







数据结构三要素:逻辑结构、数据的运算、存储结构(物理结构)
1:线性表
1:定义:具有相同数据类型的n个数据元素的有限序列,其中n为表长,n=0时线性表是一个空表
特点:有限可空序列//most:随机访问,可以通过首地址和元素序号在O(1)内找到指定元素
(线性表中的位序从1开始,除首个元素之外,每个元素有且仅有一个前驱,同理,除最后一个元素之外,每个元素有且仅有一个后继元素)
2: 优点:存储密度大/高,每个结点只存储数据元素
缺点:插入删除运算不方便,移动大量元素
【由于逻辑顺序与物理顺序相同所以是随机存取的存储结构】
【也可以顺序存取】
2:线性表的基本操作
需要修改的要传入指针
【从无到有and从有到无-创建销毁】:初始化表和销毁操作
- InitList(&L):初始化表,构造一个空的线性表L,分配内存空间。
- DestroyList(&L):销毁线性表,并释放所占用的内存空间。
【增删】
- ListInsert(&L,I,e)插入,在表L中的第i个位置插入指定元素e。
- ListDelete(&L,I,e)删除表L指定I位置的元素,用e返回删除元素的值
【改查】
- LocateElem(L,e)按值查找,表L中查找具有给定关键字值的元素
- GetElem(L,i)按位查找,获取表L中第i位的元素的值
【其他】
- Length(L):求表长,返回线性表L的长度,即L中数据元素的个数
- PrintList(L)输出操作,按前后顺序输出线性表L的所有元素值
- Empty(L)判空操作。若L为空返回true反之False
【这里“&”的意思是引用类型,表示对参数的修改结果需要带回来的时候使用】
3:存储/物理结构
- 顺序表(顺序存储)【学习定义/基本操作的实现】
1⃣️:定义:用顺序存储的方式实现存储,逻辑上相邻的存储单元在物理上也相邻。
【因为存放的是相同的数据类型,因此每个数据元素所占空间一样大。而由于顺序存储的特点,可以得出每个元素的存放位置:】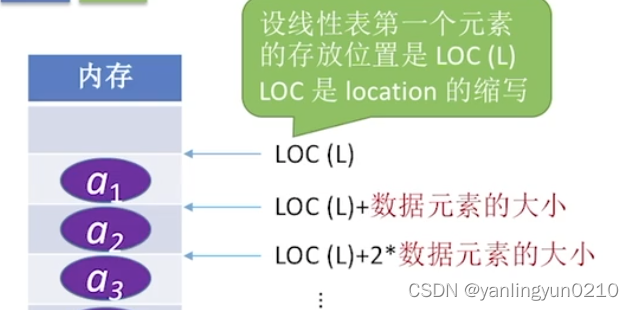
同时在c语言中可以利用sizeof(ElemType)来了解一个数据元素的大小:
如sizeof(int)=4B
2⃣️:顺序表的实现——静态分配(创建操作)
#define MaxSize 10//定义最大长度
typedef struct{
ElemType data[MaxSize];//用静态的数组存放数据元素。其中ElemType 可以为int型等等
int length;//顺序表当前长度(现在已经存放了多少个数据元素)
}SqList//顺序表的类型定义(静态分配方式)
int main(){//主函数操作
Sqlist L;//声明一个顺序表
InitList(L);//初始化顺序表L分配内存空间,这个空间包括MaxSize*sizeof(elemtype)和存储length的空间
return 0;//函数类型为int型,需要返回一个int值
}
//void类型实现初始化线性表功能的函数
void InitList(SqList &L){
for(int i=0;i<L.length;i++)
L.data[i]=0;//将所有数据元素设置为默认初始值
L.length=0;//顺序表初始长度为0[这一步是必须做的]
}
【如果没有设置数据元素的默认初始值,可能会将内存中遗留的脏数据打印出来】
【静态数组的大小一旦确定就不可以再更改。如果数组存满了不够了直接放弃就行了……
如果大小可变的话就变成了动态分配。】
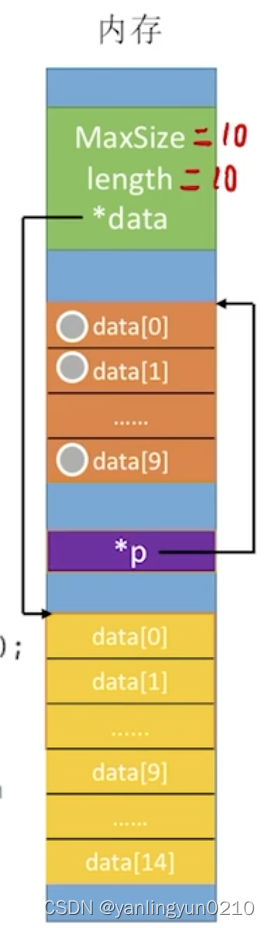
2⃣️-2:顺序表的实现——动态分配
动态分配不是链式存储,也是顺序存储结构,物理结构没有变化,依然是随机存取的方式,只是分配空间大小可以在运行时动态决定。
#define InitSize 10//顺序表的初始长度
typedef struct{
ElemType *data;//指示动态分配数组的指针
int MaXSize;
int length;
}Seqlist;//顺序表的类型定义(动态分配方式)
【在C语言中有动态申请和释放内存空间的两个函数:
1:malloc动态申请一整片连续内存空间,使用后会返回一个指向初始位置的指针,需要强转为所定义的数据元素类型的指针
L.data=(ElemType*)malloc(sizeof(ElemType)*Initsize);
