







前言
方便自己后面需要搭建的时候看看笔记就可以
准备工作
[root@node01 spark]# pwd #老规矩把安装包放在/try下
/try/hadoop
[root@node01 hadoop]# ll
-rw-r--r--. 1 root root 183594876 Aug 10 04:22 hadoop-2.6.5.tar.gz
机器分布
| node01 | node02 | node03 |
|---|---|---|
| NameNode | ||
| x | SecondaryNameNode | |
| x | DataNode | DataNode |
环境变量
#在node01,node02,node03上都配置一下
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
配置文件
各配置文件的左右可参考:https://blog.csdn.net/wjt199866/article/details/106473174
- slaves 配置文件
#cp 配置文件
[root@node01 conf]# cp slaves.template slaves
#在最后一行添加两个从节点
node02
node03
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9001</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/bigdata/hadoop/full/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/full/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/var/bigdata/hadoop/full/dfs/secondary</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50071</value>
</property>
</configuration>
- hadoop-env.sh
#配置java的位置,因为在远程执行shell的时候读不到环境变量
export JAVA_HOME=/usr/java/default
- 将整包发送到node02,node03
scp -r hadoop-2.6.5/ node02:`pwd`
scp -r hadoop-2.6.5/ node03:`pwd`
启动之前
启动/停止
#启动hdfs
start-dfs.sh
#停止hdfs
stop-dfs.sh
验证
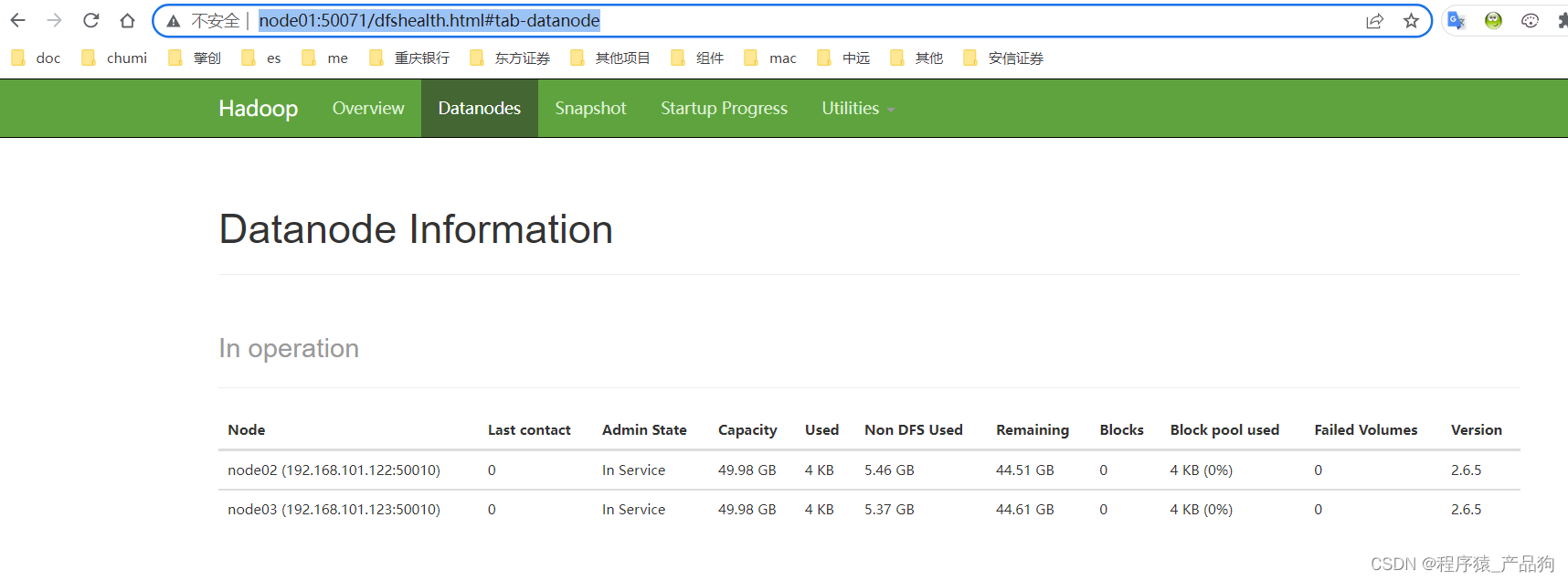
http://node01:50071/dfshealth.html#tab-datanode















 2953
2953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









