







今天给大家分享一篇论文。
题目是:HybGRAG:基于文本和关系型知识库的混合检索增强生成

论文链接:https://arxiv.org/abs/2412.16311
论文概述
这篇论文试图解决的问题是如何有效地从半结构化知识库(Semi-structured Knowledge Base, SKB)中检索相关信息以回答用户的问题。具体来说,论文关注于混合型问题(hybrid questions),这类问题需要同时利用文本信息和关系信息来正确回答。半结构化知识库由结构化知识库(例如知识图谱)和非结构化的文本文档组成,其中文本文档与知识图谱中的实体相关联。论文指出,现有的检索增强生成(Retrieval-Augmented Generation, RAG)方法和图检索增强生成(Graph RAG, GRAG)方法在处理这类混合问题时存在局限性,因此需要一种新的混合检索方法来同时利用文本和关系信息。
论文中提到的具体挑战包括:
-
混合源问题(Hybrid-Sourcing Question):有些问题需要同时利用文本和关系信息来解答,而现有的方法往往只专注于检索单一类型的信息(要么只检索文本信息,要么只检索关系信息)。
-
需要细化的问题(Refinement-Required Question):在混合问题中,大型语言模型(Large Language Models, LLMs)在首次尝试时很难区分问题的文本和关系方面,需要进一步细化。
为了解决这些挑战,论文提出了HYBGRAG(Hybrid Retrieval-Augmented Generation)方法,该方法包括一个检索器库(retriever bank)和判断器模块(critic module),旨在通过自反思(self-reflection)和细化问题路由(question routing)来提高混合问题回答的性能。
相关工作
根据提供的论文内容,相关研究可以分为以下几个方向:
-
检索增强生成(Retrieval-Augmented Generation, RAG):
- 这类研究关注于如何使大型语言模型(LLMs)通过访问非结构化文档数据库来解决开放域问答(Open-Domain Question Answering, ODQA)问题。RAG通过检索文档来辅助LLMs进行问题回答。