2:free释放】
完整的流程如下:
#include<stdlib.h>//包含free和malloc函数
#define InitSize 10
typedef struct{
int*data;
int MaxSize;
int length;
}SeqList;
void InitList(SqlList &L){
L.data=(int*)malloc(InitSize*(int));//利用malloc函数分配一整片的内存空间,这个时候定义的data指针指向开辟的这一段空间的初始
L.length=0;
L.MaxSize=InitSize;
}
//增加动态数组的长度
void IncreaseSize(Sqlist &L,int len){
int *p=L.data;//这里的L.data是初始化操作里初始的位置
L.data=(int *)malloc(L.maxsize+len)*sizeof(int));
for(int i=0;i<L.length;i++){//相当于在原先是数组基础上+扩展的长度=组成一个新的数组
L.data[i]=p[i];//将数据复制到新区域
}
L.MaxSize=L.MaxSize+len;
free(p);//释放原先的数组(橘色部分就释放了)}
int main(){//主函数
Seqlist(L);
Initlist(L);//Q:是否需要带指针?(9.24)A:不用,在函数定义时就写好了,使用时不需要。
Increasesize(L,5);//往顺序表中插入几个元素
return 0;
}
3⃣️:顺序表实现的特点:
随机访问:能在O(1)时间内找到第i个元素
存储密度高【但是要求大片连续空间,改变容量不方便】
扩展容量不方便
插入、删除元素不方便
4⃣️:顺序表的插入和删除【代码实现/复杂度分析】
4-1:插入
#define MaxSize 10;
typedef struct{
int data[Maxsize];//静态数组方式
int length;
}Sqlist;
bool ListInsert(Sqlist &L,int i,int e){//扩充了代码健壮性
if(i<1||i>L.length+1)
return false;//判断i值是否合法
if(L.length>=MaxSize) //存储空间已满不能插入
return false;
for(int j=L.length;j>=i;j--)
L.data[j]=L.data[j-1];//将第i个元素及之后的元素后移【举个栗子:将原先5号位的放到6号位上,由于是右到左的执行,所以5操作在右,6操作在左。(9.24)
L.data[i-1]=e;//位置i处放e【注意位序(从1开始)和下标(从0开始)的关系(data这里说的就是下标了,而在位置i插入e的下标就是i-1】
L.length++;//插入一个新元素,表长+1
return true;}
int main(){
Sqlist L;//声明
InitList(L);
ListInsert(L,3,3);
return 0;
}
其中,时间复杂度要关注最深层循环语句的执行次数与问题规模n的关系,这里定位到L.data[j]=L.data[j-1];其中n=L.length(表长)
Best:O(1);
Worst:O(n);
avg:n/2:也是O(n);看书p15
相当于在n个元素的间隔中插入一个,那么就是1/(n+1)的概率,平均移动次数为n*(n+1)/2【p15页】
移动元素:n-i+1
4-2:删除
bool ListDelete(Sqllist &L,int i,int &e){//删除第i个就是下标为i-1的元素
if(i<1||i>L.length)
return false;
e=L.data[i-1];//被删元素的值赋值给e
for(int j=i;j<L.length;j++)//前移时,先移动前面的元素,后面依次跟着,在插入的代码中,向后移动时,是后面的先移动,依次往前。同样的栗子,这时是4号位移动到3号位,后面依次,所以为右4左3
L.data[j-1]=L.data[j];
L.length--;//删掉一个元素,所以长度-1
return ture;
}
int main(){
Sqllist L;
InitList(L);
