








大家好,今天要和大家聊一个相当炸裂的新模型 —— 阿里通义智问团队刚刚发布的QwenLong-L1。这个模型有多厉害?32B参数量就能干翻OpenAI o3-mini,和Claude-3.5-Sonnet平起平坐,关键还开源的!
https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B
这到底解决了什么痛点?
说到长文本推理,大家可能都有过这样的体验:给AI喂一个超长的文档,让它回答问题,结果它要么答非所问,要么直接"短路"了。
现在的大型推理模型(LRM)在短文本上表现挺不错的,但一遇到长文本就容易"翻车"。为什么?因为长文本推理不只是简单的信息检索,还需要:
- 跨文档的多跳推理 - 从A文档找线索,跳到B文档验证,再回到C文档得出结论
- 复杂的信息整合 - 把散落在长文本各处的信息拼接成完整的推理链
- 稳定的注意力机制 - 在几万个token中保持专注,不被无关信息干扰
之前的模型要么推理能力强但处理不了长文本,要么能读长文本但推理跟不上。QwenLong-L1就是来解决这个"鱼和熊掌"问题的。
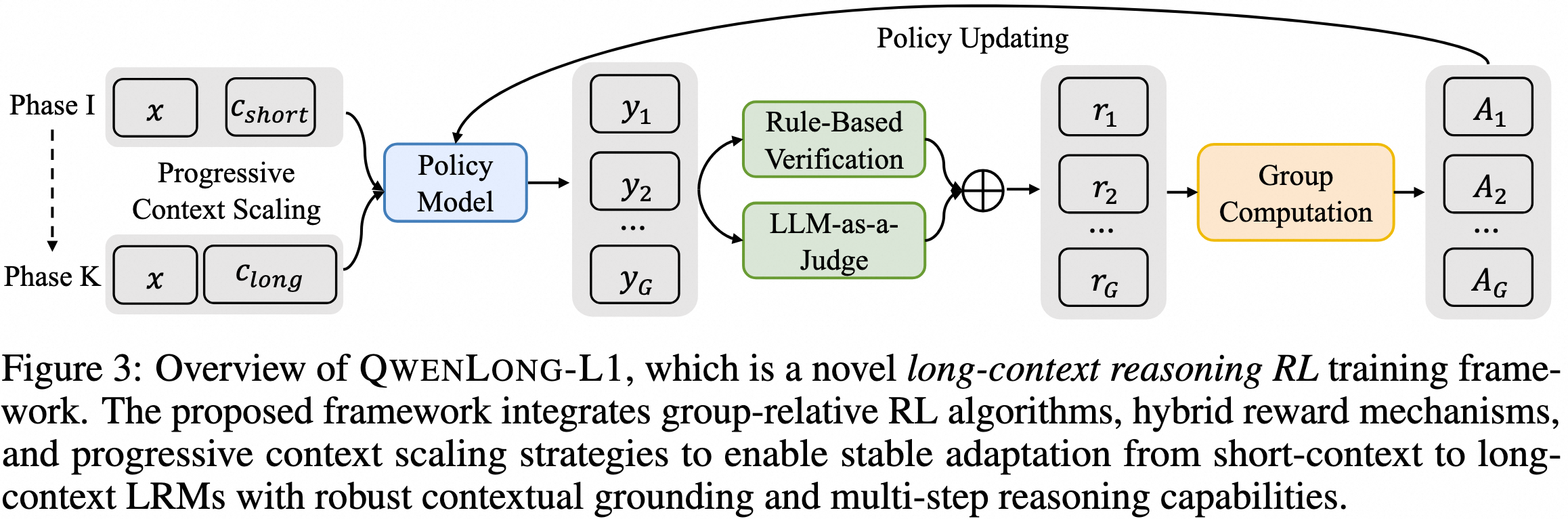
QwenLong-L1的三大杀手锏
1. 热身式监督微调(Warm-up SFT)
就像运动员赛前热身一样,QwenLong-L1在正式强化学习训练前,先用5.3K个高质量的问题-文档-答案三元组进行预热。这一步很关键,给后续的强化学习训练提供了稳定的起点。
不然的话,直接上强化学习就像让一个没练过基本功的人直接参加比赛,容易"翻车"。
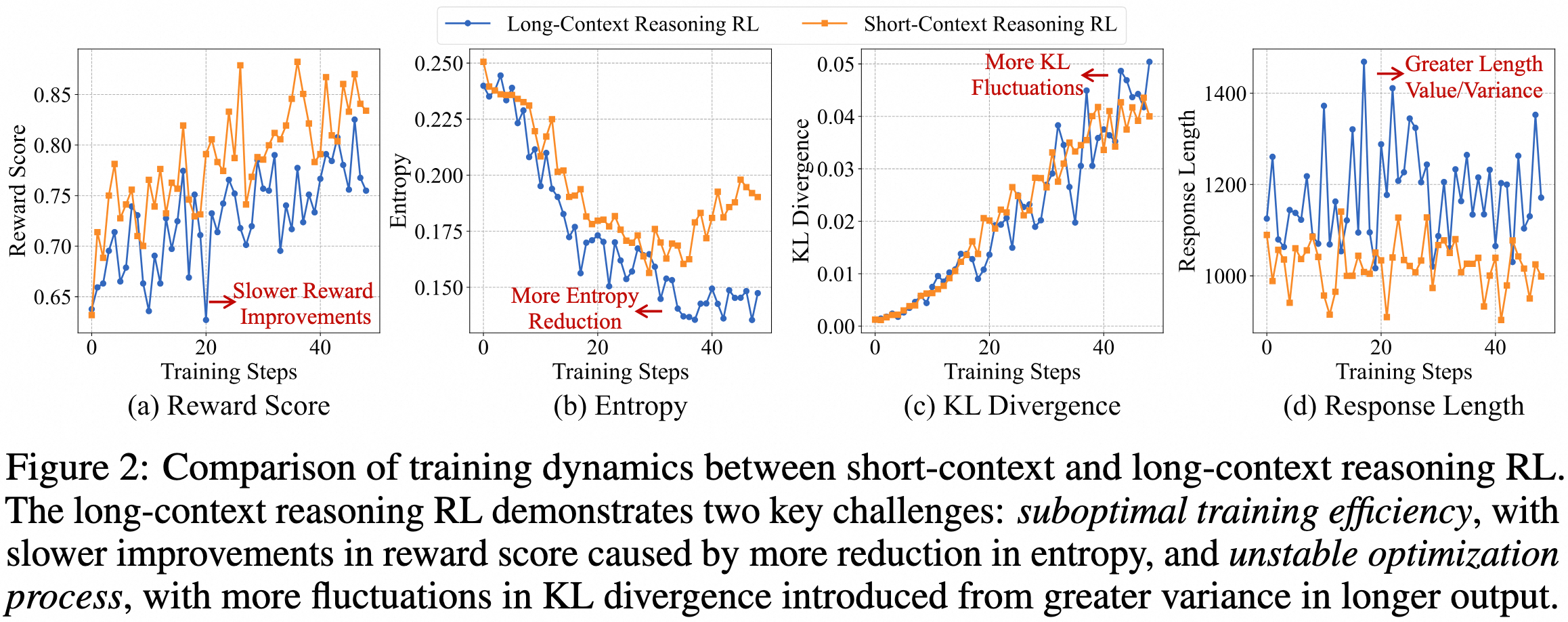
2. 课程式分阶段强化学习
这是最核心的创新。传统方法是一次性让模型处理超长文本,就像让小学生直接做高考题。
QwenLong-L1采用了更聪明的策略:
- 第一阶段:处理20K长度的文本,让模型先适应中等长度
- 第二阶段:扩展到60K长度,逐步挑战更长的文本
这种渐进式训练大大提高了训练的稳定性,避免了直接处理超长文本时的优化困难。
3. 难度感知的回顾性采样
听起来很高大上,其实原理很朴素:专门挑难题来练。
系统会计算每个样本的难度分数,优先选择那些模型答错或者答得不够好的例子进行重点训练。就像老师会针对学生的薄弱环节重点辅导一样。
实验效果有多炸?
