







一、RDD编程模型
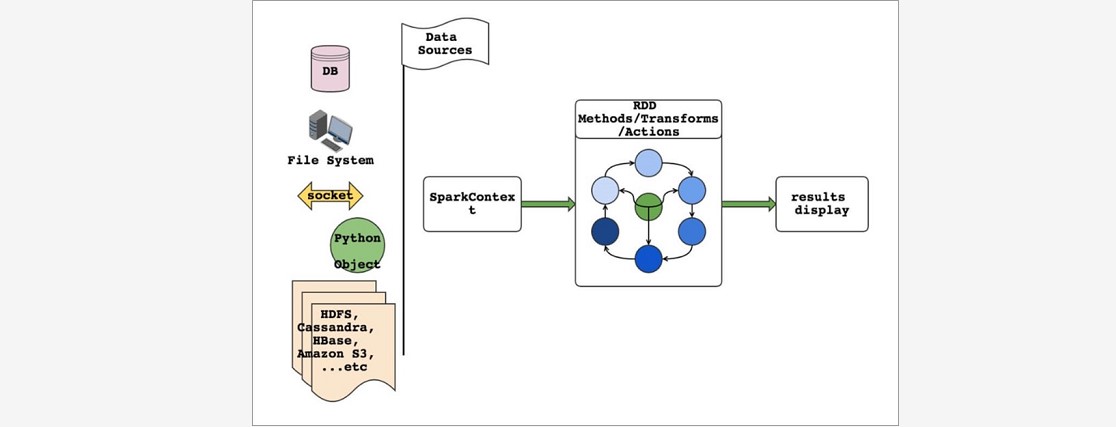
### --- RDD编程模型
~~~ RDD表示数据对象
~~~ 通过对象上的方法调用来对RDD进行转换
~~~ 最终显示结果 或 将结果输出到外部数据源
~~~ RDD转换算子称为Transformation是Lazy的(延迟执行)
~~~ 只有遇到Action算子,才会执行RDD的转换操作### --- 要使用Spark,需要编写 Driver 程序,它被提交到集群运行
~~~ Driver中定义了一个或多个 RDD ,并调用 RDD 上的各种算子
~~~ Worker则执行RDD分区计算任务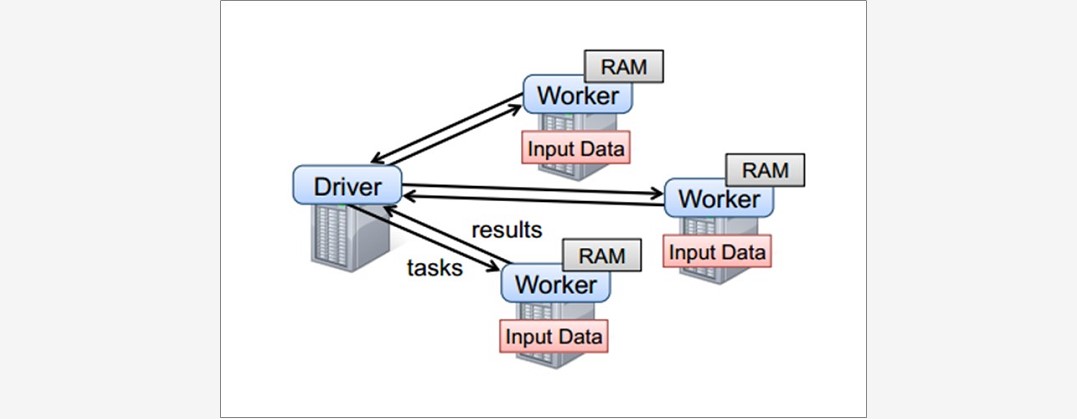
















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











