







决策树算法(decision tree)
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。
构造决策树的基本算法
| RID | age | income | student | credit_rating | buys_computer |
| 1 | youth | high | no | fair | no |
| 2 | youth | high | no | excellent | no |
| 3 | middle_aged | high | no | fair | yes |
| 4 | senior | medium | no | fair | yes |
| 5 | senior | low | yes | fair | yes |
| 6 | senior | low | yes | excellent | no |
| 7 | middle_aged | low | yes | excellent | yes |
| 8 | youth | medium | no | fair | no |
| 9 | youth | low | yes | fair | yes |
| 10 | senior | medium | yes | fair | yes |
| 11 | youth | medium | yes | excellent | yes |
| 12 | middle_aged | medium | no | excellent | yes |
| 13 | middle_aged | high | yes | fair | yes |
| 14 | senior | medium | no | excellent | no |
熵(entropy)概念:
信息和抽象,如何度量?
1948年,香农提出了“信息熵”的概念:
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==》信息量的度量就等于不确定性的多少
一个离散型随机变更X的熵H(X)定义为:

这个定义的特点是,有明确定义的科学名词且与内容无关,而且不随信息的具体表达式的变化而变化。是独立于形式,反映了信息表达式中统计方面的性质。是统计学上的抽象概念。
因此不易于理解,以下我们举例说明信息熵是什么?以及有什么用处?
直觉上信息量等于传输该信息所用的代价,这个也是通信中考虑最多的问题。比如说:堵马比赛里,有4匹马{A,B,C,D},获胜概率分别为{1/2,1/4,1/8,1/8}.
接下来,让我们将哪一匹马获胜视为一个随机变量
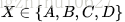
假定我们需要用尽可能少的二元问题来确定随机变量X的取值。
例如:
问题1:A获胜了吗?问题2:B获胜了吗?问题3:C获胜了吗?最后我们可以通过最多3个二元问题,来确定
 的取值,即哪一匹马赢了比赛。
的取值,即哪一匹马赢了比赛。
的取值,即哪一匹马赢了比赛。
如果
 ,那么需要问1次(问题1:是不是A?),概率为
,那么需要问1次(问题1:是不是A?),概率为
 ;
;
,那么需要问1次(问题1:是不是A?),概率为
;
如果
 ,那么需要问2次(问题1:是不是A?问题2:是不是B?),概率为
,那么需要问2次(问题1:是不是A?问题2:是不是B?),概率为
 ;
;
,那么需要问2次(问题1:是不是A?问题2:是不是B?),概率为
;
如果
 ,那么需要问3次(问题1,问题2,问题3),概率为
,那么需要问3次(问题1,问题2,问题3),概率为
 ;
;
,那么需要问3次(问题1,问题2,问题3),概率为
;
如果
 ,那么同样需要问3次(问题1,问题2,问题3),概率为
;
,那么同样需要问3次(问题1,问题2,问题3),概率为
;
,那么同样需要问3次(问题1,问题2,问题3),概率为
;
信息论之父克劳德·香农,总结出了信息熵的三条性质:
- 单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。
- 非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。
- 累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。写成公式就是:
事件
 同时发生,两个事件相互独立
同时发生,两个事件相互独立
 ,
,
同时发生,两个事件相互独立
,
那么信息熵
 。
。
。
香农从数学上,严格证明了满足上述三个条件的随机变量不确定性度量函数具有唯一形式:

其中的
 为常数,我们将其归一化为
为常数,我们将其归一化为
 即得到了信息熵公式。
即得到了信息熵公式。
为常数,我们将其归一化为
即得到了信息熵公式。
补充一下,如果两个事件不相互独立,那么满足

,其中
 是互信息(mutual information),代表一个随机变量包含另一个随机变量信息量的度量,这个概念在通信中用处很大。
是互信息(mutual information),代表一个随机变量包含另一个随机变量信息量的度量,这个概念在通信中用处很大。
是互信息(mutual information),代表一个随机变量包含另一个随机变量信息量的度量,这个概念在通信中用处很大。
比如一个点到点通信系统中,发送端信号为
,通过信道后,接收端接收到的信号为
 ,那么信息通过信道传递的信息量就是互信息
,那么信息通过信道传递的信息量就是互信息
 。根据这个概念,香农推出了一个十分伟大的公式,香农公式,给出了临界通信传输速率的值,即信道容量:
。根据这个概念,香农推出了一个十分伟大的公式,香农公式,给出了临界通信传输速率的值,即信道容量:
,通过信道后,接收端接收到的信号为
,那么信息通过信道传递的信息量就是互信息
。根据这个概念,香农推出了一个十分伟大的公式,香农公式,给出了临界通信传输速率的值,即信道容量:

