







- Mean Shift简介
- 白话版
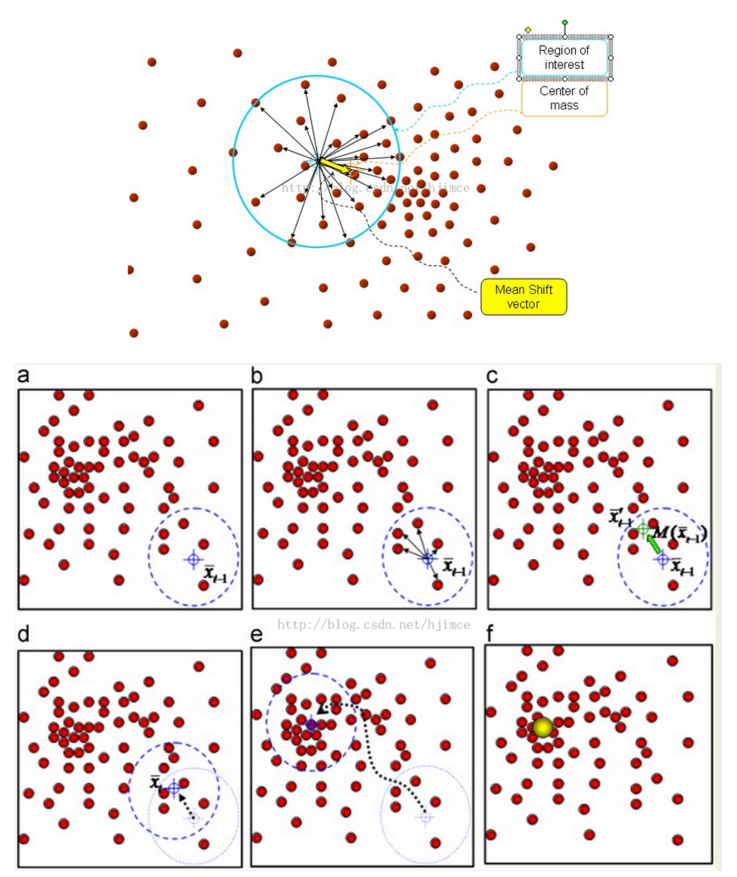
MeanShift算法可以看作是使多个随机中心点向着密度最大的方向移动,最终得到多个最大密度中心。
可以看成初始有多个随机初始中心,每个中心都有一个半径为bandwidth的圆,我们要做的就是求解一个向量,使得圆心一直往数据集密度最大的方向移动,也就是每次迭代的时候,都是找到圆里面点的平均位置作为新的圆心位置,直到满足某个条件不再迭代,这时候的圆心也就是密度中心。
—————————————————————————————————- - 学术版
Mean Shift算法是一种无参密度估计算法或称核密度估计算法,可用于聚类、图像分割、跟踪等,Mean shift是一个向量,它的方向指向当前点上概率密度梯度的方向。
所谓的核密度评估算法,指的是根据数据概率密度不断移动其均值质心(也就是算法的名称Mean Shift的含义)直到满足一定条件。
迭代过程如下:
- 白话版
- meansshift聚类
对多维数据集进行MeanShift聚类过程如下:
- 在未被标记的数据点中随机选择一个点作为中心center;
- 找出离center距离在bandwidth之内的所有点,记做集合M,认为这些点属于簇c。同时,把这些求内点属于这个类的概率加1,这个参数将用于最后步骤的分类
- 以center为中心点&#x
 Mean Shift是一种无参密度估计算法,用于聚类和图像分割。算法通过寻找数据集密度最大的方向移动,不断更新中心点,直至收敛。在聚类过程中,随机选择初始点,计算其周围点的平均位置作为新中心,重复此过程直到满足停止条件。最终形成高密度区域作为聚类中心。
Mean Shift是一种无参密度估计算法,用于聚类和图像分割。算法通过寻找数据集密度最大的方向移动,不断更新中心点,直至收敛。在聚类过程中,随机选择初始点,计算其周围点的平均位置作为新中心,重复此过程直到满足停止条件。最终形成高密度区域作为聚类中心。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8323
8323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









