_length($"teams").as("len")).show()
}
case class FootballTeam(name:String, teams: String)
}

dateStream API UDF(自定义API)

import org.apache.spark.sql.functions._
object UDFApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("UDFApp")
.getOrCreate()
// udfWithSQL(spark)
udfWithAPI(spark)
spark.stop()
}
def udfWithAPI(spark: SparkSession): Unit = {
import spark.implicits._
spark.sparkContext.textFile("data/udf.txt")
.map(_.split(" "))
.map(x => FootballTeam(x(0), x(1)))
.toDF()
.select($"name", $"teams", getTeamsLength($"teams").as("len"))
.show()
}
def getTeamsLength = udf((input: String) => {
input.split(",").length
})
case class FootballTeam(name:String, teams: String)
}
实际开中应该把udf 装在一起方便调用
示例二
package com.imooc.bigdata.udf
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
object UDFApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("UDFApp")
.getOrCreate()
// udfWithSQL(spark)
// udfWithAPI(spark)
test(spark)
spark.stop()
}
def test(spark: SparkSession): Unit = {
import spark.implicits._
val ds = spark.createDataset(List(("广东省","深圳市","南山区"),("北京市","北京市","昌平区"),("浙江省","杭州市","西湖区")))
val df = ds.toDF("province", "city", "district")
// 使用自定义函数,把每个Tuple中对应的元素拼接(???)起来,sql中其实已经提供了拼接函数 concat_ws()
def func = (split:String, p1:String, p2:String, p3:String) => {
p1 + split + p2 + split + p3
}
spark.udf.register("PK_CONCAT_WS", func)
df.createOrReplaceTempView("cities")
//SQL
spark.sql(
"""
|
|select
|PK_CONCAT_WS("|", province,city,district) province_city_district_sql
|from
|cities
|
""".stripMargin)
.show(false)
//API
df.select(expr("PK_CONCAT_WS('|', province,city,district)").as("province_city_district_api")).show()
}
}
自定义UDAF函数
示例一 分组之后求平均年龄
需求:分组之后求,每个组的平均年龄
Row 弱类型 无约束类型
package com.imooc.bigdata.udf
import org.apache.spark.sql.{DataFrame, Dataset, Encoder, Encoders, Row, SparkSession, TypedColumn}
import java.util
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
object UDAFApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("UDFApp")
.getOrCreate()
// Row 弱类型 无约束类型
test01(spark)
spark.stop()
}
// Row 弱类型 无约束类型
def test01(spark:SparkSession): Unit = {
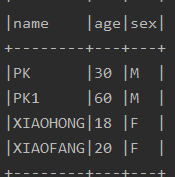
val rows = new util.ArrayList[Row]()
// 按照性别分组,求平均年龄
rows.add(Row("PK",30 ,"M"))
rows.add(Row("PK1",60 ,"M"))
rows.add(Row("XIAOHONG",18 ,"F"))
rows.add(Row("XIAOFANG",20 ,"F"))
val schema = StructType(List(
StructField("name", StringType, false),
StructField("age", IntegerType, false),
StructField("sex", StringType, false)
)
)
val df: DataFrame = spark.createDataFrame(rows, schema)
df.createOrReplaceTempView("user")
// df.show(false)
spark.udf.register("avg_udaf", new AvgUDAF)
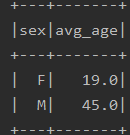
spark.sql(
"""
|
|select
|sex, avg_udaf(age) avg_age
|from
|user
|group by sex
|
""".stripMargin)
.show()
}
}
case class Student(name:String, age:Int, sex:String)
