






目录
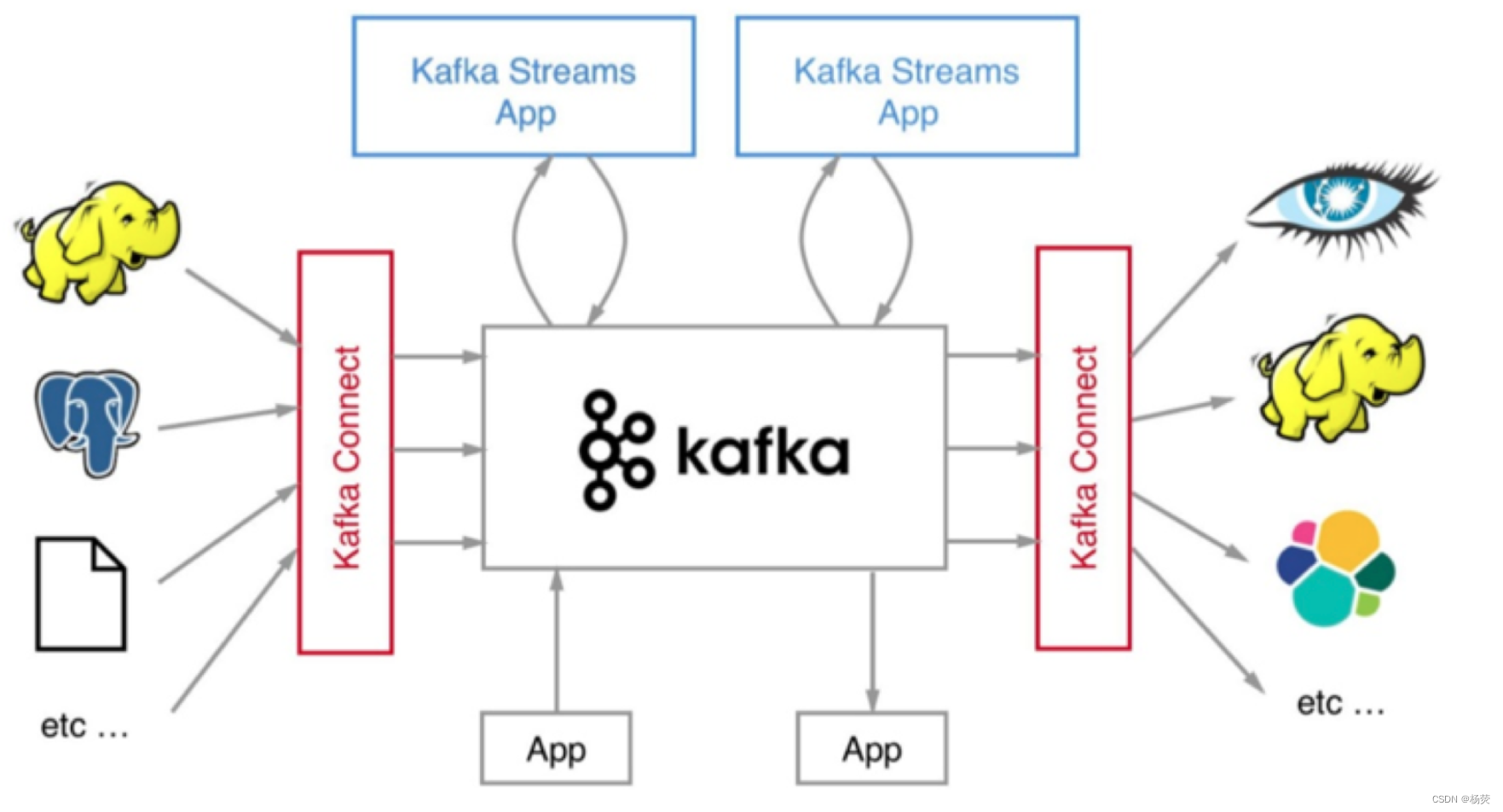
一、发布-订阅模式
发布-订阅模式是最常见的消息传递模式,其中消息发布者将消息发送到一个或多个主题(Topic),而订阅者可以选择订阅一个或多个主题来接收消息。每个订阅者都可以独立地消费消息,而发布者和订阅者之间没有直接的联系。
在Kafka中,使用KafkaProducer类进行消息发布,KafkaConsumer类进行消息订阅。以下是一个简单的Java代码示例:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Properties;
public class PubSubExample {
private static final String TOPIC = "my_topic";
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
// Kafka Producer
Properties producerProps = new Properties();
producerProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
producerProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producerProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProps);
// Publish messages
for (int i = 0; i < 10; i++) {
String message = "Message " + i;
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, message);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("Error publishing message: " + exception.getMessage());
} else {
System.out.println("Message published successfully: " + metadata.offset());
}
}
});
}
producer.close();
// Kafka Consumer
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
consumerProps.put(ConsumerConfig.GROUP_ID_CONFIG, "my_consumer_group");
