







 VLMo结合单双塔模型优势,采用Mixture-of-Modality-Experts(MoME)Transformer,处理多模态任务。通过模态专家分别处理视觉、语言和跨模态任务,适应检索和分类场景。预训练阶段包含图像文本对比学习、掩码语言建模和图像-文本匹配,逐步训练专家。微调阶段则根据任务类型选择单塔或双塔结构。
VLMo结合单双塔模型优势,采用Mixture-of-Modality-Experts(MoME)Transformer,处理多模态任务。通过模态专家分别处理视觉、语言和跨模态任务,适应检索和分类场景。预训练阶段包含图像文本对比学习、掩码语言建模和图像-文本匹配,逐步训练专家。微调阶段则根据任务类型选择单塔或双塔结构。
之前在秋招和写毕业论文,一个月没更了。毕业论文交了,开更。
《VLMo: Unifified Vision-Language Pre-Training with Mixture-of-Modality-Experts》
多模态的单双塔困境
在多模态工作中存在两类主流方法,分别是双塔模型和单塔模型。
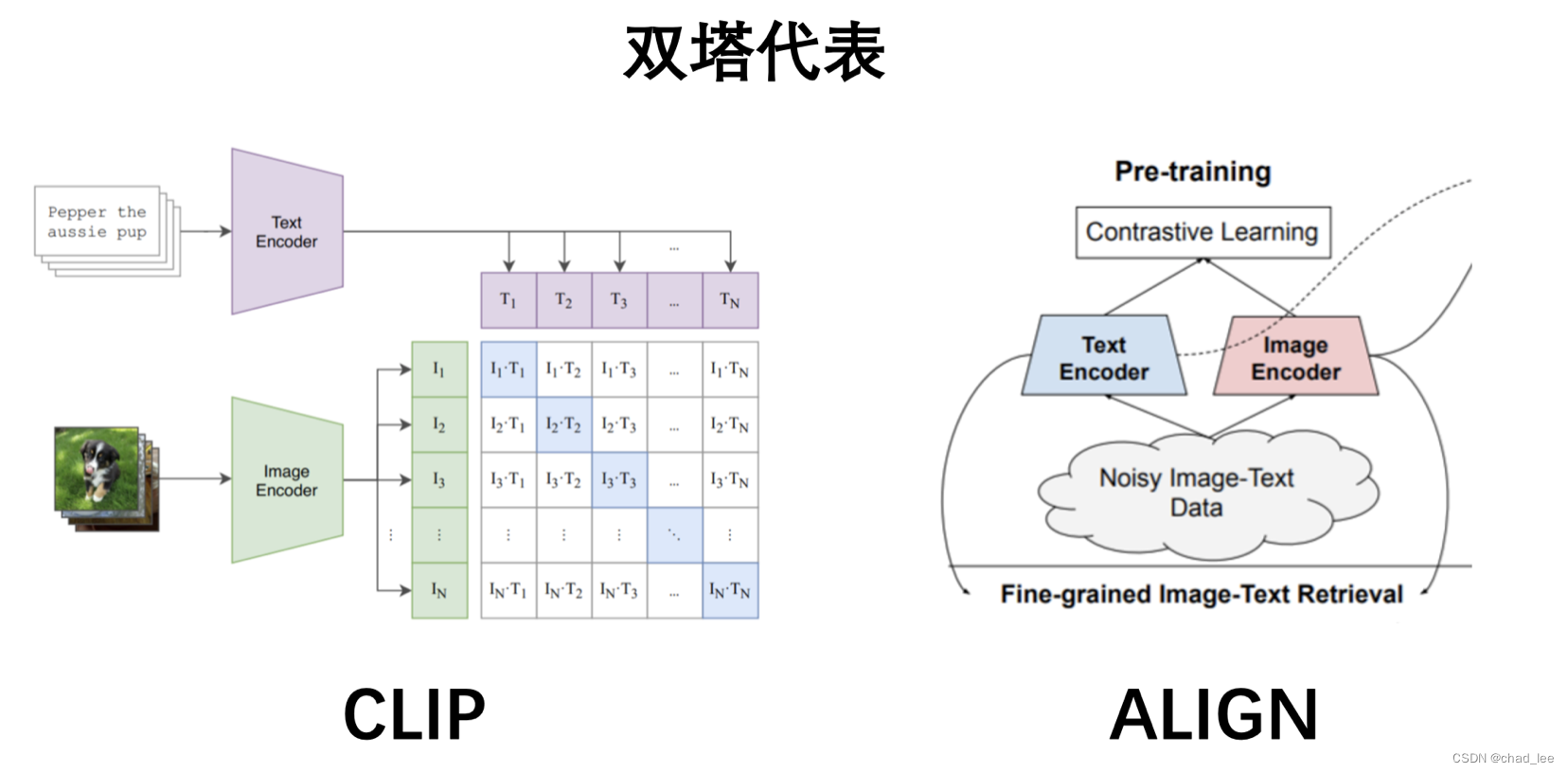
双塔模型以CLIP和ALIGN为代表,这类方法对文本和图像分别用一个编码器进行编码,然后计算两个模态的embedding的相似度。这类方法的优点是适合检索任务,可以检索大量的文本与图像,缺点是仅在塔顶的相似度loss交互信息有限,不足以处理复杂的VL分类任务。比如CLIP在视觉推理任务上的准确度较低。

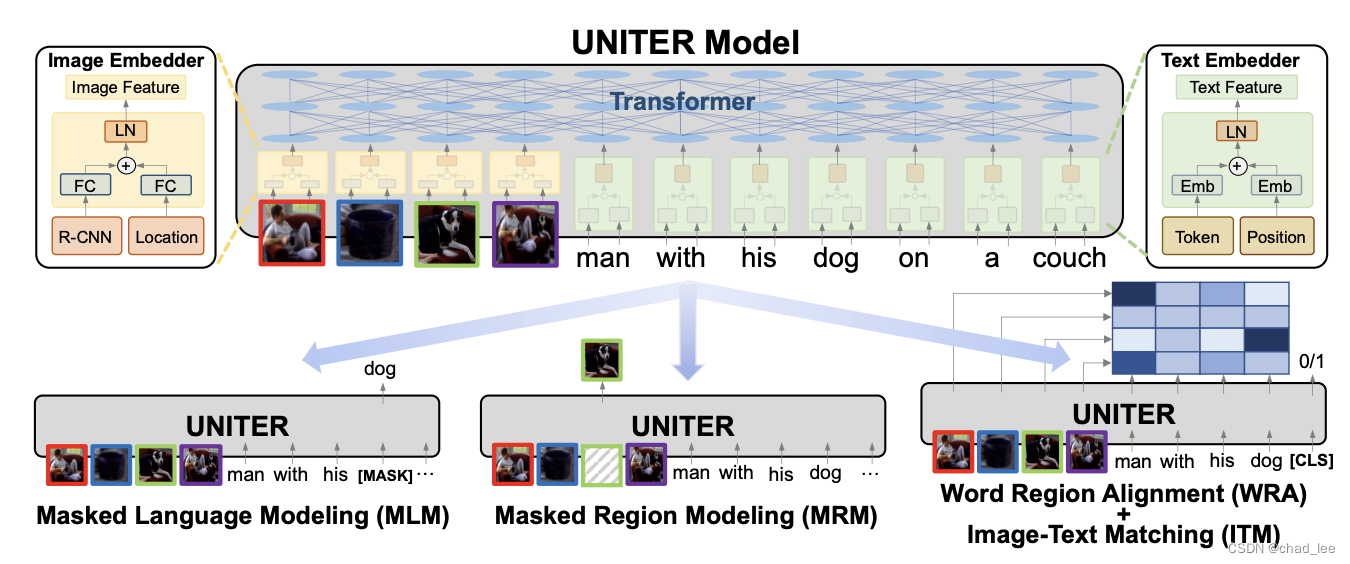
单塔模型以ViLT为代表,这类模型的优点是可以充分地将多模态的信息融合,更擅长分类任务,这种模型架构天然不适合检索,因为没有显示的对齐操作,只能用 【CLS】 的输出匹配 or 不匹配。利用这种模型架构做检索任务,需要encode所有的文本-图像对,时间复杂度是 O ( N 2 ) O(N^2) O(N2) 的。
下图是ViLT的模型架构,有三个预训练任务,分别是图像文本匹配、MLM和单词-图像区域对齐(WPA)。
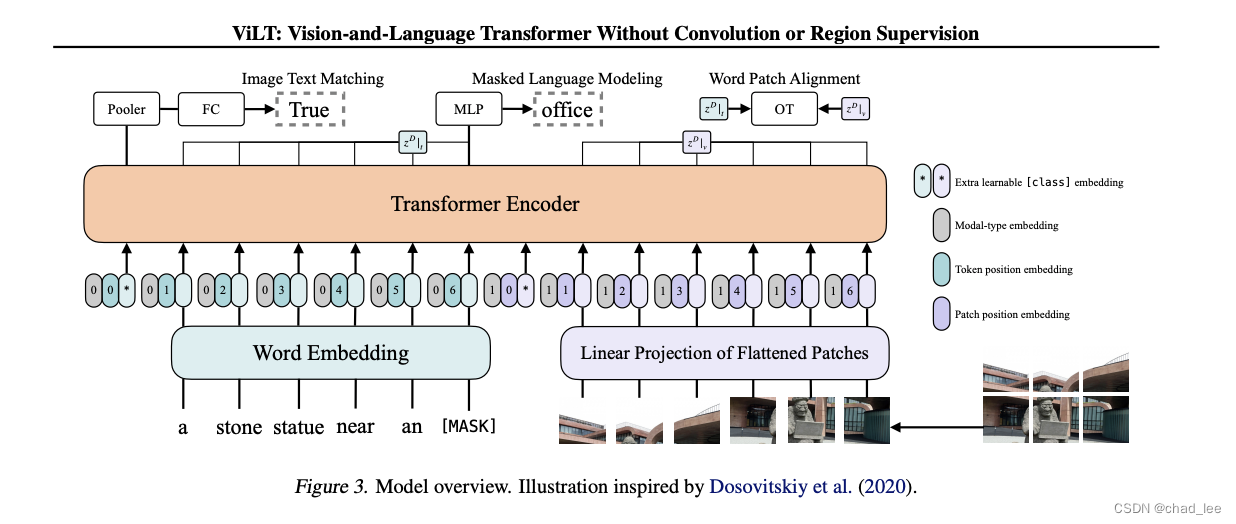