case class AgeAvg(sum:Int, count:Int) {
def avg = sum.toDouble / count
}
/**
* select sex, avg_udaf(age) from xxx group by sex;
*
* 平均数 = 总数 / 次数
*/
class AvgUDAF extends UserDefinedAggregateFunction {
// UDAF输入的数据类型
override def inputSchema: StructType = {
StructType(
StructField("nums", DoubleType, true) :: Nil
)
}
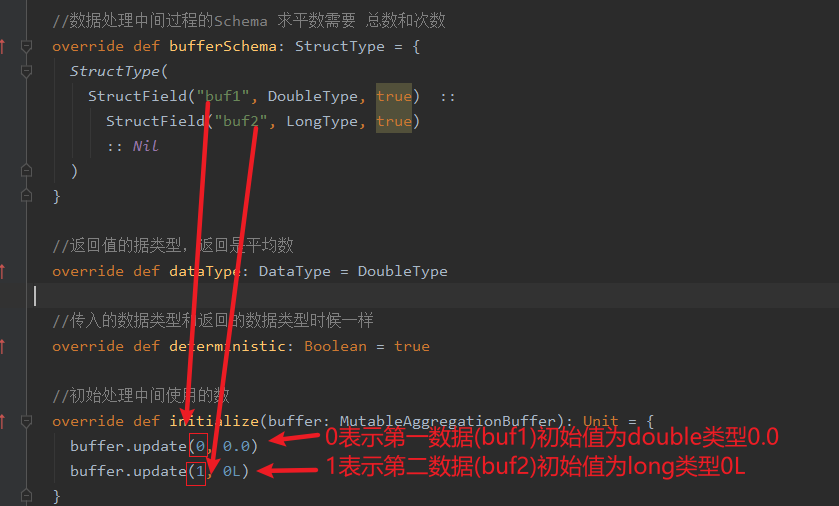
//数据处理中间过程的Schema 求平数需要 总数和次数
override def bufferSchema: StructType = {
StructType(
StructField("buf1", DoubleType, true) ::
StructField("buf2", LongType, true)
:: Nil
)
}
//返回值的据类型,返回是平均数
override def dataType: DataType = DoubleType
//传入的数据类型和返回的数据类型时候一样
override def deterministic: Boolean = true
//初始处理中间使用的数
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer.update(0, 0.0)
buffer.update(1, 0L)
}
//单分区内,新进来的数据和值进来的数据累加
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//数据相加
buffer.update(0, buffer.getDouble(0) + input.getDouble(0))
//统计次数
buffer.update(1, buffer.getLong(1) + 1)
}
//计算一般是多分区的,分区之间的数据进行聚合
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer2.getDouble(0) + buffer1.getDouble(0))
buffer1.update(1, buffer2.getLong(1) + buffer1.getLong(1))
}
//统计完数据,数据计算逻辑 这里是求平均数
override def evaluate(buffer: Row): Any = {
buffer.getDouble(0) / buffer.getLong(1)
}
}
数据
计算结果
强类型 带约束
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.functions.udaf
import org.apache.spark.sql.{Dataset, Encoders, SparkSession, TypedColumn}
object UDAFApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("UDFApp")
.getOrCreate()
test02(spark)
spark.stop()
}
// 强类型 带约束
def test02(spark: SparkSession): Unit = {
import spark.implicits._
val ds: Dataset[Student] = List(
Student("PK", 30, "M"), Student("PK1", 60, "M"),
Student("XIAOHONG", 18, "F"), Student("XIAOFANG", 12, "F")
).toDS()
ds.createOrReplaceTempView("user")
ds.show(false)
//3.0.0之后版本
spark.udf.register("avg_udaf",udaf(new AvgUDAF2))
spark.sql(
"""
|
|select
|sex, avg_udaf(age) avg_age
|from
|user
|group by sex
|
""".stripMargin)
.show()
//3.0.0之前版本
val avgUDAF = new AvgUDAF2
val value: TypedColumn[Student, Double] = avgUDAF.toColumn.name("avg_age")
val result = ds.select(value)
result.show()
}
}
case class Student(name: String, age: Int, sex: String)
case class AgeAvg(sum: Int, count: Int) {
def avg = sum.toDouble / count
}
class AvgUDAF2 extends Aggregator[Student, AgeAvg, Double] {
override def zero: AgeAvg = AgeAvg(0, 0)
override def reduce(b: AgeAvg, a: Student): AgeAvg = AgeAvg(b.sum + a.age, b.count + 1)
override def merge(b1: AgeAvg, b2: AgeAvg): AgeAvg = AgeAvg(b1.sum + b2.sum, b1.count + b2.count)
override def finish(reduction: AgeAvg): Double = reduction.avg
override def bufferEncoder: Encoder[AgeAvg] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}














 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