-
图检索增强生成(Graph RAG, GRAG):
- GRAG扩展了RAG的概念,通过从结构化知识库中检索信息。这个方向的研究主要分为两个领域:从知识图谱(KGs)中提取关系信息用于知识库问答(Knowledge Base Question Answering, KBQA),以及在数据库中构建文档间的关系以提高ODQA性能。
-
混合问题回答(Hybrid Question Answering, HQA):
- 这是一个新兴的研究问题,专注于需要同时使用关系和文本信息来正确回答的问题,给定一个半结构化知识库(SKB)。
-
自反思的大型语言模型(Self-Reflective LLMs):
- 这类研究关注于如何通过反馈驱动的反射过程来优化LLMs的输出。这涉及到使用各种方法实现的评论家(critic),包括预训练的LLMs、外部工具或微调过的LLMs。
-
知识图谱和文档间关系构建:
- 一些研究工作专注于从知识图谱中提取信息,以及在数据库中构建文档间的关系,以改善问题回答和检索性能。
具体到论文中提及的一些相关研究工作,包括但不限于:
-
QA-GNN:利用LLMs和知识图谱进行问答的系统。
-
Think-on-Graph:使LLMs能够在知识图谱上进行深入和负责任的推理。
-
AVATAR:通过对比推理优化LLM代理的工具辅助知识检索。
核心内容
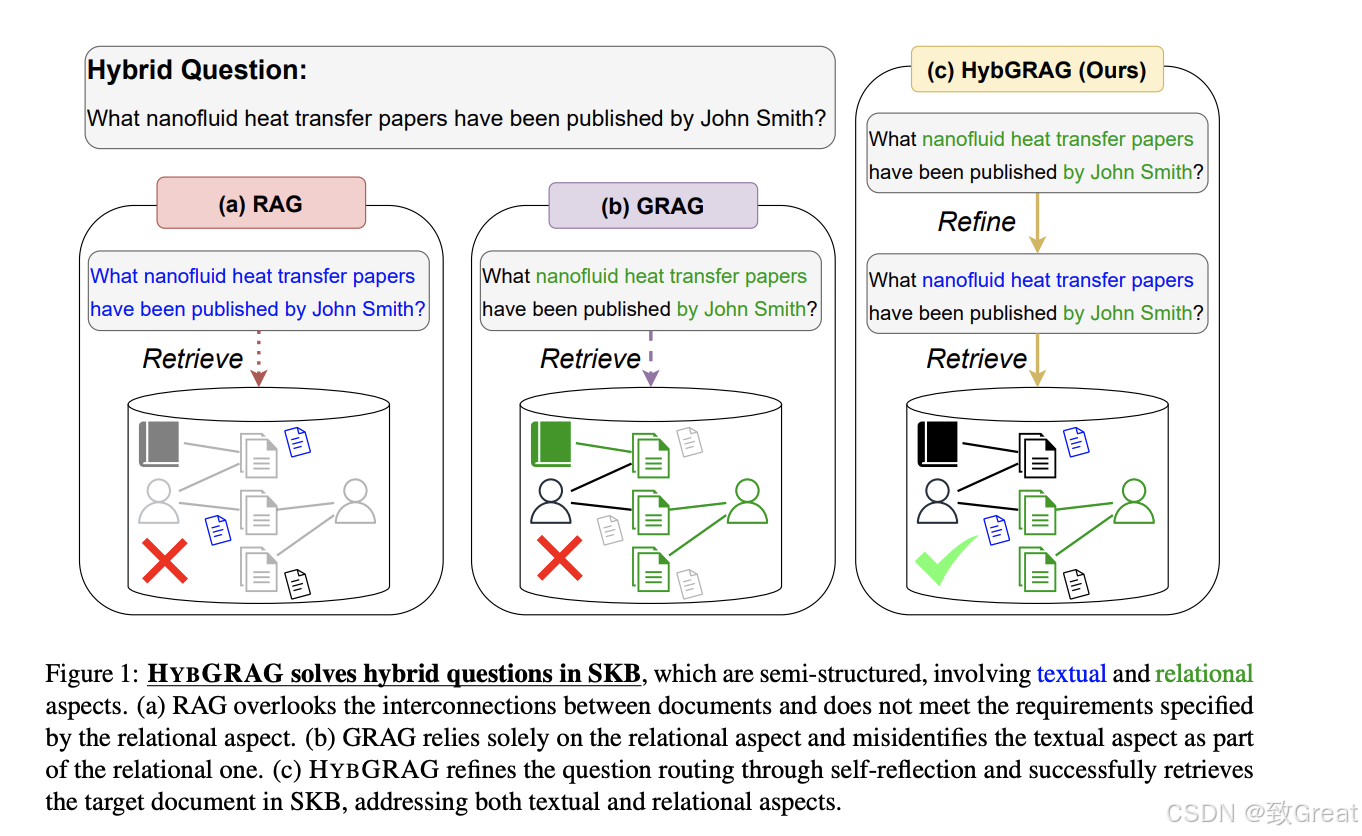
论文提出了HYBGRAG(Hybrid Retrieval-Augmented Generation)模型来解决半结构化知识库(SKB)上的混合问题回答(HQA)。HYBGRAG模型通过以下方式解决这个问题:
- 检索器库(Retriever Bank)
检索器库由多个检索模块和一个路由器组成。路由器负责确定选择和使用哪个检索模块,这个过程被称为问题路由(question routing)。检索模块包括文本检索模块和混合检索模块,它们分别从文本文档和SKB中检索信息。
-
文本检索模块:使用向量相似性搜索(VSS)基于给定问题从文档集合D中检索文档。
