







文章目录
大数据相关工具
DataX数据同步工具
- DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具,致力于实现包括:关系型数据库(MySQL、Oracle等)、HDFS、Hive、HBase、ODPS、FTP等各种异构数据源之间稳定高效的数据同步功能。

- 设计理念:为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
- 当前使用现状:DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX 3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX

DataX 3.0架构设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:数据采集模块,负责采集数据源的数据,将数据发送给 Framework。
- Writer:数据写入模块,负责不断向 Framework 取数据,并将数据写入到目的端。
- Framework:用于连接 Reader 和 Writer,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题。

DataX 3.0 插件体系
- 经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:https://github.com/alibaba/DataX

DataX 3.0 核心架构
- DataX 3.0 支持单机多线程模式完成数据同步作业,下面从整体架构设计简要说明DataX各个模块之间的相互关系。

1. 核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataX Job启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用 Scheduler 模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。
2. DataX调度流程
- 举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,默认单个任务组的并发数量为5,DataX计算共需要分配4个TaskGroup。
- 这里4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
DataX 安装部署
-
安装前置要求:linux、jdk1.8+、python2.6+
-
官网下载安装包:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
-
上传安装包到服务器 node01 节点,解压安装
scp datax.tar.gz hadoop@node01:/bigdata/soft
# 解压
tar -zxvf datax.tar.gz -C /bigdata/install/
# 配置环境变量
sudo vim /etc/profile
export DATAX_HOME=/bigdata/install/datax
export PATH=$PATH:$DATAX_HOME/bin
source /etc/profile
# 运行自检脚本测试
datax.py /bigdata/install/datax/job/job.json

DataX 实战案例
1. 从stream流读取数据并打印到控制台
- 需求:使用datax实现读取字符串,然后打印到控制台。
- 第一步:开发作业配置文件(json格式)
- 可以通过命令查看配置模板:
python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
- 可以通过命令查看配置模板:

- 根据模板编写配置文件
vim stream2stream.json文件内容如下:-
其中
sliceRecordCount表示每个channel生成数据的条数。 -
speed表示限速channel表示任务并发数。bytes表示每秒字节数,默认为0(不限速)。
-
errorLimit表示错误控制record: 出错记录数超过record设置的条数时,任务标记为失败percentage: 当出错记录数超过percentage百分数时,任务标记为失败
-
{
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}],
"setting": {
"speed": {
"channel": 5,
"bytes": 0
},
"errorLimit": {
"record": 10,
"percentage": 0.02
}
}
}
}
- 第二步:启动 DataX,查看结果输出
datax.py job/stream2stream.json

2. 从mysql表读取数据并打印到控制台
- 需求:使用datax实现读取mysql一张表指定字段的数据,打印到控制台
- MySQL 数据准备
create database datax;
use datax;
create table student(id int,name varchar(20),age int,createtime timestamp );
insert into `student` (`id`, `name`, `age`, `createtime`) values('1','zhangsan','18','2021-05-10 18:10:00'), ('2','lisi','28','2021-05-10 19:10:00'), ('3','wangwu','38','2021-05-10 20:10:00');
- 开发作业的配置文件(json格式),使用如下命令查看配置模板,其中
mysqlreader插件文档:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
python bin/datax.py -r mysqlreader -w streamwriter

- 根据模板编写配置文件,
vim job/mysql2stream.json,内容如下:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"createtime"
],
"connection": [{
"table": [
"student"
],
"jdbcUrl": ["jdbc:mysql://node01:3306/datax"]
}]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}]
}
}
- 启动 DataX,查看结果输出
datax.py job/mysql2stream.json

3. 从mysql表读取增量数据并打印到控制台
- 需求:使用datax实现mysql表增量数据同步打印到控制台。
- 开发作业配置文件,
vim job/mysqlAdd2stream.json,文件内容如下:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 10,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"createtime"
],
"where": "createtime > '${start_time}' and createtime < '${end_time}'",
"connection": [{
"table": [
"student"
],
"jdbcUrl": ["jdbc:mysql://node01:3306/datax"]
}]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}]
}
}
- 向
student表中插入一条数据
insert into `student` (`id`, `name`, `age`, `createtime`) values('4','xiaoming','48','2021-05-11 19:10:00')
- 启动 DataX,查看结果输出
datax.py job/mysqlAdd2stream.json -p "-Dstart_time='2021-05-11 00:00:00' -Dend_time='2021-05-11 23:59:59'"

