







前言
方便自己后面需要搭建的时候看看笔记就可以
准备工作
[root@node01 spark]# pwd #老规矩把安装包放在/try下
/try/spark
[root@node01 spark]# ll
-rw-r--r--. 1 root root 224840600 Aug 7 04:12 spark-2.3.4-bin-hadoop2.6.tgz
机器分布
| node01 | node02 | node03 |
|---|---|---|
| spark-master | spark-slave | spark-slave |
| 手机 | $12 | $1600 |
| 导管 | $1 | $1600 |
环境变量
#在node01,node02,node03上都配置一下
export SPARK_HOME=/opt/bigdata/spark-2.3.4-bin-hadoop2.6
配置文件
- slaves 配置文件
#cp 配置文件
[root@node01 conf]# cp slaves.template slaves
#在最后一行添加两个从节点
node02
node03
- spark-env.sh 配置环境变量
#cp 配置文件
[root@node01 conf]# cp spark-env.sh.template spark-env.sh
#在配置文件中配置如下6个参数
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoop
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
export SPARK_MASTER_HOST=node01
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
export SPARK_MASTER_PORT=7077
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
export SPARK_WORKER_CORES=4
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
export SPARK_WORKER_MEMORY=4g
- 将整包发送到node02,node03
scp -r ./spark-2.3.4-bin-hadoop2.6 node02:`pwd`
scp -r ./spark-2.3.4-bin-hadoop2.6 node03:`pwd`
启动/关闭
#启动 zookeeper
#启动 hdfs
#启动 spark
[root@node01 sbin]# start-all.sh
#停止 spark
[root@node01 sbin]# stop-all.sh
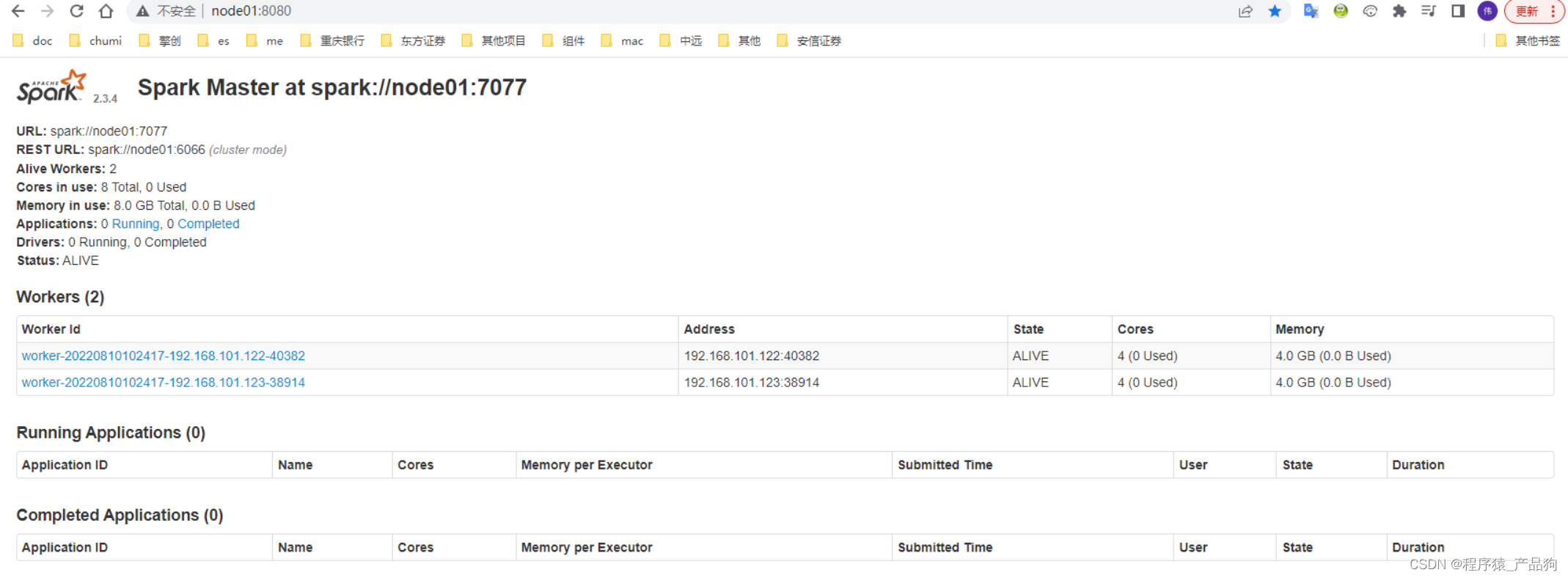
web ui
http://node01:8080/















 4604
4604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