-
混合检索模块:基于识别出的主题实体和有用关系,使用图检索器从知识图谱G中提取实体,并与文档关联。
- 判断器模块(Critic Module)
判断器模块提供反馈以帮助路由器执行更好的问题路由。该模块分为两个部分:LLM验证器(Cval)和LLM评论器(Ccom)。
-
验证器(Validator):验证器的任务是确认检索到的顶部参考资料是否满足问题的要求。为此,它使用主题实体和提取的 ego-graph 之间的推理路径作为验证上下文。
-
评论器(Commentor):当检索结果不正确时,评论器提供反馈以帮助路由器细化其行动。反馈是基于预先收集的成功案例,通过上下文学习(ICL)提供。
- 自我反思(Self-Reflection)
HYBGRAG通过自我反思迭代改进其问题路由。这个过程类似于链式思考(Chain-of-Thought, CoT),提供了直观的解释,说明性能改进的原因。
- 整体算法
HYBGRAG的整体算法如下:
-
给定一个问题q,在第t次迭代中,路由器确定 s t st st、 ˆ E t ˆEt ˆEt和 ˆ R t ˆRt ˆRt,以从G和D或仅D中检索参考资料 X t Xt Xt。
-
验证器Cval然后决定是否接受Xt作为最终答案,或者拒绝它。
-
如果 X t Xt Xt被拒绝,评论器Ccom生成反馈 f t + 1 ft+1 ft+1以帮助路由器在第 t + 1 t+1 t+1次迭代中细化其行动。

论文实验
论文中进行了一系列实验来评估HYBGRAG模型的性能,并回答了几个研究问题(RQs)。以下是论文中提到的实验:
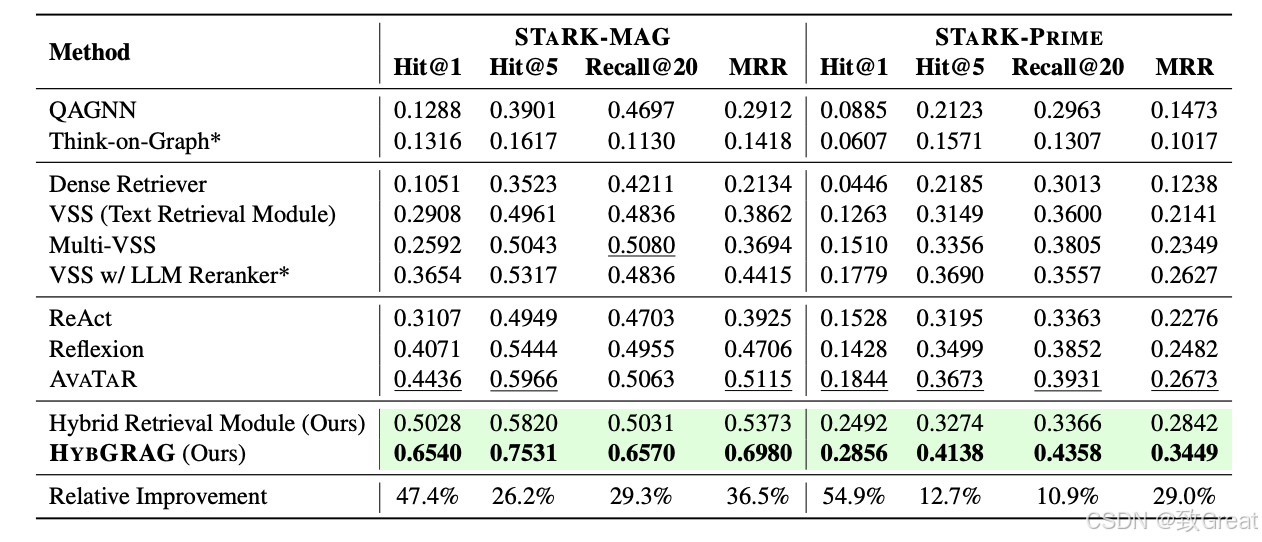
1. 实验在GRAG基准测试上(RQ1:有效性)
-
STARK基准测试:使用STARK基准测试中的两个数据集(STARK-MAG和STARK-PRIME)来评估HYBGRAG模型。这个基准测试专注于检索任务,并提供了默认的评估指标,包括Hit@1、Hit@5、Recall@20和平均倒数排名(MRR)。
-
比较基线方法:HYBGRAG与多种基线方法进行比较,包括最近的GRAG方法(如QAGNN和Think-on-Graph)、传统的RAG方法和自反思的大型语言模型(如ReAct、Reflexion和AVATAR)。
