







说明:此文主要参考52nlp-中英文维基百科语料上的Word2Vec实验,按照上面的步骤来做的,略有改动,因此不完全是转载的。这里,为了方便大家可以更快地运行gensim中的word2vec模型,我提供了wiki.zh.text.model、wiki.zh.text.model.syn1neg.npy、wiki.zh.text.model.syn0.npy 、wiki.zh.text.vector的下载链接,链接地址是:http://download.csdn.net/detail/yangyangrenren/9859895
(说明)由于csdn上传的文件大小有限制,此链接里面的文件提供了百度网盘的下载链接,全部的四个文件都是包含有的,假设网盘链接失效了,请留言,我再重新上传一下。
无意看到52nlp上面的一篇博文“中英文维基百科语料上的Word2Vec实验”,吸引了我,因此也动手尝试了一下。我仅仅主要使用python的gensim包在中文维基百科语料上训练word2vec模型。
1.语料下载与格式转换
从网址https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2下载维基百科语料库,得到文件zhwiki-latest-pages-articles.xml.bz2,文件大小是1.4G。
新建文件process_wiki.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import logging
import os.path
import sys
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 3:
print (globals()['__doc__'] % locals())
sys.exit(1)
inp, outp = sys.argv[1:3]
space = " "
i = 0
output = open(outp, 'w')
wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
for text in wiki.get_texts():
output.write(space.join(text) + "\n")
i = i + 1
if (i % 10000 == 0):
logger.info("Saved " + str(i) + " articles")
output.close()
logger.info("Finished Saved " + str(i) + " articles")1.1将压缩文件转为文本文件
处理xml.bz2文件,将其转换为text文本文档,用下面命令(可以将python3改为python,具体视电脑安装环境)
python3 process_wiki.py zhwiki-latest-pages-articles.xml.bz2 wiki.zh.text
会报错提示 ImportError: No module named ‘gensim’
安装gensim:pip install -U gensim,再次运行python3 process_wiki.py zhwiki-latest-pages-articles.xml.bz2 wiki.zh.text,,最终有280819articles,得到的wiki.zh.text文件大小是968.8MB;
1.2繁体字转为简体字
ubuntu中安装opencc
sudo apt-get install opencc
然后将wiki.zh.text中的繁体字转化位简体字:
opencc -i wiki.zh.text -o wiki.zh.text.jian -c zht2zhs.ini
说明zht2zhs.ini 是转换方式,默认的是zhs2zht.ini,即简体字转为繁体字。
1.3字符集转换为utf-8
由于后续的分词需要使用utf-8格式的字符,而上述简体字中可能存在非utf-8的字符集,避免在分词时候进行到一半而出现错误,因此先进行字符格式转换。
使用iconv命令将所有字符集转换为utf8格式
iconv -c -t UTF-8 < wiki.zh.text.jian> wiki.zh.text.jian.utf-8
2.分词
我使用Stanford Segmenter进行分词,分词过程一共消耗4.5小时。我的电脑配置是i5处理器,双核四线程,12G内存,普通机械硬盘。繁体字转简体字,以及字符集转换,文件的大小都没有变化,分词之后由968.8MB变成1.1GB。使用Stanford Segmenter,在eclipse中操作,分词之后输出的结果是:
testFile=/home/username/Documents/wiki.zh.text.jian.utf-8
serDictionary=data/dict-chris6.ser.gz
sighanCorporaDict=data
inputEncoding=UTF-8
sighanPostProcessing=true
Loading Chinese dictionaries from 1 file:
data/dict-chris6.ser.gz
Done. Unique words in ChineseDictionary is: 429478.
Loading classifier from data/ctb.gz ... done [14.9 sec].
Loading character dictionary file from data/dict/character_list [done].
Loading affix dictionary from data/dict/in.ctb [done].