笔者看到这个实验结果,真的是眼前一亮:
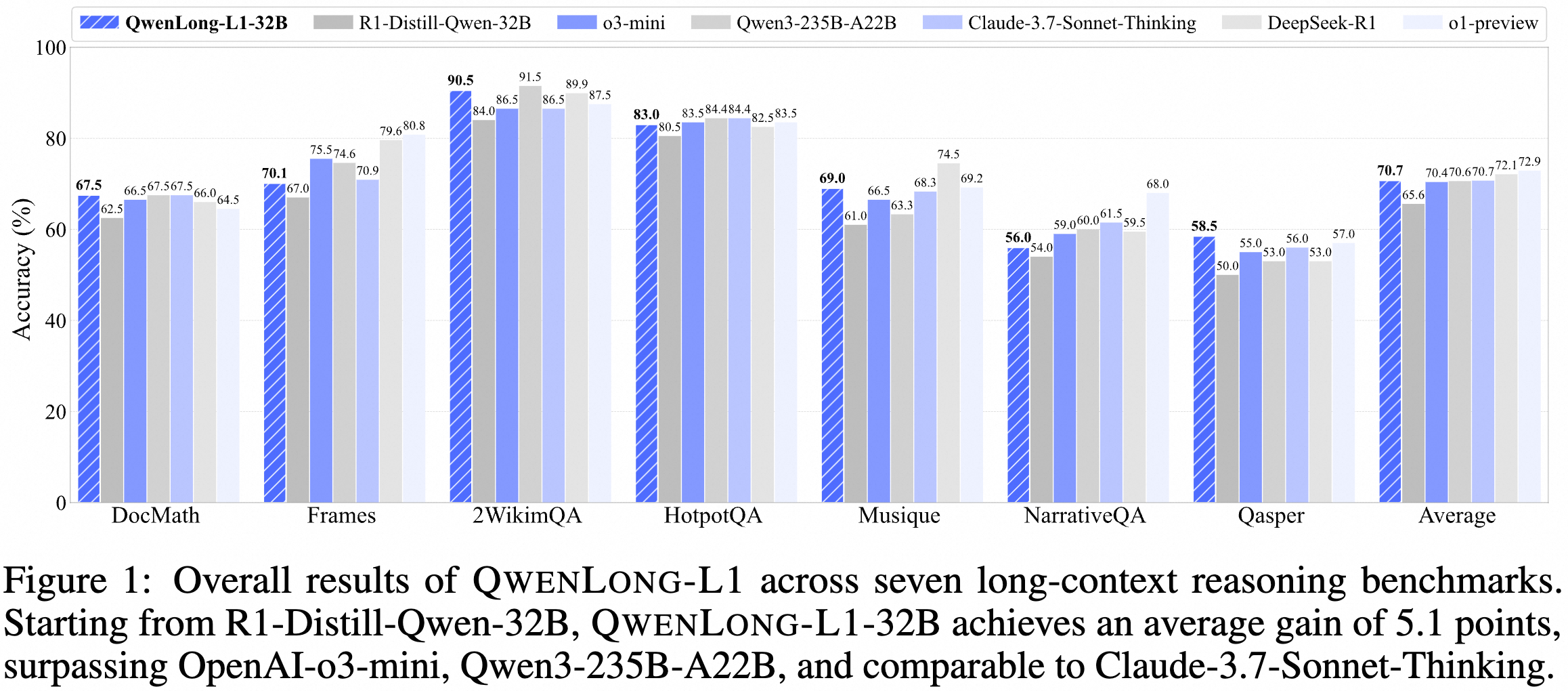
主要对比结果
- QwenLong-L1-32B:平均分70.7,超越了一众大佬
- 吊打OpenAI o3-mini
- 碾压Qwen3-235B-A22B(注意这可是235B参数的模型!)
- 和Claude-3.5-Sonnet-Thinking打成平手
参数效率惊人
最让人震惊的是参数效率。32B的QwenLong-L1干翻了235B的Qwen3,这意味着什么?