int e=-1;//用变量e把删除的元素带回来,因为是引用类型&e
if(listDelete(L,3,e))
printf("已删除第3个元素,删除元素值为=%d\n",e);
else
printf("位序i不合法,删除失败“)
return 0;
}
删除的复杂度分析:
best:删除表尾O(1)
worst :删除表头O(n)
avg:(n/2)*(n-1)=(n-1)/2=O(n)
移动元素:n-i【平均的话要求和】【1到n项】
不论是插入还是删除,消耗时间的是移动元素,而移动元素取决于插入和删除元素的位置
5⃣️顺序表的查找操作(按位/按值)
5-1:按位查找:获取表L中第i个位置的元素的值。
[静态分配]
#define Maxsize 10
typedef struct{
ElemType data[maxsize];//静态数组存放数据元素
int length;
}Sqlist;
ElemType GetElem(Sqllist L,int i){
return L.data[i-1];//这里可以判断一下i的值是否合法,对增加健壮性有好处
}
[动态分配]
```c
#define InitSize 10
typedef struct{
ElemType *data;//指向malloc分配的一大片存储空间初始
int MaxSize;
int Length;
}Seqlist;
ElemType GetElem(SeqLIst L,int I){
return L.data[i-1];
}
ElemType*data
时间复杂度为O(1);
5-2顺序表按值查找:
【动态分配】
typedef struct{
int *data;
int maxsize;
int length;
}seqList;
int LocateElem(seqlist L,int e){
for(int i=0;i<L.length;i++){
if(L.data[i]==e)
return i+1;}
return 0;
}
时间复杂度:与移动元素挂钩
best:O(1)目标元素在表头
worst:O(n)目标元素在表尾
avg:O(n)
查找元素:i,平均为i(i+1)/2
- 链表(链式存储)
1⃣️:单链表【定义/基本操作的实现】
2⃣️:双链表
3⃣️:循环链表
4⃣️:静态链表
1⃣️:两种实现【带头节点(1-1)】【不带头节点(1-2)】相比于顺序表,链表中的每个结点除了存放数据元素外,还要存储指向下一个节点的指针。
【链表的优点:不要求大片连续空间,改变容量方便】
【链表的缺点:不可随机存取,需要耗费一定的空间存放指针】
1-1:代码定义
struct Lnode{//定义单链表结点类型
Elemtype data;//数据域
strict Lnode *next;//指针域,指针指向下一个结点
}
struct LNode* p=(struct Lnode*)malloc(sizeof(struct Lnode));//但是这里有一个弊端:每次都需要声明点出struct Lnode会显得很冗余
//增加一个新的结点,在内存中申请一个结点所需要的空间,并用p指向这个结点
改变上面代码的弊端,可以用之前就用过的一个内容:typedef<数据类型><别名>
加深理解:
typedef int num;
typedef int *numzhizhen;
原先是:
int x=1;
int *p;
现在是:
num x=1;
numzhizhen p;//实现的是数据类型重命名
故这里可以把struct Lnode重命名为Lnode,以后使用就不需要再带struct
LNode* p=( Lnode*)malloc(sizeof(Lnode));//变成这样
但是对于上述的声明,可以给出另一个更简单的表达,代码如下:
typedef struct Lnode{
elemType data;
struct Lnode*next;
}Lnode,*LinkList;
//区分线
struct Lnode{
ElemType data;
struct Lnode *next;
};
typedef struct Lnode Lnode;
typedef struct Lnode*linklist;//用linklist表示这是一个指向struct Lnode的指针
在这里,linklist L与Lnode*L是等价的。
