







 本文介绍了针对推荐系统中负采样的改进方法,提出了一种增益调优动态负采样器。该方法通过监测期望增益的变化,有效地识别并避免假负样本,提高训练的稳定性和准确性。实验表明,这种方法能够提升推荐系统的性能,特别是在使用分组优化器的情况下,性能提升显著。
本文介绍了针对推荐系统中负采样的改进方法,提出了一种增益调优动态负采样器。该方法通过监测期望增益的变化,有效地识别并避免假负样本,提高训练的稳定性和准确性。实验表明,这种方法能够提升推荐系统的性能,特别是在使用分组优化器的情况下,性能提升显著。
《Simplify and Robustify Negative Sampling》 NIPS 2020
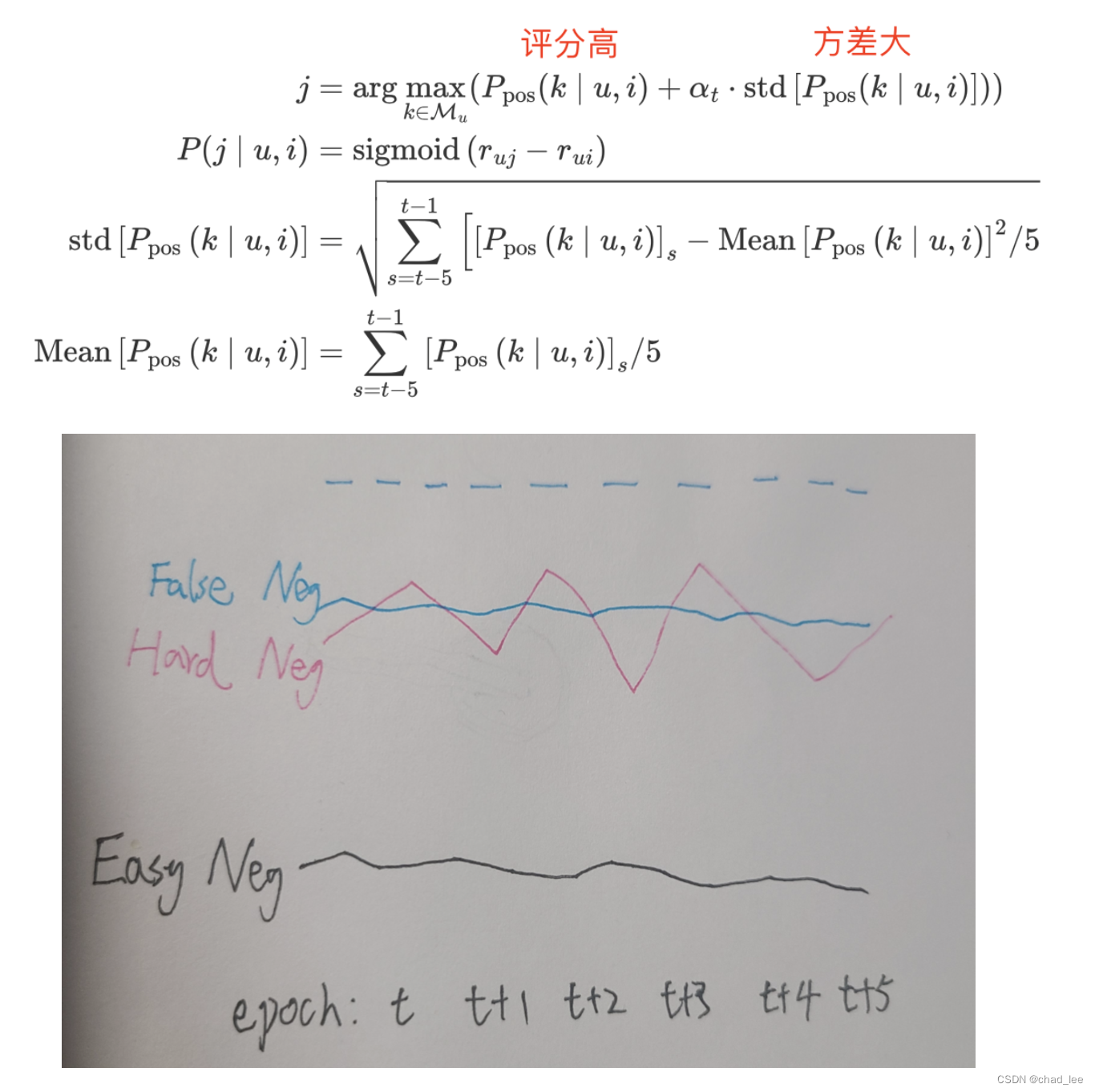
这篇文章实验观察到虽然False Negative和Hard Negative都会有较大的Socre,但是False Negative有更低的预测方差。所以提出一个Simplify and Robustify Negative Sampling方法,在训练epoch t t t 时,根据前5个epoch的训练记录,预测评分高、方差大的样本作为Hard Negative:
A Gain-Tuning Dynamic Negative Sampler for Recommendation (WWW 2022)