决策树归纳算法(ID3)
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点 选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
1970-1980,J.Ross.Quinlan, ID3算法
选择属性判断结点
信息获取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)
通过A来作为节点分类获取了多少信息
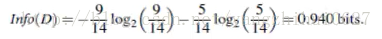
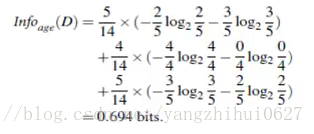
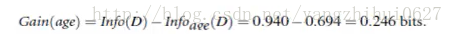
类似,Gain(income) = 0.029
Gain(student) = 0.151
Gain(credit_rating) = 0.048
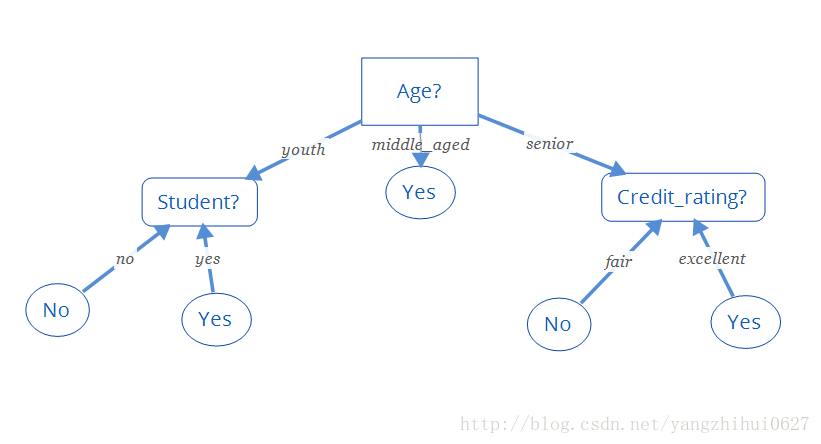
所以,选择age作为第一个根节点
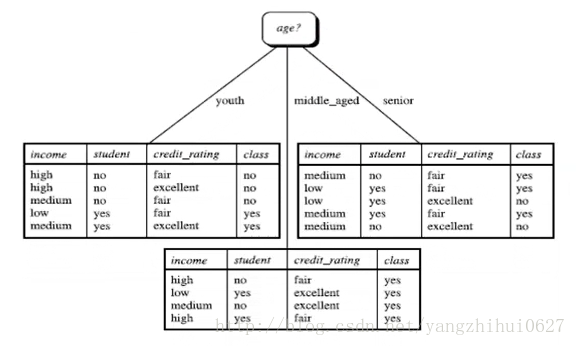
重复...
算法描述:
- 树以代表训练样本的单个结点开始(步骤1)。
- 如果样本都在同一个类,则该结点成为树叶,并用该类标号(步骤2和3)。
- 否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性(步骤6)。该属性成为该结点的“测试”或“判定”属性(步骤7)。在算法的该版本中,所有的属性都是分类的,即离散值。连续属性必须离散化。
- 对测试属性的每个已知的值,创建一个分枝,并据此划分样本(步骤8-10)
- 算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必在该结点的任何后代上考虑它(步骤13)
- 递归划分步骤公当下列条件之一成立停止:
- (a)给定结点的所有样本属于同一类(步骤2和3)。
- (b)没有剩余属性可以用来进一步划分样本(步骤4)。在此情况下,使用多数表决(步骤5)。 这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结点样本的类分布。
- (c)分支,test_attribute=a,没有样本(步骤11)。在这种情况下,以samples中的多数类创建一个树叶(步骤12)
决策树的其它算法
C4.5:Quinlan创建了此算法。
Classification and Rgression Trees: 简称CART算法,由(L.Breiman,J.Friedman,R.Olshen,C.Stone)创建的算法。
共同点:都是贪心算法,自上而下(Top-down approach)
区别:属性选择度量方法不同,C4.5采用了gain ratio算法;CART采用了gini index算法;ID3采用了information Gain信息熵算法。
如何处理连续性变量的属性?
增加阈值,将连续的属性值离散化。
修剪枝叶(避免overfitting)
树分枝太细化会影响生产环境中数据预测效率,因此树枝细化到一定程序时需要修剪树枝进行控制。分为先剪枝和后剪枝。
决策树的优点
直观,便于理解,小规模数据集有效
决策树的缺点
处理连续变量不好(例如房价的变化),需要离散化处理;类别较多时,错误增加的比较快;数据规模较大时,计算时间将大大增加,只适合小规模数据集使用。















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









