







drop、truncate和delete的区别
- 从速度上来说,drop> truncate(截短) > delete。
- 从表和索引所占空间来说
- 表被truncate 后,这个表和索引所占用的空间会恢复到初始大小,
- delete操作不会减少表或索引所占用的空间。
- drop语句将表所占用的空间全释放掉。
- 从应用范围来说
- drop 可以针对数据库和table
- truncate 只能对table
- delete可以是table和view
- delete语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。 truncate table则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器,执行速度快。
having与where的区别
聚合函数与分组group by是比较where、having 的关键。
- 若引入聚合函数来对group by 结果进行过滤(对分组过滤)则只能用having。而where只过滤行。
分页语句Limit用法
- limit的用法
mysql> SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
mysql> SELECT * FROM table LIMIT 5; //检索前 5 个记录行
- 分页查询
//在中小数据量的情况下,使用最简单的sql就可以,需要注意的问题是确保使用了索引,如果实际SQL类似下面语句,那么在category_id, id两列上建立复合索引比较好
SELECT * FROM articles WHERE category_id = 123 ORDER BY id LIMIT 50, 10
//随着数据量的增加,页数会越来越多,查看后几页的SQL就可能类似:
SELECT * FROM articles WHERE category_id = 123 ORDER BY id LIMIT 10000, 10
//一言以蔽之,就是越往后分页,LIMIT语句的偏移量就会越大,速度也会明显变慢。此时,我们可以通过子查询的方式来提高分页效率,大致如下:
SELECT * FROM articles WHERE category_id = 123 AND id >=
(SELECT id FROM articles WHERE category_id = 123 ORDER BY id LIMIT 10000, 1) LIMIT 10
或
SELECT a.* FROM articles a,
(select id from articles where category_id = 123 LIMIT 100000,20 ) b where a.id=b.id
好文连接:https://www.cnblogs.com/youyoui/p/7851007.html
- 为什么使用子查询快?因为子查询是在索引上完成的,而普通的查询是在数据文件上完成的,通常来说,索引文件要比数据文件小得多,所以操作起来也会更有效率。实际可以利用类似策略模式的方式去处理分页,比如判断如果是一百页以内,就使用最基本的分页方式,大于一百页,则使用子查询的分页方式。
联表查询方式
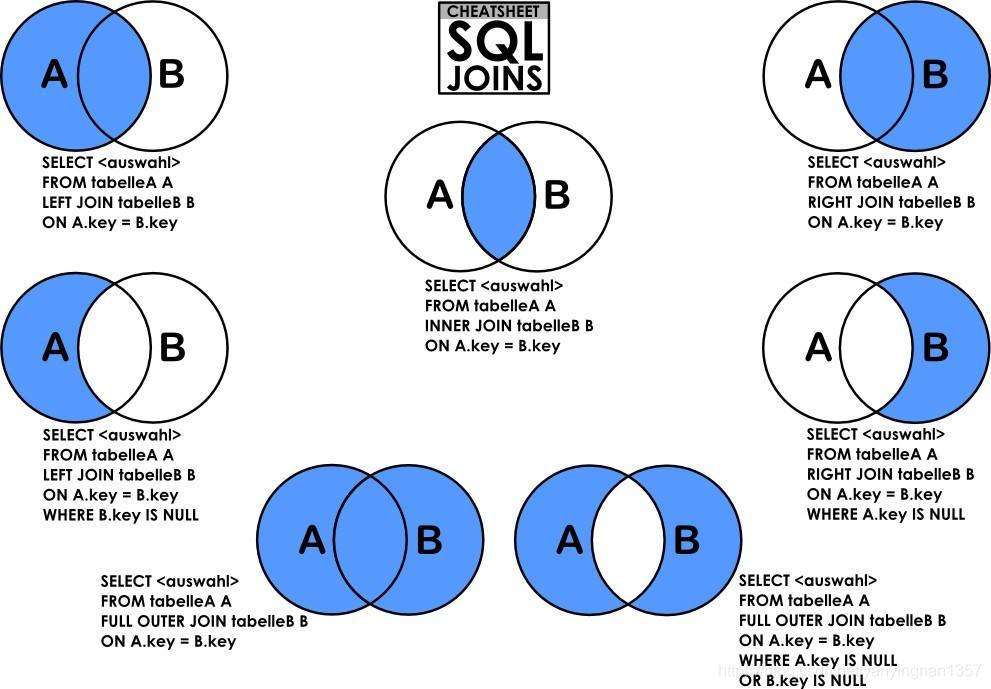
查询例子:
------右联结例子------
select distinct fang.org_code as entity_id,
'uc_org_code_not8' as type,
${-1d_yyyyMMdd} as day FROM
(select distinct org_level8_code from dw.dw_hr_org_da where pt='${-1d_pt}') uc
right join
(select distinct org_code from ods.ods_myth_division_org_resblock_score_da where pt='${-1d_pt}') fang
on uc.org_level8_code = fang.org_code
where uc.org_level8_code is null
------三表查询例子------
select distinct concat(fang.org_code, '+', fang.resblock_id) as entity_id,
'div_is_real_maintain' as type,
${-1d_yyyyMMdd} as day FROM
(select distinct org_code, resblock_id from ods.ods_group_build where pt='${-1d_pt}' and div_type = '101000000002'
union
select distinct org_code, resblock_id from ods.ods_alliance_division_group_div_da where pt='${-1d_pt}' and div_type = 1) division
inner join
(select distinct org_code, resblock_id from ods.ods_myth_division_org_resblock_score_da where pt='${-1d_pt}' and is_real_maintain = 1) fang
on division.org_code = fang.org_code and division.resblock_id = fang.resblock_id
where division.org_code = null
------三表联结+group by用法------
select distinct concat(myth.org_code, '+', myth.resblock_id) as entity_id,
'housedel_num' as type,
${-1d_yyyyMMdd} as day FROM
(select distinct org_code, resblock_id, housedel_num from ods.ods_myth_division_org_resblock_score_da where pt='${-1d_pt}') myth
inner join
(select role.org_code, dele.resblock_id, count(*) as housedel_num from
(select housedel_code, org_code from ods.ods_house_sh_housedel_role_da where pt='${-1d_pt}' and role_status = 1 and role_type = 2) role
inner join
(select housedel_code, resblock_id from ods.ods_house_sh_housedel_basic_da where pt='${-1d_pt}' and del_status in (1,100,1000)) dele
on role.housedel_code = dele.housedel_code and role.org_code != ''
group by role.org_code, dele.resblock_id) fang
on myth.org_code = fang.org_code and myth.resblock_id = fang.resblock_id
where myth.housedel_num != fang.housedel_num














 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