但是前面的linklist强调的是一个链表,后者强调的是一个结点。
1-2不带头结点的单链表
【带头结点的单链表需要用malloc开创一个空间】
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}Lnode,*linkList;
//初始化一个空的单链表
bool InitList(Linklist &L){
L=NULL;//空表,暂时没有任何结点
//防止脏数据
return ture;}
void test(){
LinkList L;//声明一个指向单链表的指针
InitList(L);
}
1-1:带头结点的单链表
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}Lnode,*linkList;
//初始化一个空的单链表
bool InitList(Linklist &L){
L=(Lnode *)malloc(sizeof(Lnode));//分配一个头结点,结果赋值给L(头结点不存储数据)
if(L==NULL);//内存不足分配失败
return false;
//防止脏数据
L->next=NULL;//这里是带头结点对于空表判断的语句【在不带头结点的链表中是L=null】
return ture;}
void test(){
LinkList L;//声明一个指向单链表的指针
InitList(L);
}
二者区别:
带头结点,写代码更方便。
1-3:单链表的插入删除
【1-3-1】插入:1⃣️按位序插入(带头(1)/不带头(2))
2⃣️指定结点的后插
3⃣️指定结点的前插
【1-3-2】删除:1⃣️按位序删除
2⃣️指定结点的删除
【1-3-1-1(1)带头结点】
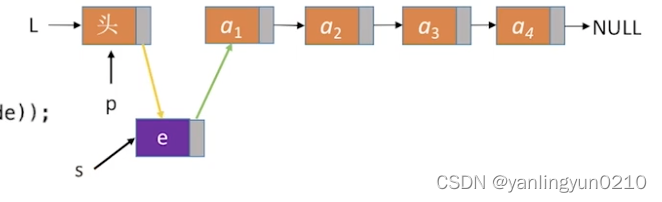
在第i个位置插入指定元素,表明需要找到第i-1个结点将新结点插入其后。
//在第i个位置插入元素e(带头结点)
bool ListInsert(LinkList &L,int i,int e){
if(i<1)//i表示位序如果小于1不合法
return false;
Lnode *p;//指针p指向当前扫描到的结点
int J=0;//当前p指向的是第几个结点
p=L;//L指向头结点,头结点是第0个结点。
while(p!=NULL&&j<i-1){
p=p->next;
j++//循环找到第i-1个结点
}
if(p==NULL)//i值不合法
return false;
Lnode *s=(Lnode *)malloc(sizeof(Lnode));//开辟一个新结点
s->data=e;
s->next=p->next;//该句与下一句不可以颠倒
p->next=s;//将结点s连入p之后
return true//插入成功
}
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}Lnode,*LinkList;
时间复杂度与查找位置挂钩,比如找到第n个位置就是O(n):
best:插在表头:O(1)
worst:插在表尾:O(n)
问题规模n指的是表的长度
【此时如果i超出了给定的大小那么就会不满足while循环直接跳出执行p==null的判断输出false】
【1-3-1(2)】不带头结点
基本思路与1-3-1-1相同,但是不存在头结点「第0个」所以对头进行一个特殊处理
bool ListInsert(LinkList &L,int i,ElemType e){
if(i<1)
return false;
if(i==1){//在第一个结点插入的操作与其他结点不同
Lnode *s=(Lnode *)malloc(sizeof(Lnode));
s->data=e;
s->next=L;
L=s;//头指针指向新结点
return true;
}
Lnode *p;//指针p指向当前扫描到的结点
int j=1;//当前p指向的是第几个结点
p=L;//p指向第一个结点(不是头结点)
while(p!=NULL&&j<i-1}
p=p->next;
j++;
}
if(p==NULL) //i值不合法
return false;
Lnode *s=(Lnode *)malloc(sizeof(Lnode));
s->data=e;