CRFClassifier tagged 349762918 words in 280819 documents at 21809.35 words per second.如果对于分词不太熟悉,就可以参考我的以前的一篇博客stanford-segmenter中文分词基本使用
将SegDemo.java中的第一句改为了
System.setOut(new PrintStream(new FileOutputStream("/home/username/Documents/wiki.zh.text.jian.utf-8.seg")));使得直接输出到文件,而不是输出到显示器
3.训练模型
train_word2vec_model.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 4:
print (globals()['__doc__'] % locals())
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5,
workers=multiprocessing.cpu_count())
# trim unneeded model memory = use(much) less RAM
#model.init_sims(replace=True)
model.save(outp1)
model.save_word2vec_format(outp2, binary=False)执行下面代码
python train_word2vec_model.py wiki.zh.text.jian.utf-8.seg wiki.zh.text.model wiki.zh.text.vector运行成功之后,会产生这几个文件
wiki.zh.text.model ; wiki.zh.text.model.syn0.npy ; wiki.zh.text.model.syn1neg.npy ; wiki.zh.text.vector
4.运行
然后执行,执行的代码直接看图,可以得到这样的结果:
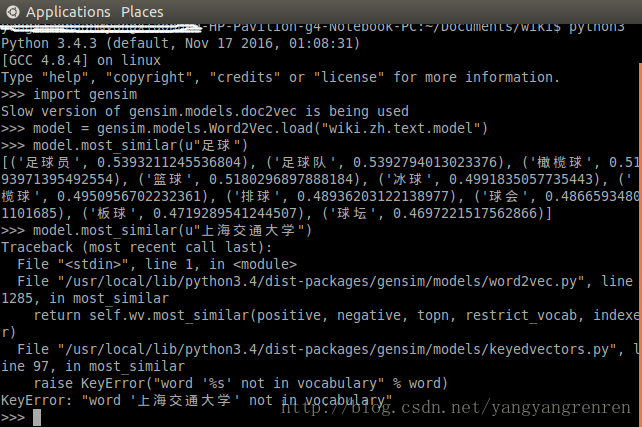
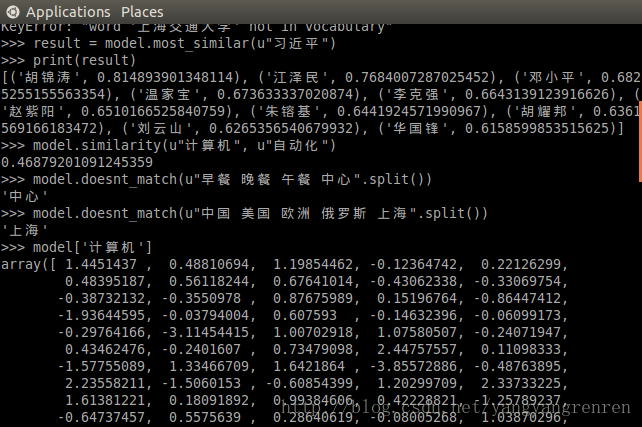
可以看到,对于“上海交通大学”这个词,用model.most_similar(u’上海交通大学’)进行查找相似词,会报错,错误提示“上海交通大学”不在词汇表里面。
假设直接在终端运行,没有显示出汉字,而是显示字符编码,那么可以采用这种形式查看输出结果
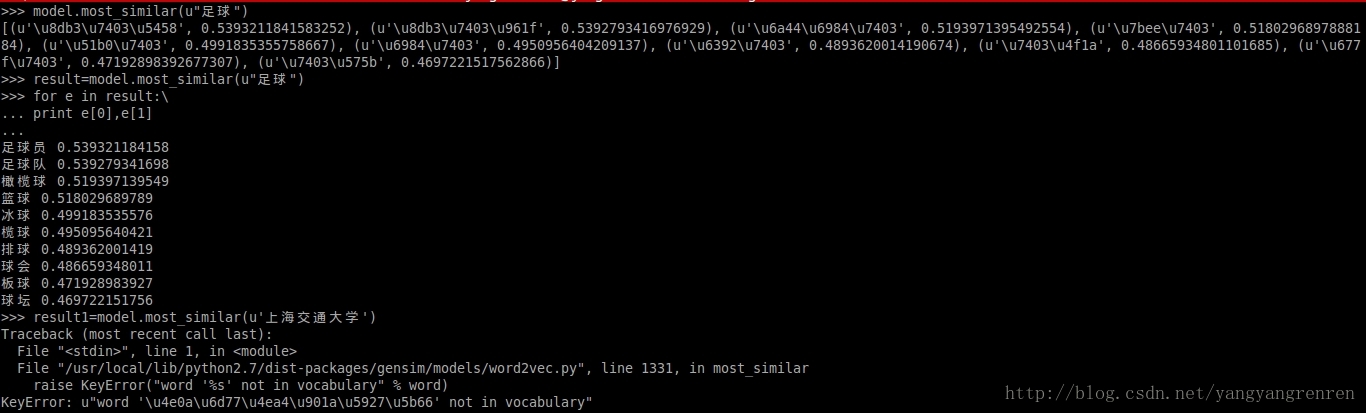
5.备忘
Gensim is a free Python library designed to automatically extract semantic topics from documents, as efficiently (computer-wise) and painlessly (human-wise) as possible.
