







本章主要介绍了决策树的相关内容,包含复杂度的计算,基尼不纯度或信息熵,正则化超参数等内容,做简单总结,详细内容查看 链接
CART训练算法
Scikit-Learn 用分裂回归树(Classification And Regression Tree,简称 CART)算法训练决策树(也叫“增长树”)。
首先使用单个特征k和阈值tk将训练集分为两个子集。如何选择k和tk呢?它寻找到能够产生最纯粹的子集一对(k,tk),然后通过子集大小加权计算。
算法会尝试最小化成本函数,
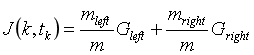
其中,G用来评价左右子集的纯度,m是左右子集的样本数。
当它成功的将训练集分成两部分之后, 它将会继续使用相同的递归式逻辑继续的分割子集,然后是子集的子集。当达到预定的最大深度之后将会停止分裂(由max_depth超参数决定),或者是它找不到可以继续降低不纯度的分裂方法的时候。
计算复杂度
在建立好决策树模型后, 做出预测需要遍历决策树, 从根节点一直到叶节点。决策树通常近似左右平衡,因此遍历决策树需要经历大致O(log2m)个节点。由于每个节点只需要检查一个特征的值,因此总体预测复杂度仅为O(log2m),与特征的数量无关。 所以即使在处理大型训练集时,预测速度也非常快。
然而,训练算法的时候(训练和预测不同)需要比较所有特征(如果设置了max_features会更少一些).
在每个节点的所有样本上。就有了O(nmlog2m)的训练复杂度。对于小型训练集(少于几千例),Scikit-Learn 可以通过预先设置数据(presort = True)来加速训练,但是这对于较大训练集来说会显着减慢训练速度。
基尼不纯度或信息熵
在机器学习中,熵经常被用作不纯度的衡量方式,当一个集合内只包含一类实例时, 我们称为数据集的熵为 0。
公式 6-3 显示了第i个节点的熵的定义,
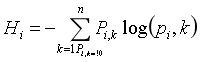
那么我们到底应该使用 Gini 指数还是熵呢? 事实上大部分情况都没有多大的差别:他们会生成类似的决策树。
基尼指数计算稍微快一点,所以这是一个很好的默认值。但是,也有的时候它们会产生不同的树,基尼指数会趋于在树的分支中将最多的类隔离出来,而熵指数趋向于产生略微平衡一些的决策树模型。
正则化超参数
如果不添加约束,树结构模型通常将根据训练数据调整自己,使自身能够很好的拟合数据,而这种情况下大多数会导致模型过拟合。
这一类的模型通常会被称为非参数模型,这不是因为它没有任何参数(通常也有很多),而是因为在训练之前没有确定参数的具体数量,所以模型结构可以根据数据的特性自由生长。
DecisionTreeClassifier类还有一些其他的参数用于限制树模型的形状:
min_samples_split(节点在被分裂之前必须具有的最小样本数),
min_samples_leaf(叶节点必须具有的最小样本数),
min_weight_fraction_leaf(和min_samples_leaf相同,但表示为加权总数的一小部分实例),
max_leaf_nodes(叶节点的最大数量)
max_features(在每个节点被评估是否分裂的时候,具有的最大特征数量)。
增加min_* hyperparameters或者减少max_* hyperparameters会使模型正则化。
回归
决策树也能够执行回归任务,使用 Scikit-Learn 的DecisionTreeRegressor类可以构建一个回归树。
CART 回归算法的工作方式与之前处理分类模型基本一样,不同之处在于,现在不再以最小化不纯度的方式分割训练集,而是试图以最小化 MSE 的方式分割训练集。
公式 6-4 显示了成本函数,该算法试图最小化这个成本函数。
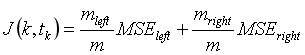
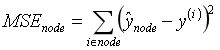
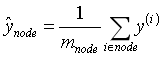

不稳定性
它很容易理解和解释,易于使用且功能丰富而强大。然而,它也有一些限制,首先,你可能已经注意到了,决策树很喜欢设定正交化的决策边界,(所有边界都是和某一个轴相垂直的),这使得它对训练数据集的旋转很敏感,例如图 6-7 显示了一个简单的线性可分数据集。在左图中,决策树可以轻易的将数据分隔开,但是在右图中,当我们把数据旋转了 45° 之后,决策树的边界看起来变的格外复杂。尽管两个决策树都完美的拟合了训练数据,右边模型的泛化能力很可能非常差。
解决这个难题的一种方式是使用 PCA 主成分分析(第八章),这样通常能使训练结果变得更好一些。

练习
- 在 100 万例训练集上训练(没有限制)的决策树的近似深度是多少?
决策数在训练时通常会近似左右平衡,训练没有限制,每个训练实例都会有一个叶子节点。因此100万例训练集的近似深度为log2(10^6)=21。实际上可能多一点,因为决策树一般不会很好的平衡。决策数在训练时通常会近似左右平衡,训练没有限制,每个训练实例都会有一个叶子节点。因此100万例训练集的近似深度为log2(10^6)=21。实际上可能多一点,因为决策树一般不会很好的平衡。 - 节点的基尼指数比起它的父节点是更高还是更低?它是通常情况下更高/更低,还是永远更高/更低?
节点的基尼指数通常低于父节点,这是通过CART训练算法的成本函数来确保的,该算法将每个节点分开,以最小化其子节点Gini杂质的加权和。 但是,如果一个孩子比另一个孩子小,它可能比其父节点具有更高的基尼杂质,只要这种增加超过其他孩子基尼指数的减少即可弥补。 - 如果决策树过拟合了,减少最大深度是一个好的方法吗?
如果决策树过拟合训练集,减少max_depth可能是个好主意,因为这会约束模型,使其正则化。 - 如果决策树对训练集欠拟合了,尝试缩放输入特征是否是一个好主意?
决策树不关心训练数据是否按比例缩放或居中,因此,如果决策树欠拟合训练集,缩放输入特征只会浪费时间。 - 如果对包含 100 万个实例的数据集训练决策树模型需要一个小时,在包含 1000 万个实例的培训集上训练另一个决策树大概需要多少时间呢?
训练决策树的计算复杂度是O(nmlog(m)),因此,如果将训练集大小乘以10,则训练时间将乘以K=n×10mlog(10m)/(nmlog(m))=10log(10m)/log(m) M=10^6,则K=11.7,因此你可以预期训练时间大约为11.7小时 - 如果你的训练集包含 100,000 个实例,设置presort=True会加快训练的速度吗?
仅当数据集小于几千个实例时,预先训练训练集才能加速训练。 如果它包含100,000个实例,则设置presort = True将大大减慢训练速度。















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