其中 Word Patch Alignment是 UNITER 这篇中提出的方法,WPA 是利用最优传输(OT)的形式完成的。
对比推荐的单双塔
这里可以联系推荐场景,召回模型通常是作用在 亿级别的,需要快速匹配,因此通常是双塔模型,用户和物品不存在特征交互,只在塔顶相遇进行相似度匹配。
精排阶段通常是作用在千级别,需要进行充分的特征交互挖掘,深度的特征交互有助于更准确的推荐,这个是推荐经典的理论。
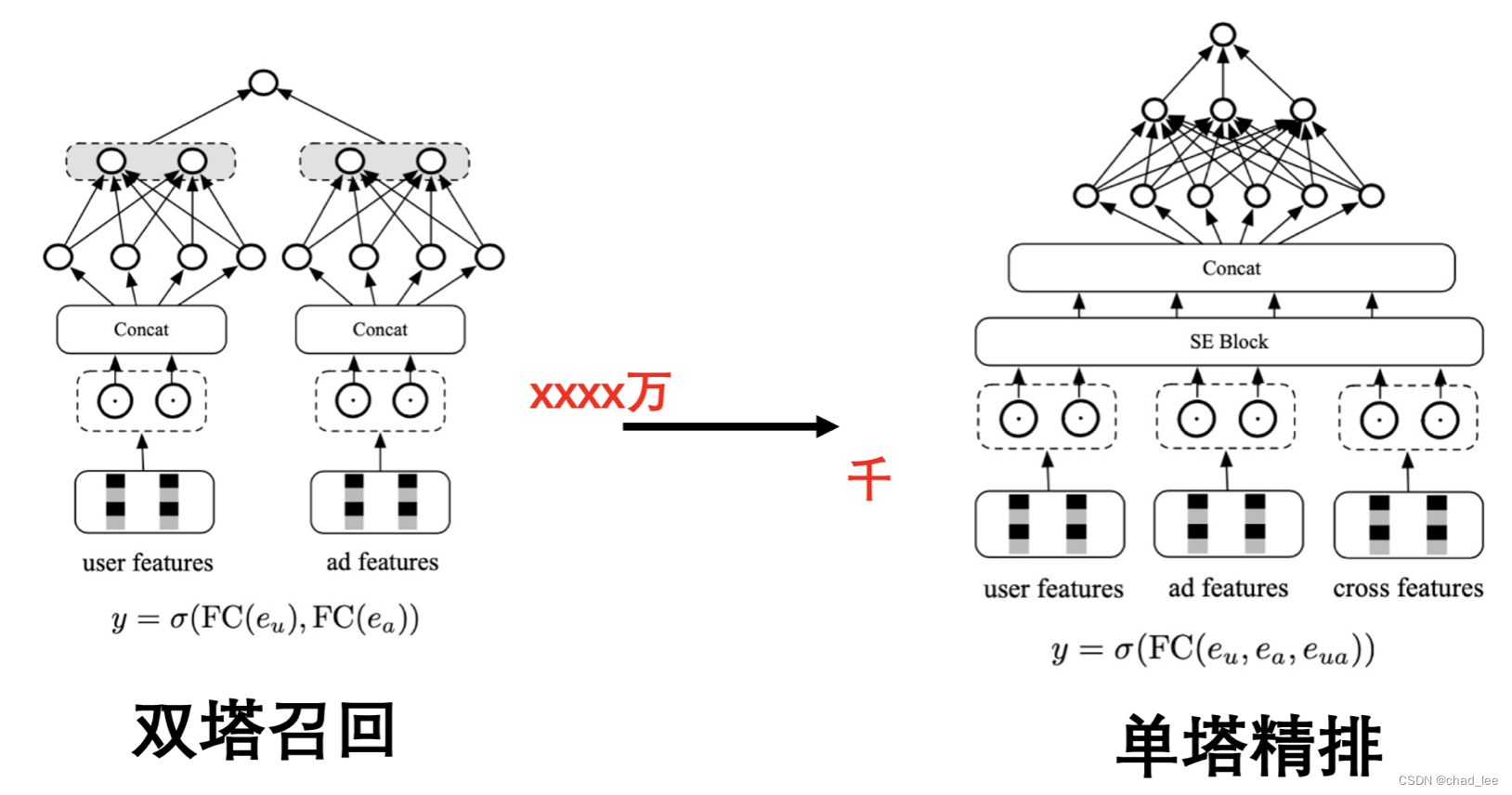
所以可以帮助我们理解多模态里的单塔双塔困境。
VLMo——MoE解决单双塔问题
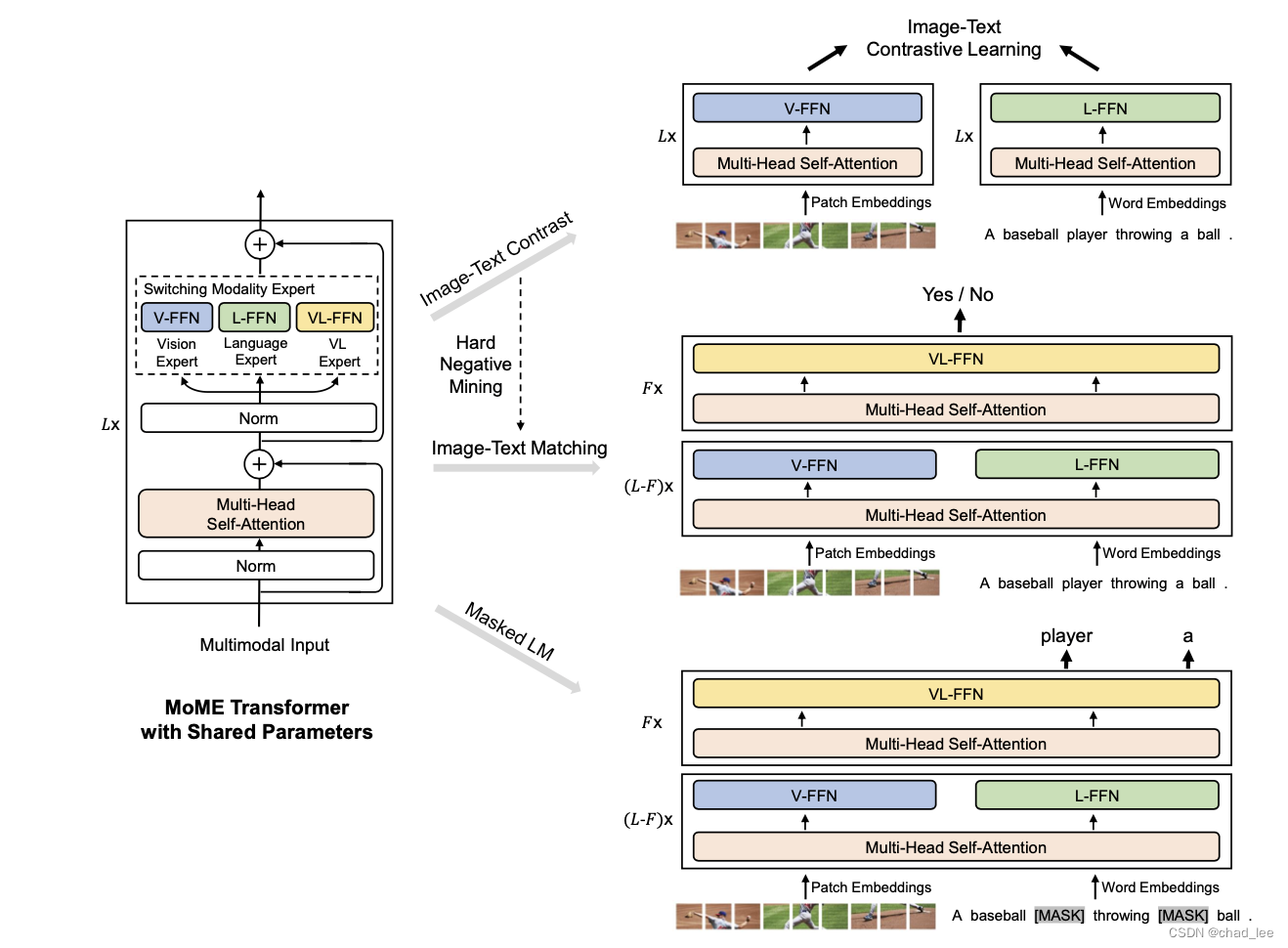
这篇文章希望融合这两个架构的优点,提出VLMo希望既可以作为双编码器(双塔)去做检索任务,也可以作为融合编码器(单塔)。VLMo利用了一个古老的模型结构 混合专家,VLMo的核心结构是 Mixture-of-Modality-Experts(MOME) Transformer,简而言之是将 Transformer中的FFN前馈网络替换成了针对不同任务的网络,称之为模态专家。每个专家拥有特定任务的知识,处理具体任务时切换到相应的专家。