- 算力需求大幅降低:部署成本直接砍掉80%+
- 推理速度更快:小模型天然的速度优势
- 能耗更环保:绿色AI的典型代表
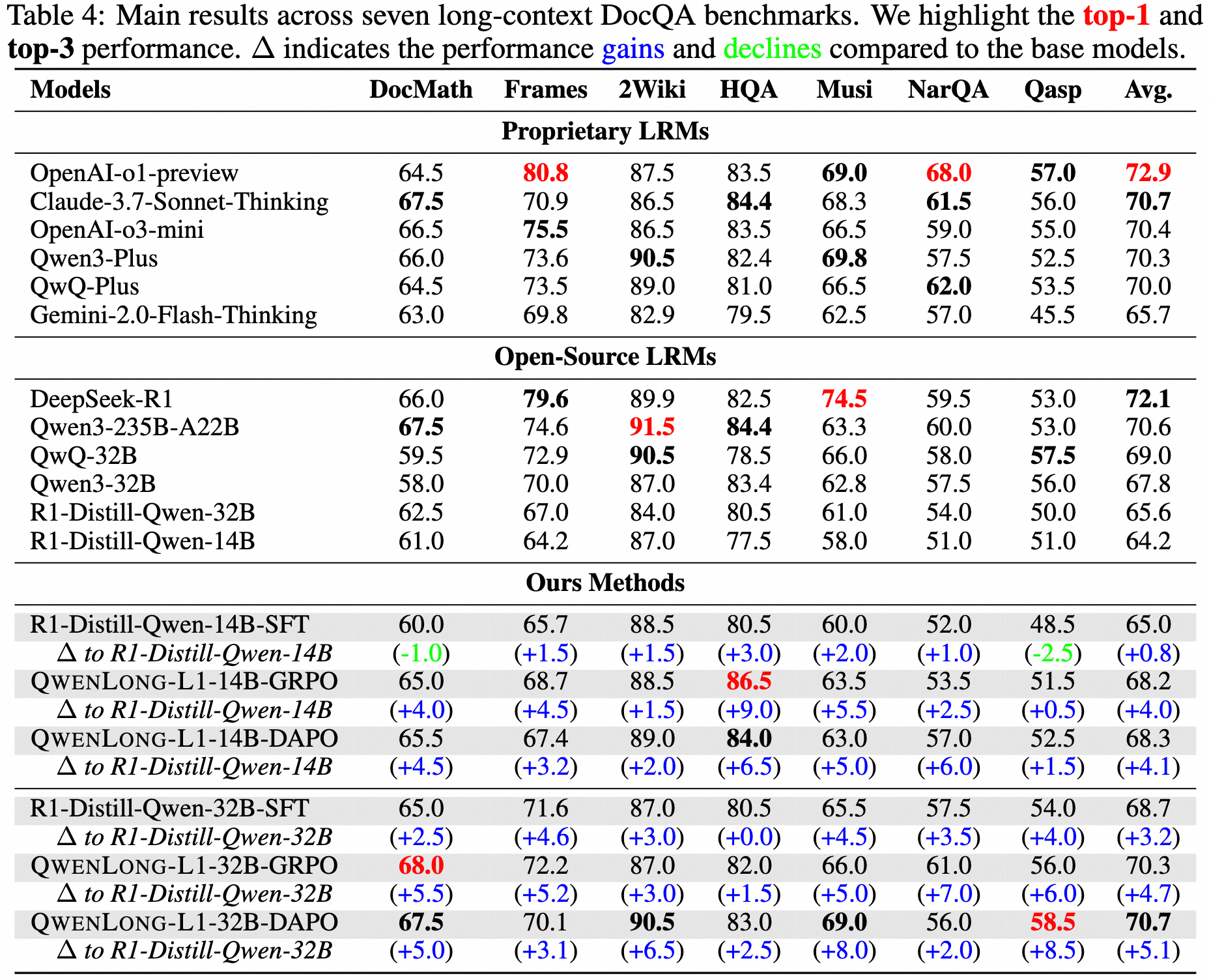
多项基准测试全面领先
在七个长文本问答基准上的表现:
- 2WikiMultihopQA:多跳推理能力优秀
- HotpotQA:热点问题推理表现出色
- Musique:音乐领域专业推理
- NarrativeQA:叙事文本理解能力强
- Qasper:学术论文问答准确
- Frames:框架性思维推理
- DocMath:数学文档推理能力突出
技术细节:混合奖励机制
QwenLong-L1还有一个巧妙的设计 —— 混合奖励机制。
传统的评估要么过于严格(必须字字相符),要么过于宽松(语义相近就行)。QwenLong-L1结合了两种方式:
- 规则验证:确保关键答案的准确性
- LLM评估:判断语义等价性
- 取最大值:兼顾精确性和召回率
这就像考试既看标准答案,也看答题思路,只要有一个维度达标就给分。


















 37
37

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