4. 使用datax实现mysql2mysql
- 需求:使用datax实现将数据从mysql当中读取,并且通过sql语句实现数据的过滤,并且将数据写入到mysql另外一张表当中去。
- 开发作业配置文件(json格式),使用如下命令查看配置模板
python bin/datax.py -r mysqlreader -w mysqlwriter

- 根据模板编写配置文件,
vim job/mysql2mysql.json,文件内容如下:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [{
"querySql": [
"select id,name,age,createtime from student where age < 30;"
],
"jdbcUrl": [
"jdbc:mysql://node01:3306/datax"
]
}]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"createtime"
],
"preSql": [
"delete from person"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://node01:3306/datax?useUnicode=true&characterEncoding=utf-8",
"table": [
"person"
]
}]
}
}
}]
}
}
- 创建需要写入数据的目标表
create table datax.person(id int,name varchar(20),age int,createtime timestamp );
- 启动 DataX,查看结果输出
datax.py job/mysql2mysql.json

5. 使用datax实现将mysql数据导入到hdfs
-
需求:将mysql表
student的数据导入到hdfs的/datax/mysql2hdfs/路径下面去。 -
开发作业配置文件(json格式),使用如下命令查看配置模板,其中
hdfswriter插件文档:https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
python bin/datax.py -r mysqlreader -w hdfswriter

- 根据模板编写配置文件,
vim job/mysql2hdfs.json,内容如下:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [{
"querySql": [
"select id,name,age,createtime from student where age < 30;"
],
"jdbcUrl": [
"jdbc:mysql://node01:3306/datax"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://node01:8020",
"fileType": "text",
"path": "/datax/mysql2hdfs/",
"fileName": "student.txt",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "INT"
},
{
"name": "createtime",
"type": "TIMESTAMP"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
- HDFS 创建目标路径
hdfs dfs -mkdir -p /datax/mysql2hdfs
- 启动 DataX,查看结果输出
datax.py job/mysql2hdfs.json
- 查看HDFS上文件生成

6. 使用datax实现将hdfs数据导入到mysql表中
-
需求:将hdfs上数据文件
user.txt导入到mysql数据库的user表中。 -
开发作业配置文件(json格式),执行如下命令查看配置模板,其中
hdfsreader插件文档:https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md
datax.py -r hdfsreader -w mysqlwriter

- 根据模板编写配置文件,
vim job/hdfs2mysql.json,文件内容如下:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://node01:8020",
"path": "/user.txt",
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"column": [{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "long"
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age"
],
"preSql": [
"delete from user"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://node01:3306/datax?useUnicode=true&characterEncoding=utf-8",
"table": [
"user"
]
}]
}
}
}]
}
}
- 准备HDFS上测试数据文件
user.txt,文件内容如下
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 35
5 kobe 40
- 上传文件到hdfs上:
hdfs dfs -put user.txt /
- 创建目标表
create table datax.user(id int,name varchar(20),age int);
- 启动 DataX,查看结果输出
datax.py job/hdfs2mysql.json
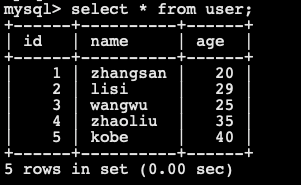
- 查看
user表数据
7. 使用datax实现将mysql数据同步到hive表中
- 需求:使用datax将mysql中的
user表数据全部同步到hive表中 - 启动 hiveserver2,创建一张hive表
hiveserver2
# 通过beeline连接hiveserver2
[hadoop@centos132 logs]$ beeline
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://node03:10000
Connecting to jdbc:hive2://node03:10000
Enter username for jdbc:hive2://node03:10000: hadoop
Enter password for jdbc:hive2://node03:10000: ******
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node03:10000> create database datax;
0: jdbc:hive2://node03:10000> use datax;
No rows affected (0.13 seconds)
0: jdbc:hive2://node03:10000> create external table t_user(id int,name string,age int) row format delimited fields terminated by '\t';
0: jdbc:hive2://node03:10000>
- 编写配置文件,
vim job/mysql2hive.json,文件内容如下:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [{
"jdbcUrl": [
"jdbc:mysql://node01:3306/datax"
],
"table": [
"user"
]
}],
"column": [
"id",
"name",
"age"
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://node01:8020",
"fileType": "text",
"path": "/user/hive/warehouse/datax.db/t_user",
"fileName": "user.txt",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "INT"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
- 启动 DataX,查看结果输出
datax.py job/mysql2hive.json
- 查看hive中
t_user表数据

















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