s->next=p->next;
p->next=s;
return true;//插入成功
}
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}Lnode,*LinkList;
[1-3-2]:指定结点的后插
//在p结点后插入元素e
bool InsertNextNode(Lnode *p,ElemType e){
if(p==NULL)
return false;
Lnode *s=(Lnode *)malloc(sizeof(Lnode));
if(s==null)//内存分配失败
return false;
s->data=e;
s->next=p->next;
p->next=s;
return true;
}
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}Lnode,*LinkList;
时间复杂度是O(N)
[1-3-3]指定结点的前插操作
由于指定结点的前驱结点是未知的,所以要解决这个问题,但是显然不知道头结点不能依次遍历得到指定结点的前驱结点,那么可以换一个思路
在指定结点后插入一个新结点,先改变后继,再将原先指定结点(假设p)的值赋给这个新结点,再将要求插入的值赋给原p结点。
bool InsertPriorNode(Lnode *p,ElemTYpe e){
if(p==null)
return false;
Lnode *s=(Lnode *)malloc(sizeof(Lnode));
if(s==null);
return false;
s->next=p->next;
p->next=s;
s->data=p->data;
p->data=e;//p是指的是逻辑上的位置,而不是实际的p(9.24)
return true;
}
时间复杂度是O(1)
【1-3-2-1】按位序删除(带头结点)
bool ListDelete(LinkList &L,int i,elemType&e){
if(i<1)
return false;
Lnode *p;
int j=0;
p=L;
while(p!=null&&j<i-1){
p=p->next;
j++;
}
if(p==null)
return false;
if(p->next==null)//在i-1个结点之后已无其他结点
return false;
Lnode *q=p->next;//令q指向被删除结点
e=q->data;//用e返回元素的值
p->next=q->next;
free(q);//释放q【先看下面的两个例子就好理解了】
return true;
}
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}Lnode,*LinkList;
这个算法最坏和平均O(n)
最好时间复杂度:O(1)
【1-3-2-2】指定结点的删除
//删除指定结点p
bool DeleteNode(Lnode *p){
if(p==null)
return false;
Lnode*q=p->next;//令q指向*p的后继结点
p->data=p->next->data//和后继结点交换数据域
p->next=q->next;//将*q结点从链中“断开”
free(q);//相当于把p的值给了q,然后再把q释放,就相当于删除了p
return ture;
}
时间复杂度:O(n)【首先要先一个一个找到】
【单链表的局限性:无法逆向检索,有时候不方便】
1-4:单链表的查找【按位查找/按值查找】(只讨论带头结点的情况)
1-4-1:按位查找
//按位查找,返回第i个元素(带头结点(第0个))
Lnode*GetElem(LinkList L,int i){
if(i<0)
return false;
Lnode *P;
int j=0;
p=L;
while(p!=NULL&&j<i-1){
p=p->next;
j++;
}
return p;
}
平均时间复杂度:O(n),因为int i的值取到【0,length】范围内的值是等可能的
【这里利用到了封装,后续就可以直接使用,避免重复的代码,简洁,容易维护】
【1-4-2】按值查找
//返回的类型为Lnode*
Lnode * LocateElem(LinkList l,ElemType e){
