







一、Canal同步业务数据
### --- 环境准备
~~~ Hadoop、HBASE、Flink、ClickHouse、MySQL、Canal、Kafka### --- 初始Canal:什么是 Canal
~~~ 阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,
~~~ 所以衍生出了杭州和美国异地机房的需求,
~~~ 从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,
~~~ 获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
~~~ Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。
~~~ 目前,Canal主要支持了MySQL的binlog解析,
~~~ 解析完成后才利用Canal client 用来处理获得的相关数据。
~~~ (数据库同步需要阿里的otter中间件,基于Canal)。
二、使用场景:
原始场景:阿里otter中间件的一部分otter是阿里用于进行异地数据库之间的同步框架Canal是其中一部分。
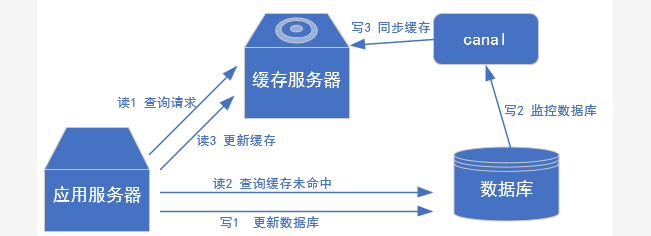
常见场景1:更新缓存
场景2:抓取业务数据新增变化表,用于制作拉链表:订单表,6月20号有3条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
| 2012-06-20 | 001 | 创建订单 |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
到6月21日,表中有5条记录:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