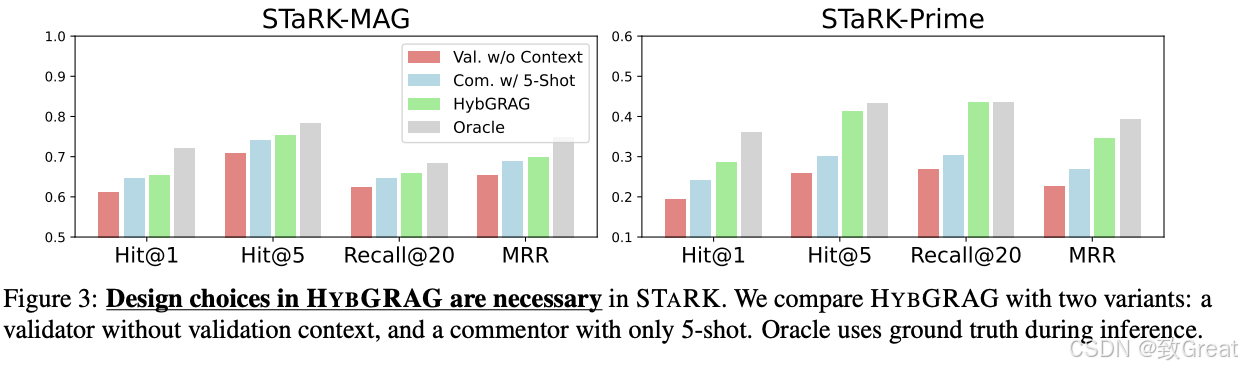
2. 消融研究(RQ2:设计选择的必要性)
-
评论器模块:比较了HYBGRAG的不同变体,包括没有验证上下文的验证器、只有5-shot的评论器,以及使用oracle(拥有地面真实情况的访问权限)的变体。
-
自我反思:展示了通过增加自我反思迭代次数,HYBGRAG的性能如何进一步提升。
3. 解释性(RQ3:基于反馈的问题路由细化)
- STARK中的解释性:通过STARK-MAG和STARK-PRIME中的例子,展示了HYBGRAG如何根据评论家模块的校正反馈细化其实体和关系提取。

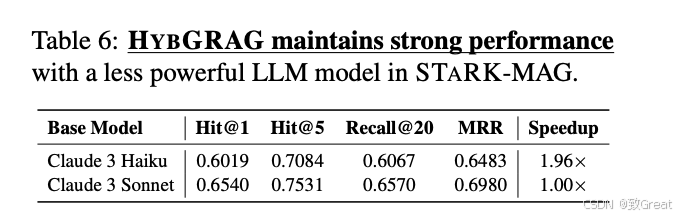
- 模型大小的影响:测试了HYBGRAG在不同大小的LLM模型上的表现,包括更经济但功能较弱的Claude 3 Haiku模型。
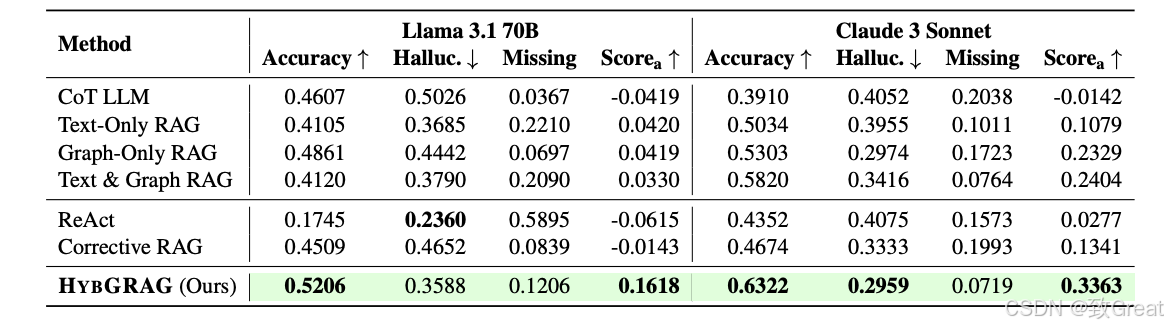
4. 端到端RAG评估在CRAG上
-
CRAG基准测试:在CRAG基准测试上适应HYBGRAG,并使用默认评估指标进行评估,其中LLM评估器用于确定预测答案的准确性、错误(幻觉)或缺失。
-
比较基线方法:HYBGRAG与CoT LLM、仅文本RAG、仅图RAG以及连接文本和图参考的RAG进行比较。
5. 模型成本分析
- API调用和令牌消耗:报告了HYBGRAG在STARK和CRAG中每个步骤的API调用和令牌消耗情况,以评估模型的成本效益。
这些实验旨在全面评估HYBGRAG模型在混合问题回答任务上的有效性、设计选择的必要性、解释性以及成本效益,并与现有的基线方法进行比较。通过这些实验,论文展示了HYBGRAG在处理半结构化知识库上的混合问题时的优势。
编者简介
致Great,中国人民大学硕士,多次获得国内外算法赛奖项,目前在中科院计算所工作,目前负责大模型训练优化以及RAG框架开发相关工作。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