下面来看具体方法。VLMo的整体结构和训练流程如下。左边是VLMo的结构,右边是按顺序的三个预训练任务。
Input Representations
图片和文本要变成embedding才能输入进VLMo。所以首先是如何生成embedding。
- 图像表示:二维图像 v ∈ R H × W × C v \in \mathbb{R}^{H \times W \times C} v∈RH×W×C 分割成 N = H W / P 2 N=H W / P^2 N=HW/P2 个patch, v p ∈ R N × ( P 2 C ) v^p \in \mathbb{R}^{N \times\left(P^2 C\right)} vp∈RN×(P2C),C 是图片的通道数。将图片patch展开拉成向量,并通过线性变换的到patch embedding。还要再准备一个图片的【CLS】token。再加上一维position emb和type emb得到图像的最终输入:
V type ∈ R D : H 0 v = [ v [ I 1 CLS ] , V v i p , … , V v N p ] + V pos + V type \boldsymbol{V}_{\text {type }} \in \mathbb{R}^D: \boldsymbol{H}_0^v=\left[\boldsymbol{v}_{\left[I_1 \text { CLS }\right]}, \boldsymbol{V} \boldsymbol{v}_i^p, \ldots, \boldsymbol{V} \boldsymbol{v}_N^p\right]+\boldsymbol{V}_{\text {pos }}+\boldsymbol{V}_{\text {type }} Vtype ∈RD:H0v=[v[I1 CLS ],Vvip,…,V
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1591
1591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