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList(TOPIC));
// Consume messages
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: " + record.value());
// Process the message
}
}
}
}
二、点对点模式
点对点模式中,消息发送者将消息发送到一个指定的队列(Queue),而消息接收者从相同的队列中接收消息。每个消息只能被一个接收者消费。
在Kafka中,点对点模式可以通过创建单个消费者组来实现。以下是一个简单的Java代码示例:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Properties;
public class PointToPointExample {
private static final String QUEUE = "my_queue";
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
// Kafka Producer
Properties producerProps = new Properties();
producerProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
producerProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producerProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProps);
// Publish messages
for (int i = 0; i < 10; i++) {
String message = "Message " + i;
ProducerRecord<String, String> record = new ProducerRecord<>(QUEUE, message);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("Error publishing message: " + exception.getMessage());
} else {
System.out.println("Message published successfully: " + metadata.offset());
}
}
});
}
producer.close();
// Kafka Consumer
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
consumerProps.put(ConsumerConfig.GROUP_ID_CONFIG, "my_consumer_group");
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList(QUEUE));
// Consume messages
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: " + record.value());
// Process the message
consumer.commitAsync();
}
}
}
}以上代码示例演示了如何使用Kafka的Java客户端库进行发布和订阅消息以及点对点消息传递。请注意,代码中的BOOTSTRAP_SERVERS需要根据你的实际环境进行配置。
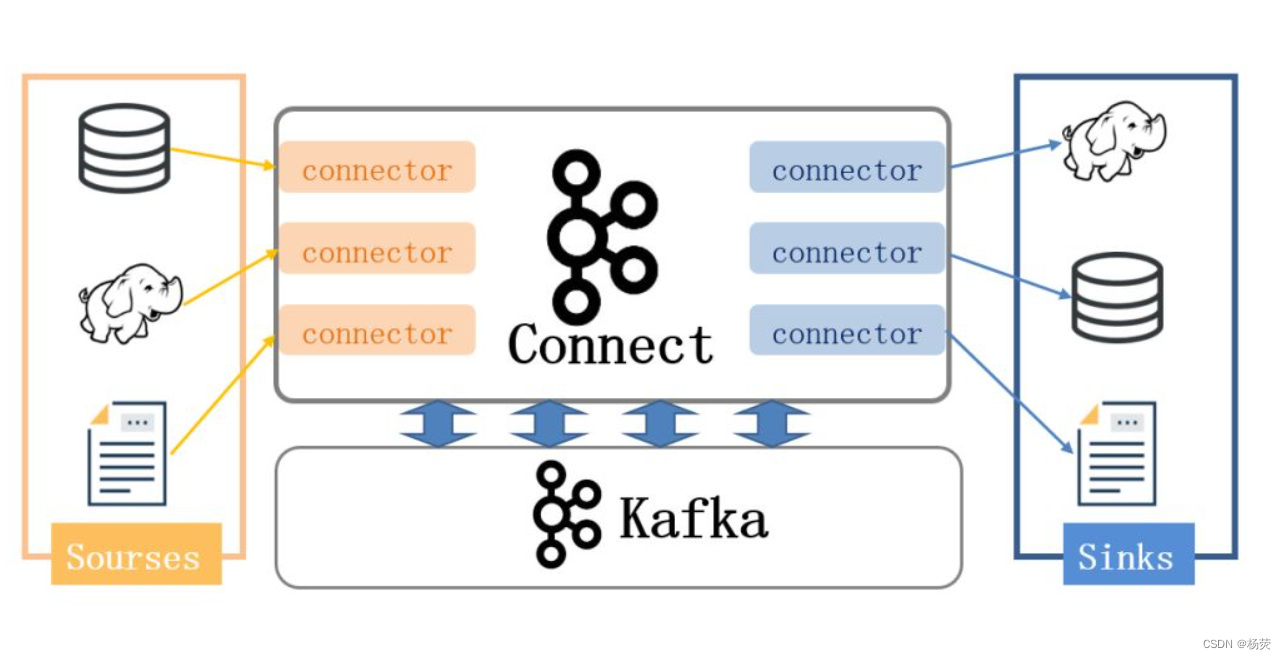
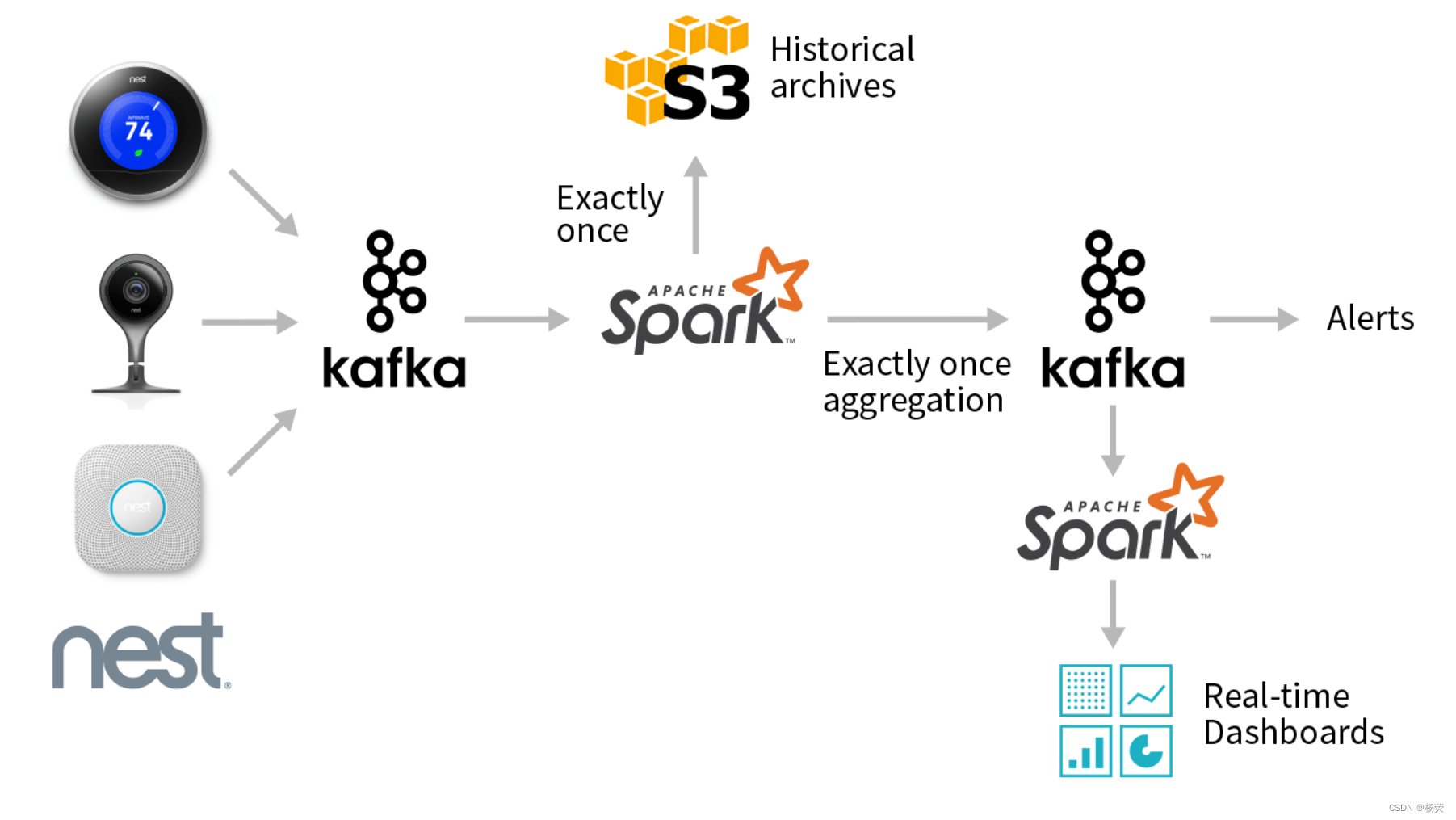
三、应用场景
Kafka消息队列具有高吞吐量、低延迟、可扩展性等特点,因此广泛应用于以下场景:
-
日志收集和数据管道:Kafka可以用作集中式日志收集系统,可以将不同服务、应用程序、服务器生成的日志集中到一个中心化的消息队列中,再通过消费者进行处理、分析和存储。同时,Kafka还可以作为数据管道,将不同数据源的数据通过消息队列进行传输和处理。
-
实时流处理:Kafka与流处理框架(如Apache Flink、Apache Spark)结合使用,可以实现实时的数据流处理。Kafka可以作为输入源和输出源,将数据流传输给流处理框架进行实时分析、计算和处理。
-
微服务架构:Kafka可以用作微服务之间的异步通信机制,不同的微服务各自独立地生产和消费消息,实现解耦和扩展性。同时,Kafka还可以用于实现事件驱动架构,不同的微服务通过订阅事件的方式进行通信和协作。
-
网络爬虫和数据采集:Kafka可以用于构建高可靠的网络爬虫系统和数据采集系统。爬虫可以将抓取的数据写入Kafka队列,然后其他系统可以消费这些数据进行进一步的处理和分析。
-
消息系统和通信中间件:Kafka提供了可靠的消息传递机制,可以作为消息系统和通信中间件,用于构建分布式系统、实现异步通信和跨系统的数据传输。
总之,Kafka消息队列的应用场景非常广泛,适用于大数据处理、实时数据流处理、异步通信等各种场景。它具有高性能、可靠性和可扩展性的特点,可以帮助解决数据流处理和消息传递的各种问题。
















 5249
5249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











