







 本文深入探讨Pandas库中的数据切片方法,包括loc、iloc、at、iat、ix及dataframe[]的使用技巧与区别,通过实例展示如何高效查询和操作数据。
本文深入探讨Pandas库中的数据切片方法,包括loc、iloc、at、iat、ix及dataframe[]的使用技巧与区别,通过实例展示如何高效查询和操作数据。
上篇文章介绍了Panda的一些常用的方法,发现用法实在太多,无法一一列举,其实多用几次就发现Pandas的数据切片方法是有使用规律的。数据切片方面常用的方法有loc,iloc,at,iat,ix,dataframe[],这几个方法有很多相似之处。我们来区分一下:
首先我们来造一批测试数据
df=pd.DataFrame(np.arange(42).reshape(7,6),columns=list('abcdefg'),index=list('hijklm'))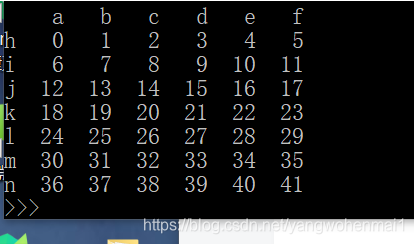
loc只能根据行/列名查询
df.loc[:,:] #所有数据
df.loc['h','a'] #h行a列
df.loc[['h','k'],['c','d']] #h,k行的c,d列
df.loc['h':'k','c':'d'] #h~k行的c~d列iloc只能根据行/列索引查询
df.iloc[:,:] # 显示所有数据
df.iloc[1,1] #显示第一行第一列的数字
df.iloc[[1,3],[1,3]] # 显示1,3行的1,3列数字
df.iloc[1:3,1:3] # 显示1~3行的1~3列数字at只能根据行/列名查询
at['a','c'] # 显示a行c列的数字iat只能根据行/列索引查询
iat[1,1] # 显示第1行1列的数字这里有一个坑,有时候我们发现下面这几种形式竟然也可以查询
loc[1:3,['c','d']]
loc[[1,3],['c','d']]
loc[[1,3],[2:3]
at[2,'c']
at[2,2]
不是说好的.loc和.at只能按照列名查询,为什么也能用索引呢?
并非如此,谁告诉你行名称或者列名称不能是数字了?其实这种写法是因为定义DataFrame结构的时候,把行或者列名定义成了数字,而数字不用加引号,所以看起来好像是用了索引一样,其实loc和at用的仍然是行/列名查找。
dataframe[]只能单独查询行或者列,不能行和列混合查询
df[:] # 取所有数据
df[1:3] # 取1~3行数据
df['a'] # 取'a'列数据
df[['a','b']] #取'a','b'两列数据
df['a'][2] # 取'a'列数据的第二行ix既能通过索引查询,又能通过行列名进行查询
.ix具备.loc,.iloc,.at,.iat,dataframe[]的所有功能,就不再过多介绍,总之就是.loc,.iloc,.at,.iat,dataframe的语法他都能用
df.ix['i':'l','a':'d']
df.ix[['i','h'],['a','d']]
df.ix[1:3,2:4]
df.ix[[1,3],[2,4]]
df.ix[:,:]因此在平时使用中,用ix无疑是最好的选择了


















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