现有的挖掘RS难负样本的方法只想要挖掘训练过程梯度贡献大的样本(预测和标签差距大的),在RS场景中这样很容易导致选择假负样本(False Negative、missing data),从而导致过拟合训练数据集。
文章提出一个基于期望增益的采样器,在训练过程中根据正负样本之间差距的期望的变化,动态指导负采样,可以识别假负样本。
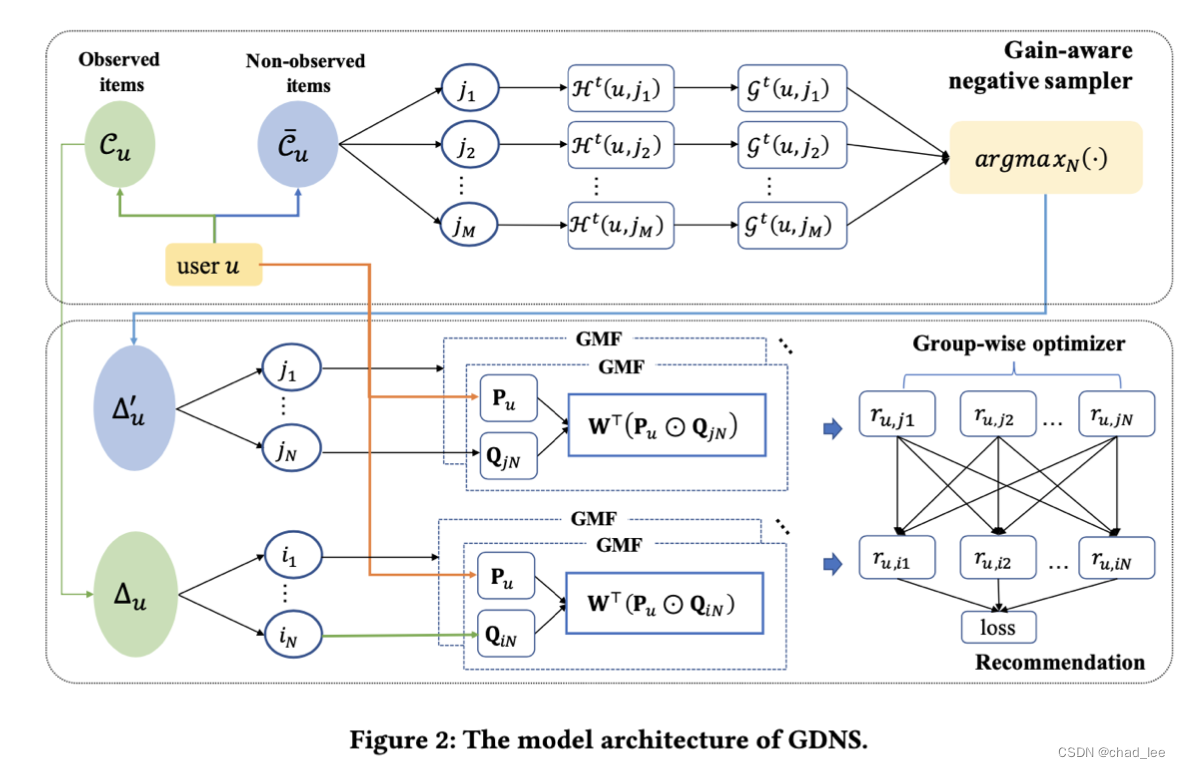
增益感知负采样器
衡量一个物品 j j j 是不是用户 u u u 的真实负样本的方法:
H t ( u , j ) = E i ∼ Δ u σ ( r u , j − r u , i ) \mathcal{H}^{t}(u, j)=\mathbb{E}_{i \sim \Delta_{u}} \sigma\left(r_{u, j}-r_{u, i}\right) Ht(u,j)=Ei∼Δuσ(ru,j−ru,i)
公式计算的是期望, t t t是训练epoch, Δ u \Delta_{u} Δu 用户交互过的物品集合, σ \sigma
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