Lnode *p=L->next;//从第一个结点开始查找数据域为e的结点
while(p!=null&&p->data!=e)
p=p->next;
return p;//找到后返回该结点指针,否则返回Null
}
1-5:求表的长度
int LengthList(LinkList l){
int len=0;
Lnode *p=L;
while(p->next!=NULL){
p=p->next;
len++;}
return len;
}
时间复杂度为:O(n)
1-6:单链表的建立【头插/尾插】
step1:初始化一个单链表
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}Lnode,*linkList;
//初始化一个空的单链表
bool InitList(Linklist &L){
L=(Lnode *)malloc(sizeof(Lnode));//分配一个头结点,结果赋值给L(头结点不存储数据)
if(L==NULL);//内存不足分配失败
return false;
//防止脏数据
L->next=NULL;//这里是带头结点对于空表判断的语句【在不带头结点的链表中是L=null】
return ture;}
void test(){
LinkList L;//声明一个指向单链表的指针
InitList(L);
}//1-1的内容
step2:每次取一个元素插入表头/表尾
[头]
L=(LinkList)malloc(sizeof(Lnode));//创建头结点
L->Next=NULL;
scanf("%d",&x);
while(x!=9999){
S=(Lnode*)malloc(sizeof(Lnode));
s->data=x;
s->next=L->next;
L->Next=s;
scanf("%d",&x);
}
return L;
}
【尾】
int x;
L=(LinkList*)malloc(sizeof(Lnode));
Lnoede *s,*r=L;//r为尾指针
scanf("%d",&x);//输入结点的值
s->data=x;
r-next=s;
r=s;
scanf("%d",&x);
}
r->next=null;
return L;
}
【双链表】
为了克服单链表的缺点【因为只有一个指向其后继的指针,所以单链表只能从头结点依次顺序的遍历,要访问某个节点的前驱结点(插入删除)只能从头开始遍历,访问后继结点的时间复杂度为O(n),访问后继结点为O(1)】
双链表增加了一个prior指针,因此双链表中的按值查找和按位查找的操作与单链表相同,删除插入不同,因为链变化时也需要对prior指针作出修改,其关键是保证在修改过程中不断链,同时双链表可以很方便的找到其前驱结点,因此插入删除的时间复杂度为O(1)
插入代码如下
在p结点和c结点中插入s结点
1. s->next=p->next;
2. p->next->prior=s;
3. s->prior=p;
4. p->next=s;
其中四必须位于12之后,否则会因为丢失指针而插入失败
删除操作如下
删除pc之间的q结点
p->nexq=q->next;
q-next-prior=p;
free(q);
循环链表
循环链表与单链表的区别:表中最后一个结点不是null,而是改为指向头结点,从而整个形成一个环。
在循环单链表中,表尾结点*r的next域指向L,所以表中没有指针域为null。
循环单链表判空的条件不是头结点的指针是否为空,而是它是否等于头指针。
特点:
循环单链表的插入删除与单链表几乎一样,不同的是若操作在表尾进行的话,则执行不同的操作,让单链表保持环的特性。
也正因为单链表是个环,因此在任何一个位置上插入删除操作都是等价的,无需判断是否为表尾。
循环单链表可以从表中任意一个结点开始遍历整个链表
有时对单链表常做的操作是在表头和表尾进行的,此时对循环单链表不设头指针和尾指针,从而使得更高效,因为设置头指针与尾指针需要o(n)时间复杂度,不设置的话为O(1)。
循环双链表
头结点prior还要指向表尾结点
若*p为尾结点时,p->next==L;
当循环双链表为空时,头结点的prior域和next域都等于L。














 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