另外Python gensim包自带word2vec这个神器。不过gensim中的word2vec不是用神经网络,而是词袋模型。
word2vec作为google的一个开源工具,比较强大,效果也比较好,便试试。
其他下载地址(未进行验证,参考网址1)
Wikimedia Downloads
https://dumps.wikimedia.org/
Wikipedia数据库下载链接,中文版:
http://download.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-meta-history.xml.bz2(全版),http://download.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2(阉割版)。
英文版:
http://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-meta-current.xml.bz2(全版),http://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2(阉割版)。
Wikitaxi下载地址:
http://www.wikitaxi.org/delphi/doku.php/products/wikitaxi/index。
6.转载于 中英文维基百科语料上的Word2Vec实验
7.参考网址
(1).http://venhow.blog.163.com/blog/static/166701448201110254515515/
(2).gensim的官网介绍
http://radimrehurek.com/gensim/intro.html
8.还没有完全搞清楚的
(1).从网址下载下来的维基语料,是xml.bz2格式的,解压之后,就是xml文档,但是不清楚为什么直接查看xml数据,是下面这样的
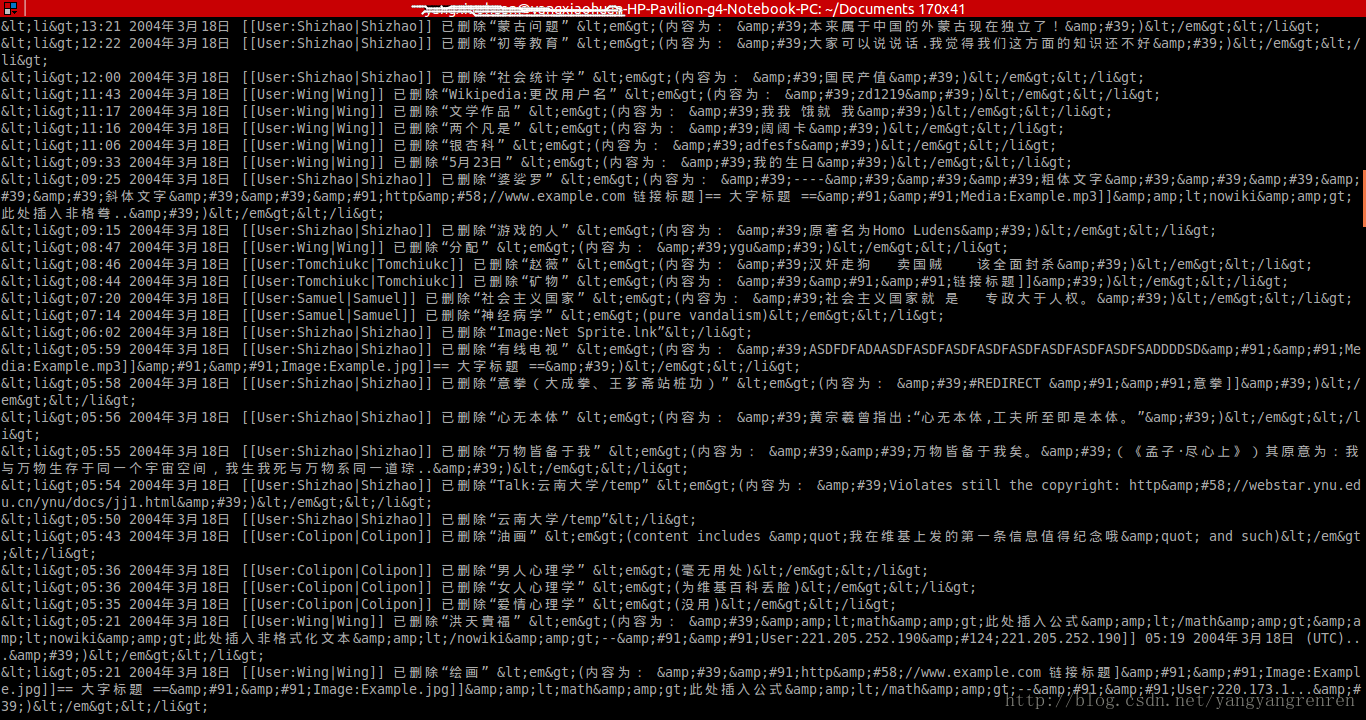
反而对xml.bz2文件直接进行处理,得到的是正常的文档。估计跟process_wiki.py源码有关系。
(2)我在第3步训练模型过程中,由于程序在开始运行时候,就有warning信息:C extension not loaded for Word2Vec, training will be slow. Install a C compiler and reinstall gensim for fast training。开始时候没管它,可是等了五六个小时之后,居然提示显示只是运行0.11%,粗略估计以下,假设全部跑完,不得四五千小时,太慢了。故需要先解决Word2Vec运行慢的问题,然后再运行。我自己的本地电脑没有解决提示的warning信息,然后放到服务器上面运行,就得到了模型与向量。















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









